Verifique la salud de un cluster del Analytics del Tetration
Opciones de descarga
-
ePub (705.7 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (510.6 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe cómo verificar la salud de un cluster del Analytics del Tetration.
Prerequisites
Requisitos
Cisco recomienda que tenga conocimiento sobre estos temas:
- Registro en un cluster
- Experiencia básica de la interfaz de usuario (UI)
Componentes Utilizados
La información que contiene este documento se basa en las siguientes versiones de software y hardware.
- Versión 2.2.1.x
- Cluster del Analytics del Tetration 39RU
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si la red está funcionando, asegúrese de haber comprendido el impacto que puede tener cualquier comando.
Antecedentes
Un cluster del Tetration consiste en los centenares de procesos (programas) que se ejecutan a través del [Vitual Machines] múltiple VM en los servidores múltiples UCS C220-M4. Varios servicios y características existen ayudar a monitorear las operaciones del cluster y a alertar al administrador cuando el cluster puede no estar completamente - funcional.
Este documento proporciona una vista qué marcar al verificar la salud del cluster. Mientras que el alcance de este documento incluye verificar la salud, si la acción se requiere para ayudar a dirigir qué aparece ser algo que no funciona correctamente, recoger una foto y abrir una caja con el Equipo del TAC del soporte de la solución del Tetration de Cisco.
Dos herramientas comunes usadas para verificar la salud del cluster son las páginas del estatus del cluster y del estatus del servicio que se cubren en este documento junto con un par de otras herramientas de sistema. Aunque las alertas críticas del correo electrónico del Bosun son a menudo una de las primeras indicaciones a un administrador que algo pueda ocurrir en el cluster, verificar la salud del cluster es típicamente la mejor hecha a través de las páginas del estatus del cluster y del estatus del servicio.
Mientras que las alertas del bosón proporcionan el Syslog como las capacidades, en algunas versiones del Tetration, algunas alertas críticas del Bosun se han accionado en un cluster normalmente de funcionamiento. Una búsqueda a través de la Herramienta de búsqueda del bug de cisco.com para el producto del Tetration con la palabra clave de métrica ayudará a identificar los posibles problemas para un específico métrico.
Cuándo marcar la salud del cluster:
Normalmente, el administrador del cluster no tendrá que marcar las funciones del cluster. Hay sin embargo ciertas épocas en que puede ser necesario. Algunos ejemplos se enumeran aquí:
- Cuando el usuario ve la conducta inesperada en la interfaz de usuario (UI). Esto en la parte se basa sobre el conocimiento y la experiencia del usuario de cómo el cluster debe funcionar pero algunos ejemplos se muestran en los parámetros operativos de esta visualización de la sección.
- Cuando se espera que un ciertos datos para ser considerado pero él no sean visualizados en el UI. Por ejemplo, datos de flujo de un software o de un agente del hardware (sensor) al ver el alcance apropiado y el rango de tiempo donde se espera que los datos sean visualizados.
- Antes y después de cualquier servicio programado, actualización, o acción importante del cluster. Es mejor práctica recoger una foto antes de que y otra foto después de que cualquier mantenimiento y tiene este disponible en caso de que se abra un caso TAC. Esto ayuda al aislante de TAC que el problema buscando los cambios hizo durante el mantenimiento.
Note: Algunas interrupciones del servicio son normales por un período de tiempo inmediatamente después del mantenimiento del sistema en el cluster. El período de tiempo puede ser hasta 24 horas en el ejemplo de un reemplazo del servidor adonde un datanode VM se ejecuta en ese servidor. La redundancia del sistema normal en el cluster atenúa típicamente los efectos negativos de un reemplazo del servidor único.
Maneras diferentes de verificar al estado operacional de un cluster del Tetration
Parámetros operativos de la visualización
Un administrador que tiene el conocimiento y experiencia de la operación del cluster puede reconocer lo que parece el funcionamiento normal del cluster en su entorno. Éstos son algunos ejemplos de cuál a buscar cuando verifique si el cluster esté actuando normalmente.
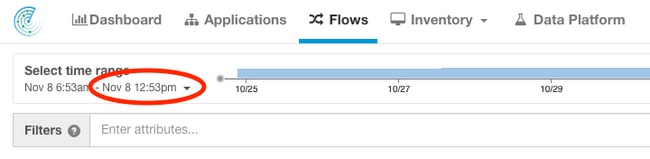
Ejemplo 1: La última cantidad de tiempo disponible del flujo es en el plazo de 10 minutos de la hora actual
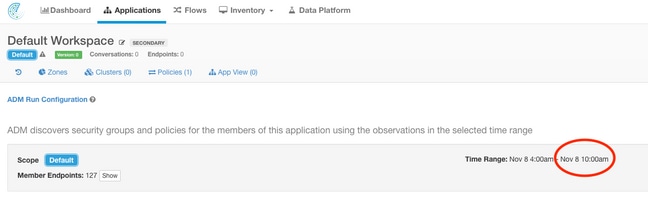
Ejemplo 2: La última cantidad de tiempo disponible del espacio de trabajo de la aplicación es en el plazo de 10 horas de la hora actual:
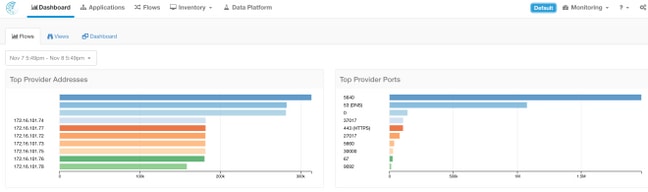
Ejemplo 3: Se puebla el contenido del panel.
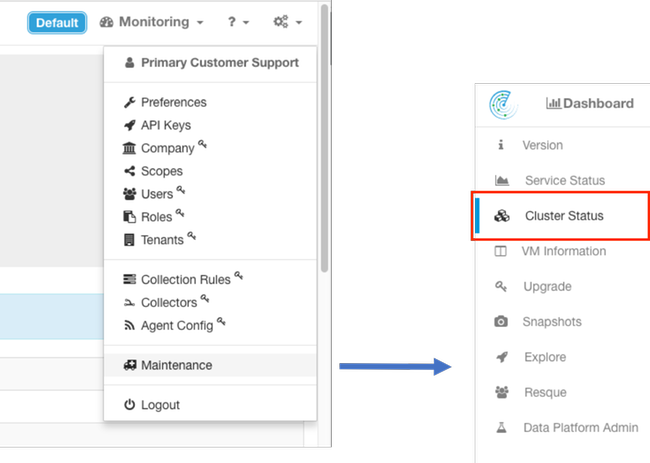
Estatus del cluster
Un cluster del Analytics del Tetration consiste en o 6 (8RU) o 36 servidores (39RU) dependiendo del cluster teclean. La página del estatus del cluster proporciona el estado de los servidores así como de la otra información del servidor descubierta del metal.
La página del estatus del cluster se establece en el menú de mantenimiento disponible desde el descenso-abajo de las configuraciones (configuraciones > mantenimiento; Estatus del cluster en la columna izquierda.)
Note: Solamente el icono es visible hasta que usted haga clic en la columna de la mano izquierda.
Note: La imagen se trunca a los primeros 6 de 36 servidores (cluster 39RU).
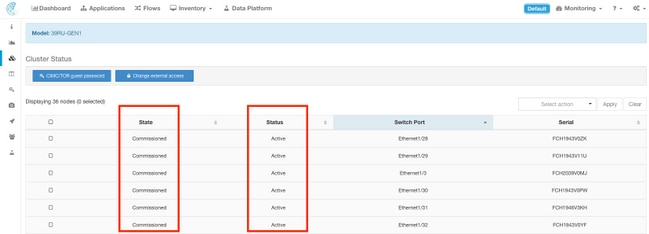
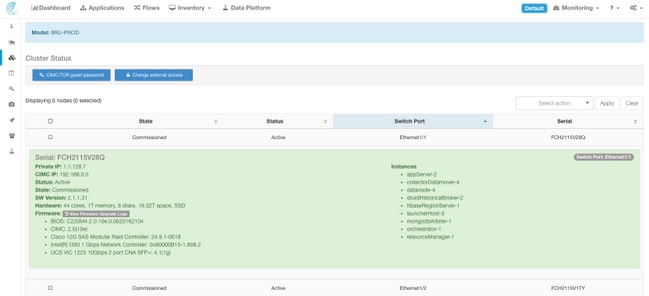
- Casos (máquinas virtuales) que se ejecutan en el servidor descubierto del metal.
- IP Address privado dentro del cluster.
- CIMC dirección IP dentro del cluster.
- Versiones de firmware (regulador BIOS, de CIMC, RAID) ejecutándose en el servidor.
Mantenga el estatus
Las páginas muestra de ServiceStatus todos los servicios que se utilizan en el cluster del Analytics del Tetration de Cisco con sus dependencias y estado de salud.
La página del estatus del servicio se establece en el menú de mantenimiento disponible desde el descenso-abajo de las configuraciones. (Configuraciones > mantenimiento; Mantenga el estatus en la columna izquierda.)
Note: Solamente el icono es visible hasta que usted haga clic en la columna de la mano izquierda.
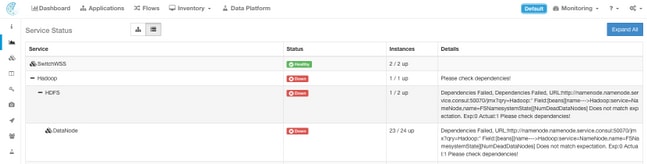
Por abandono la página del estatus del servicio muestra las funciones y las dependencias del cluster en una visión gráfica. Si son los iconos se detectan todos se ponen verde, ningún error.

Si hay un servicio que visualiza en rojo o anaranjado, la vista de árbol mostrará la lista de servicios y permitir que usted profundice en las dependencias del servicio así como sobre otros detalles que la función del estatus del servicio ha detectado. Esta información del error de la dependencia es determinado importante observar y capturar al abrir un caso con TAC.
Por ejemplo, aquí es lo que parece la visualización de la lista cuando una de las máquinas virtuales HDFS DataNode en el cluster está abajo
Note: Puede no haber un notable impacto al cluster debido a la Redundancia diseñada en el cluster del Tetration.
Note: Puede haber un cierto retardo en ciertos servicios que vuelven a un estado de funcionamiento después de que se haya realizado el mantenimiento. Por ejemplo, un servidor que tiene un caso de la máquina virtual de DataNode que se ejecuta en él que se desarme y se recomisione para el mantenimiento RMA puede tomar hasta 24 horas antes de que el problema detectado borra.
Aunque los detalles en el estatus del servicio indican qué puede suceder en caso de cierto problema detectado, la recomendación es abrir un caso TAC si hay algunas preguntas sobre las acciones del significado y/o del potencial para llevarlas el remediate.
Alertas del Bosun
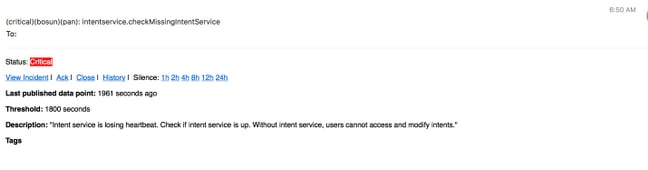
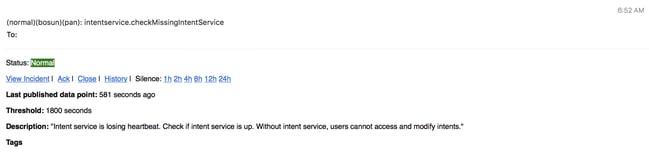
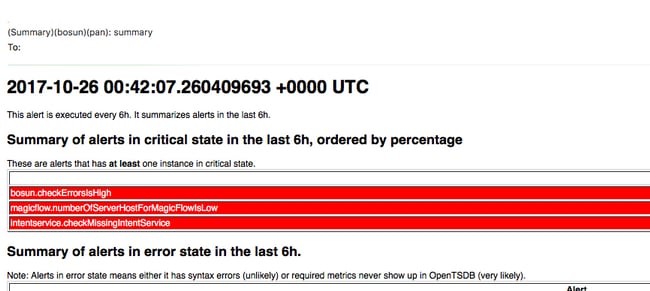
Recoja la foto y abra el caso TAC
El equipo de la solución del Tetration de Cisco especializa y apoya a los clientes del Analytics del Tetration. Uno de los temas comunes que ayudan al ingeniero de TAC más con su proceso de Troubleshooting es una colección de la foto de registros del cluster. A veces solamente la información contenida en los archivos del registro de la foto es bastante para entender el problema. Si no, una foto proporciona el punto de partida en el proceso de Troubleshooting en muchos casos.
Una foto en un cluster del Tetration es similar al techsupport en otros productos de Cisco. Es un archivo o archivos del registro comprimidos del tarball de todos los servidores y máquinas virtuales e incluye:
- Registros
- Estado de la aplicación y de los registros Hadoop/YARN
- Historial alerta
- Estadísticas numerosas TSDB
La página de la foto se establece en el menú de Maintence disponible desde la desconexión de las configuraciones. (Configuraciones > mantenimiento; Fotos en la columna izquierda.)
Note: Solamente el icono es visible hasta que usted haga clic en la columna de la mano izquierda.
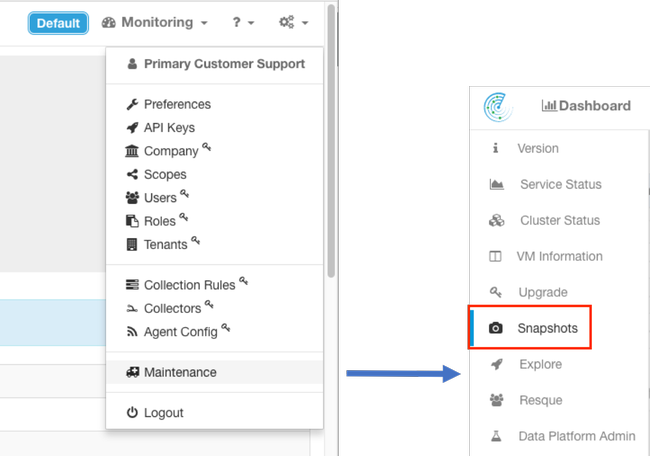
La página de la foto ofrece las diversas opciones para seleccionar pero a menos que sea dada instrucciones por un ingeniero de TAC, los valores predeterminados se puede utilizar para recoger la foto.
Una área importante a modificarse es comentarios. Los comentarios deben proporcionar la información para indicar porqué la foto fue recogida cuando hay fotos múltiples recogidas del cluster y el comentario agregado está también disponible dentro de la foto durante el análisis por el TAC de Cisco.

Cuando se hace clic el botón Create, el proceso de la foto comienza. Solamente una foto puede ser en un momento creado y tarda varios minutos para que el proceso complete. Una barra de progreso para la colección de la foto se considera en la cima de la página de la foto.
La foto se puede entonces descargar al sistema local del usuario como usted hizo clic el link apropiado de la descarga en la página de la foto, tal y como se muestra en de la imagen:

Note: El archivo de foto puede ser tan grande como varios cientos de megabytes de tamaño. Este archivo se puede entonces cargar en el caso TAC abierto.
Información Relacionada
Con la colaboración de ingenieros de Cisco
- Bryan DeaverTAC de Cisco Enginer
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)