Lógica de equilibrio de carga en Cisco Meeting Server
Opciones de descarga
-
ePub (145.2 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (147.1 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
En este documento se describe la lógica de equilibrio de carga de Cisco Meeting Server (CMS) (anteriormente producto Acano), que se describe en el informe técnico Equilibrio de carga. Este documento visualiza este proceso en un diagrama de flujo y profundiza en el algoritmo de selección.
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas:
- componente Call Bridge de Cisco Meeting Server (y agrupación en clúster del mismo)
- Configuración de la API de Cisco Meeting Server
Componentes Utilizados
La información de este documento se basa en Cisco Meeting Server, versión 2.4.x.
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
¿Qué es el algoritmo de balanceo de carga del CMS?
El balanceo de carga se ha introducido en la versión 2.1 de CMS para hacer un uso eficiente de los recursos de conferencia. Intenta minimizar el número de llamadas de distribución entre los Call Bridges que alojan el mismo espacio. Este mecanismo se basa en el encabezado Reemplazos del protocolo de inicio de sesión (SIP) y es compatible con Cisco Unified Communications Manager (CUCM) como control de llamadas. También es compatible con Expressway versión X8.11 (o posterior), en combinación con CMS versión 2.4 o posterior. Las llamadas de CMA (tanto de cliente pesado como de tipo WebRTC) también se pueden equilibrar con la carga desde la versión 2.3 de CMS en adelante.
Nota: el equilibrio de carga de las llamadas de Lync/Skype no se admite en ninguna versión de CMS en este momento y, por lo tanto, este diagrama de flujo no se aplica.
Nota: La lógica de equilibrio de carga solo se aplica a las llamadas a espacios CMS y, por lo tanto, no a las llamadas de gateway (llamadas P2P) o a las llamadas de inicio dual en este momento.
El proceso de balanceo de carga se resalta en el informe técnico en la sección Cómo el balanceo de carga utiliza las configuraciones de Configuración de Call Bridges para el balanceo de carga de llamadas entrantes. Se muestra en formato de texto y se visualiza aquí en el diagrama de flujo (descargar ).
El diagrama de flujo utiliza algunas abreviaturas y terminología:
- CB = Call Bridge
- ExistingConferenceLoadLimit = existingConferenceLoadLimitBasisPoints * loadLimit
(de forma predeterminada, el valor de existingConferenceLoadLimitBasisPoints es 8000, que corresponde al 80%) - NewConferenceLoadLimit = newConferenceLoadLimitBasisPoints * loadLimit
(de forma predeterminada, el valor de newConferenceLoadLimitBasisPoints es 5000, que corresponde al 50%)
Si se hace referencia a MediaProcessingLoad, se observa en relación con ese Call Bridge concreto en el que ha aterrizado la llamada. Este valor de carga se puede verificar con una API GET en /system/load en tiempo real y da una representación de la carga real procesada por este Call Bridge en ese momento.
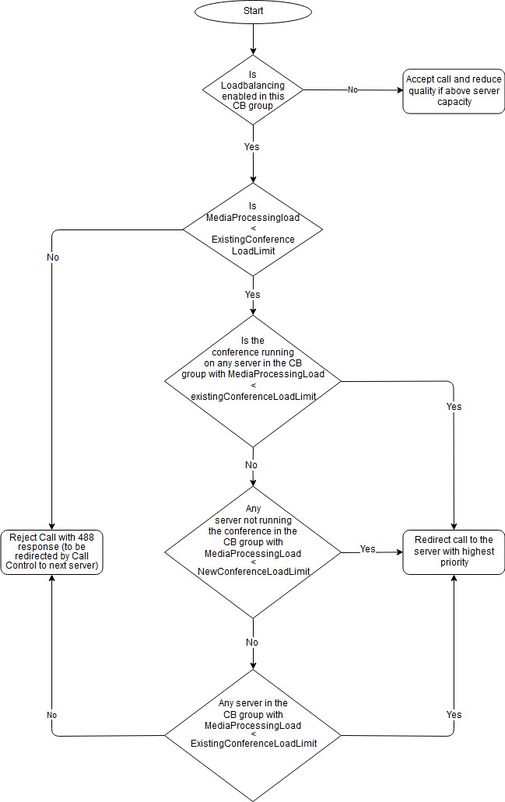
Si finaliza la llamada en el cuadro situado más abajo a la derecha, ésta se redirigirá al servidor de mayor prioridad. Puede ser el propio servidor de Call Bridge u otro servidor dentro del grupo de Call Bridge en el que la llamada ha aterrizado. En caso de que no se tome una decisión basada en la carga y si el espacio ya está activo en un Call Bridge, existe un vínculo con varios Call Bridges. En ese caso, la decisión final se toma en función de la preferencia predeterminada de Call Bridge que se asigna a cada espacio. Esta preferencia de Call Bridge se asigna en la creación del espacio automáticamente y no se puede configurar, ya que se basa en los valores hash de varios atributos. Esto da como resultado una distribución uniforme (aleatoria) para diferentes espacios en todos los Call Bridges.
Para ver la preferencia de Call Bridge para un espacio determinado, debería verificar esto en el registro de eventos de CMS, como se muestra en estos ejemplos.
Ejemplos del Algoritmo de Balanceo de Carga
Esta sección contiene ejemplos de escenarios posibles y cómo el registro de eventos del CMS donde aterrizó la llamada muestra el proceso de balanceo de carga como se describe en el diagrama de flujo.
Para estos ejemplos, se utilizó una configuración de laboratorio con un grupo de Call Bridge de tres Call Bridges. Las configuraciones existingConferenceLoadLimitBasisPoints y newConferenceLoadLimitBasisPoints se establecieron en sus valores predeterminados correspondientes al 80% y el 50%, respectivamente, del valor de loadLimit.
Para verificar el MediaProcessingLoad actual en un Call Bridge determinado, puede navegar a https://<ip-or-fqdn-of-callbridge>:<webadmin-port>/api/v1/system/load e iniciar sesión con una API o una cuenta de administrador como se muestra en la imagen.
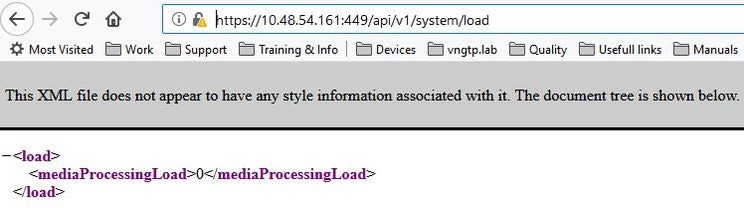
Ejemplo 1: Sin carga en cualquier Call Bridge
En este ejemplo, no hay llamadas activas en ninguno de los Call Bridges. Por lo tanto, MediaProcessingLoad de todos los servidores es igual a cero.
Cuando realiza una llamada a uno de los Call Bridges (cluster1 aquí) (con el equilibrio de carga habilitado tanto en el CMS como en los dispositivos de control de llamadas), puede ver el registro de eventos en el Call Bridge donde aterrizó la llamada:
2018-12-29 10:51:29.490 Info call 75: incoming SIP call from "sip:1060@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 10:51:29.565 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 10:51:29.712 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replacing call 'f8eeea46e0f0790a@10.10.50.13' to conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 on server 'cluster3' 2018-12-29 10:51:29.876 Info call 75: ending; remote SIP cancel (remote cancel) - not connected after 0:00
en la cual puede ver las líneas de consulta de reemplazo para cada uno de los Call Bridges en su Call Bridge Group que nos muestran el algoritmo de balanceo de carga que se divide en tres secciones:
- priority - la preferencia Call Bridge de ese espacio
- load level - el nivel de carga de ese Call Bridge en ese momento
- conferencia en ejecución: booleano indica si el espacio está activo en ese Call Bridge
Como no se ha realizado ninguna llamada en ese momento en el sistema, no hay carga en ninguno de los sistemas (todos 0) y la conferencia no se está ejecutando en ningún lugar (todos 0). A este respecto, la decisión final se toma en función de la preferencia Call Bridge del espacio. Se prefiere una prioridad más baja y, por lo tanto, la llamada se reemplaza aquí a Call Bridge con el nombre cluster3 tal como se ve en la línea de llamada de reemplazo.
En Call Bridge cluster3, puede ver las líneas del registro de eventos que indican esta llamada de reemplazo (así como de qué Call Bridge proviene (cluster1 aquí) y el mismo ID de conferencia e ID de llamada):
2018-12-29 10:51:29.784 Info replacing call 'f8eeea46e0f0790a@10.10.50.13' from server 'cluster1' into conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 2018-12-29 10:51:29.787 Info call 193: outgoing SIP call to "1060@steven.lab" from space "Steven Janssens's space" 2018-12-29 10:51:29.792 Info call 193: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 10:51:29.909 Info call 193: compensating for far end not matching payload types 2018-12-29 10:51:29.911 Info participant "1060@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
En caso de que la llamada ya haya aterrizado en el Call Bridge con el valor de prioridad más bajo (cluster3 aquí para este espacio), aún puede ver las mismas líneas de consulta de reemplazo en el registro de eventos, pero indica ahora que utiliza el servidor local y que no hay ninguna línea de llamada de reemplazo:
2018-12-29 11:05:25.202 Info call 194: incoming SIP call from "sip:1060@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 11:05:25.233 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 11:05:25.376 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 11:05:25.378 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 11:05:25.378 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 11:05:25.380 Info call 194: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 11:05:25.404 Info participant "1060@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Ejemplo 2: Ya hay participantes en el espacio del grupo de Call Bridge
En este ejemplo, el espacio ya está activo dentro del grupo de Call Bridge como punto final 1060@steven.lab llamado al espacio como se muestra en el ejemplo 1.
Hay dos situaciones en este caso:
1. El Call Bridge que aloja este espacio tiene una carga inferior al umbral de conferencia existente y, por lo tanto, puede aceptar la llamada.
2. El Call Bridge que aloja este espacio tiene una carga superior al umbral de conferencia existente y, por lo tanto, CMS intenta reemplazar la llamada a otro Call Bridge.
Escenario 1. Espacio activo y carga inferior al umbral de conferencia existente (80%)
En caso de que la llamada aterrizara en un Call Bridge donde el espacio aún no estaba activo, el registro de eventos muestra ahora que el espacio está activo en Call Bridge con el nombre cluster3. Como el espacio está activo allí y la carga en ese servidor es inferior al umbral existente (nivel de carga: 0), la llamada se reemplaza.
2018-12-29 11:48:17.419 Info call 82: incoming SIP call from "sip:800999@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 11:48:17.477 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 1) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster3' (priority: 0, load level: 0, conference is running: 1) 2018-12-29 11:48:17.607 Info replacing call '4c28197eaebba178@10.10.2.250' to conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 on server 'cluster3'
La conferencia que se está ejecutando tiene preferencia a la prioridad en primer lugar, por lo que si hubiera habido varios candidatos con un nivel de carga por debajo del umbral de conferencia existente, se reduciría a la preferencia Call Bridge según el valor de prioridad. Sin embargo, no es así en este caso.
Situación hipotética 2. Espacio activo y carga superior al umbral de conferencia existente (80%)
En este caso, la llamada no se reemplaza por ese Call Bridge, sino que busca otro Call Bridge dentro del grupo que aún tenga algunos recursos disponibles. En primer lugar, comprueba si hay Call Bridges con una carga inferior al 50% (nuevo umbral de conferencia) y carga primero esos. Si no hay ninguno por debajo de este umbral, comprueba si todavía hay disponibles menos del 80% (umbral de conferencia existente).
Si la carga en el clúster 3 de Call Bridge se verifica después de las llamadas de los ejemplos 1 y 2 (escenario 1), muestra una carga de 2000.
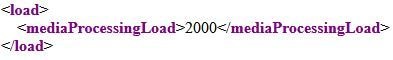
Suponga que el loadLimit para ese clúster de Call Bridge3 se estableció en 2250 (solo como ejemplo), entonces este Call Bridge está por encima del umbral de conferencia existente ya que se calcula como 0.80 * 2250 = 1800
Aún quedan dos casos por diferenciar en este escenario.
Caso 1: varios servidores del grupo con una carga inferior al nuevo umbral de conferencia (50%)
Los otros dos servidores en el grupo no tienen ninguna llamada manejada todavía, por lo que la carga sigue en 0 y por lo tanto ambos podrían manejar la llamada. Por lo tanto, la decisión final se toma en función de la preferencia de Call Bridge para este espacio. Como Call Bridge cluster3 ya está lleno, los sistemas eligen la prioridad más baja de cluster1 y cluster2 que es cluster1 en este caso.
2018-12-29 12:11:03.211 Info call 86: incoming encrypted SIP audio call from "sip:2001@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 12:11:03.263 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 12:11:03.405 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 12:11:03.412 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:11:03.412 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 12:11:03.415 Info call 86: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 12:11:03.434 Info participant "2001@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Observe que el nivel de carga: 2 en el clúster3 Call Bridge indica que se excedió el umbral de conferencia existente, por lo que aunque el espacio estaba activo allí, la llamada no se carga balanceada en ese servidor. En su lugar, observa la prioridad de espacio más baja de los otros Call Bridges con un nivel de carga: 0 (lo que significa un uso inferior al 50%), que es cluster1 en este caso.
Caso 2: solo un servidor en un grupo con una carga inferior al nuevo umbral de conferencia (50%) o al existente (80%)
Después de la última llamada (y de las llamadas a otro espacio al cluster2), se observaron las cargas descritas en los Call Bridges:
- clúster 1 - 1200
- clúster 2 - 400
- clúster 3 - 4000
Suponga ahora que el loadLimit establecido en el cluster1 Call Bridge sería 1300, entonces este Call Bridge está por encima del nuevo umbral de conferencia ya que se calcula como 0.50 * 1300 = 650 así como por encima del umbral de conferencia existente de 0.80 * 1300 = 1040.
En caso de que una nueva llamada WebRTC se reciba ahora en el clúster 3 de Call Bridge para ese mismo espacio, el espacio está activo tanto en el clúster 1 como en el clúster 3, pero ambos superan el umbral de conferencia existente y, por lo tanto, busca otro servidor por debajo del nuevo umbral de conferencia (50%) o del umbral de conferencia existente (80%). En este caso, solo el clúster 2 estaría por debajo del umbral de conferencia existente, pero ya está por encima del nuevo umbral de conferencia debido a otra llamada a otro espacio manejado en el puente de llamadas del clúster 2.
2018-12-29 12:45:33.162 Info instantiating user "guest1685904798@cluster.steven.lab" 2018-12-29 12:45:33.162 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 2, conference is running: 1) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster2' (priority: 2, load level: 1, conference is running: 0)
Cluster2 ha sido configurado con un valor loadLimit de 600 aquí. Con 400 como carga actual antes de que se recibiera la nueva llamada, se ha superado el nuevo umbral de conferencia de 0,5 * 600 = 300, pero sigue estando por debajo del límite de conferencia existente de 0,8 * 600 = 480. Por lo tanto, esto aparece en la consulta de reemplazo como nivel de carga: 1 (en lugar de 2 cuando el Call Bridge está por encima del umbral del 80%).
Ejemplo 3: Aterrizaje de llamada en Call Bridge por encima del umbral de conferencia existente
En este caso, el algoritmo de balanceo de carga no tiene lugar, ya que sería mejor enviar una respuesta 488 al dispositivo de control de llamadas que luego puede decidir intentar rutear la llamada a un Call Bridge diferente dentro del grupo (que puede estar por debajo del límite del 80%) o incluso rutearla a un grupo de Call Bridge diferente si el grupo actual está sin recursos (como una opción alternativa).
El registro de eventos no muestra esta parte de forma explícita con mucho detalle, ya que solo informa de que sobrepasó la capacidad:
2018-12-29 12:49:13.352 Info call 88: incoming encrypted SIP call from "sip:2020@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 12:49:13.399 Info call 88: ending; local teardown, system participant limit reached - not connected after 0:00
Una vez que la llamada se envía a un Call Bridge diferente que puede manejar la carga (cluster2 por ejemplo), se muestra el mismo algoritmo de balanceo de carga:
2018-12-29 12:49:13.434 Info call 624: incoming encrypted SIP call from "sip:2020@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab"
2018-12-29 12:49:13.475 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:49:13.614 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:49:13.614 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:49:13.618 Info call 624: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 12:49:13.621 Info call 624: starting DTLS UDT media negotiation (as initiator) 2018-12-29 12:49:13.640 Info participant "2020@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Nota: En el caso de las llamadas de gateway, el CMS devuelve un mensaje de error SIP 486 en su lugar. De forma predeterminada, CUCM detiene el enrutamiento según el parámetro de servicio de Detener enrutamiento en el indicador de usuario ocupado, por lo que es recomendable cambiar esta configuración para permitir la reserva de las llamadas de puerta de enlace a los otros callbridges.
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
1.0 |
30-Apr-2019
|
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Steven JanssensCisco TAC Engineer
- Nart OmatCisco TAC Engineer
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)