Cisco Crosswork Situation Manager 7.0.x Clustering Algorithms
Available Languages
Cisco Crosswork Situation Manager 7.0.x Clustering Algorithms
Powered by Moogsoft AIOps 7.0.1
Last Updated: November 29, 2018
You can enable and configure the different clustering algorithms in Cisco Crosswork Situation Manager to cluster alerts and reduce noise from your operation stack. Select a clustering algorithm that meets your requirements:
■ Cookbook - Deterministic clustering algorithm that creates Situations defined by the relationship between alerts. Cookbook is highly customizable and can be configured to cluster by specific attribute such as source, language, proximity and time.
■ Speedbird - Linguistic clustering algorithm that analyzes the language similarity across multiple event attributes in order to identify relationships between alerts. Speedbird also factors time similarity into the calculation.
■ Tempus - Time-based clustering algorithm that clusters alerts with similar timestamps. Tempus uses community detection methods to identify which alerts with similar arrival patterns it clusters together. This is the second version of the Classic Sigaliser.
■ Vertex Entropy - Topological calculation that indicates the critical nodes within your network and their tendency to produce important events. Once the calculation is run against a topological map of the connected nodes in your network, it applies a Vertex Entropy value for each node or "vertex".
Cookbook
Cookbook is a deterministic clustering algorithm in Cisco Crosswork Situation Manager that creates Situations defined by the relationships between alerts.
You can configure Cookbook to cluster alerts into Situations if they have specific characteristics such as temporal or topological proximity. Cookbook filters can include characteristics such as the following:
■ Class or type
■ Description
■ Server priority
■ Geographical location
■ Environment classification
Each Cookbook is a collection of Recipes: sets of configurable filters, triggers, and other calculations such as priority ordering and entropy threshold. A Cookbook can run multiple Recipes concurrently to process the incoming event stream and produce a variety of Situations. A Cisco Crosswork Situation Manager deployment may include multiple instances of moogfarmd, each of which can run multiple Cookbooks.
To configure a Cookbook and its recipes via the Cisco Crosswork Situation Manager UI, see Configure a Cookbook.
To use more advanced features, such as merging and Moobot-controlled Recipes in moogfarmd, see Configure a Cookbook Manually.
Cookbooks configured in the UI and in moogfarmd can run concurrently.
Configure a Cookbook Manually
Cookbook is a deterministic clustering algorithm in Cisco Crosswork Situation Manager that creates Situations defined by the relationships between alerts.
You can install a basic Cookbook via the UI by supplying a name, the recipes you want it to use and configuring a few of the available properties. See Configure a Cookbook for setup steps.
Configure an advanced Cookbook if you want to configure additional properties such as determining if it runs on startup, selecting a different Moobot and other options available not available in the UI.
Before you Begin
Before you set up your Cookbook, ensure you have met the following requirements:
■ You have set up the recipes you want your Cookbook to use. See Configure a Recipe for details.
■ Your LAMs or integrations are running and Cisco Crosswork Situation Manager is receiving events.
■ You have configured the Moolet that you want Cookbook to process the output of.
Configure an Advanced Cookbook
Edit the configuration file at $MOOGSOFT_HOME/config/moog_farmd.conf to control the behavior of the Cookbook.
See the Cookbook Reference for a full description of all properties. Some properties in the file are commented out by default. Uncomment the properties to enable them.
1. Provide a name and description for the Cookbook:
■ name: Name of the Cookbook (required).
■ Classname: Class of the Moolet. Do not change.
■ description: Text description of the Cookbook.
2. Configure the Cookbook's behavior for when it starts and stops running:
■ run_on_startup: Determines whether Cookbook runs when Cisco Crosswork Situation Manager starts.
■ persist_state: Saves Cookbook's state if a failover occurs.
■ metric_path_moolet: Determines whether Cisco Crosswork Situation Manager includes Cookbook in the Event Processing calculation for Self Monitoring.
■ moobot: Defines the Moobot that Cookbook loads at startup.
■ process_output_of: Defines the Moolet sources of the alerts that Cookbook processes.
3. Configure the Cookbook algorithm and how it clusters alerts:
■ membership_limit: Maximum number of Situations that an alert can be a member of.
■ scale_by_severity: Cookbook treat alerts with a high severity like alerts with a high entropy value. entropy_threshold: Minimum entropy value an alert must have in order for Cookbook to include it in a Situation. single_recipe_matching: Enables Cookbook to treat Recipes in priority order.
■ cluster_match_type: Defines the Cookbook cluster matching method.
■ cook_for: Time period that Cookbook clusters alerts for before the recipe resets.
4. Select and name the Recipe(s) you want Cookbook to use:
■ chef: Type of recipe you want to use. CValueRecipeV2, CValueRecipe or CBotRecipe.
■ name: Name of the Recipe.
■ description: Description of the Recipe.
5. Configure the Recipe behavior and the filters that define the alert relationships. See Configure a Cookbook Recipe for more details.
■ recipe_alert_threshold: Maximum number of alerts to cluster before Cookbook creates a Situation.
■ exclusion: Filter determining the alerts to exclude from Situation creation.
■ trigger: Filter determining the alerts that Cookbook considers for Situation creation.
■ seed_alert: Filter determining whether to create a Situation from a seed alert.
■ rate: Filter determining the minimum event rate per minute required for Cookbook to create a Situation. min_sample_size: Minimum number of events contained in a cluster before Cisco Crosswork Situation Manager calculates the rate. max_sample_size: Maximum number of events contained in a cluster before Cisco Crosswork Situation Manager calculates the rate.
■ cook_for: Time period that Cookbook clusters alerts for before the recipe resets. The Cookbook cook_for value overwrites this if it exists.
6. Configure the alert matching properties for the Recipe:
■ cluster_match_type: Defines how Cookbook matches alerts to clusters.
■ hop_limit: Maximum number of hops between the alert source nodes in order for the alerts to qualify for clustering.
■ components: Values that alerts must match for Cookbook to include them in a Situation.
Restart the moogfarmd service to activate any changes you make to the configuration file. See Control Cisco Crosswork Situation Manager Processes for further details.
Example
The following example demonstrates a Cookbook that uses a CValueRecipeV2 that splits alerts into clusters with either an identical source_id ( hostname) or a description that are 50% similar. You control this under the components property:
It also only creates a Situation from a seed alert with a Vertex Entropy value of 0.75 which indicates a node of high topological importance. You control the seed alert filter with this property:
The full example Cookbook with both configurations is as follows:
Start or Stop the Cookbook
You can start or stop Cookbook if you want to make additional changes. You must always restart moogfarmd for these changes to take effect. Note that restarting the moogfarmd clears any existing clusters from Cisco Crosswork Situation Manager. See Control Cisco Crosswork Situation Manager Processes for further details.
Configure a Recipe Manually
A Cookbook Recipe is a set of configurable filters, triggers, and calculations that defines the type of alerts and the alert relationships that Cookbook detects and clusters into Situations.
When you add Recipes from moogfarmd, you can only configure advanced properties such complex Cookbook such as calling Moobot functions. You can configure three recipe types: CValueRecipeV2, CValueRecipe and CBotRecipe. See Recipe Types for more details.
Refer to Cookbook and Recipe Reference to see the available properties.
Before you Begin
Before you set up your Recipe, ensure you have met the following requirements:
■ Your LAMs or integrations are running and Cisco Crosswork Situation Manager is receiving events.
■ If you want to use Vertex Entropy or hop limit in your Recipes, you have imported your network topology. See Import a Network Topology.
Create a Cookbook Recipe
Edit the configuration file at $MOOGSOFT_HOME/config/moog_farmd.conf to add a new Recipe or edit an existing one.
See the Cookbook and Recipe Reference for a full description of all properties. Some properties in the file are commented out by default. Uncomment the properties to enable them.
1. Provide a name and description for the Recipe:
■ chef: Type of Recipe. Defaults to CValueRecipeV2.
■ name: Name of the Recipe.
■ description: Text description of the Recipe that appears in each Situation.
2. Configure the Recipe behavior and filters that define the alert relationships:
■ recipe_alert_threshold: Maximum number of alerts to cluster before Cookbook creates a Situation.
■ exclusion: Filter that determines the alerts to exclude from Situation creation.
■ trigger: Filter that determines the alerts that Cookbook considers for Situation creation.
■ seed_alert: Filter that determines whether to create a Situation from a seed alert.
■ rate: Filter that determines the minimum event rate per minute required for Cookbook to create a Situation. min_sample_size: Minimum number of events contained in a cluster before Cisco Crosswork Situation Manager calculates the rate. max_sample_size: Maximum number of events contained in a cluster before Cisco Crosswork Situation Manager calculates the rate. cook_for: Time period that Cookbook clusters alerts for before the recipe resets. The Recipe cook_for value overwrites the Cookbook cook_for value.
3. Configure the alert matching properties for the Recipe:
■ cluster_match_type: Defines how Cookbook matches alerts to clusters.
■ hop_limit: Maximum number of hops between the alert source nodes in order for the alerts to qualify for clustering.
■ components: Define additional configuration such as case sensitivity for CValueRecipe and shingle size for CValueRecipeV2.
Restart the moogfarmd service to activate any changes you make to the configuration file. See Control Cisco Crosswork Situation Manager Processes for further details.
Examples
See Recipe Examples for example configuration of different Value and Bot Recipes.
Recipe Examples
The following examples show how you can configure the different types of Recipe in the Cookbook clustering algorithm.
See Recipe Types for more details on the different Recipes available.
CValueRecipeV2 Example
The following example shows a Value Recipe V2 that clusters alerts with:
■ Alert source IDs that are 75% similar when breaking the source ID into shingle of four character.
■ Alert descriptions that are 75% similar.
A shingle value of -1 or less means Recipe compares the text similarity of entire words, rather than breaking the text into shingles. See Recipe Types for more details about the calculation.
CValueRecipe Example
The following Value Recipe example shows a recipe that splits alerts into clusters with either an identical source_id (hostname) or a descript ion that are 50% similar. It also only creates a Situation from a seed alert with a Vertex Entropy value of 0.75, which indicates a node of high topological importance. See Vertex Entropy for more information.
{
chef: "CValueRecipe",
name: "SplitBySourceAndDescription", description: "Value Recipe outage", recipe_alert_threshold: 0, exclusion: "severity < 5",
trigger: null,
seed_alert: "vertex_entropy = 0.75", rate: 0,
#Given in events per minute min_sample_size: 5,
max_sample_size: 10,
cook_for: 5000,
cluster_match_type : "first_match", matcher : {
components: [
{ name: "source_id", similarity: 1.0, case_sensitive: true
},
{ name: "description", similarity: 0.5, case_sensitive: true
}
]
}
}
The example CValueRecipe below shows a recipe that can be used alongside a New Relic integration.
This recipe clusters alerts that have an identical source_id (hostname) every fifteen minutes:
{
chef: "CValueRecipe",
name: "New Relic Hostname Recipe",
description: "Recipe to create situations based on 100% similarity of the hostname received from New Relic",
recipe_alert_threshold: 1, exclusion: null,
trigger: null, seed_alert: null, rate: 0,
#Given in events per minute min_sample_size: 5,
max_sample_size: 10,
cook_for: 900, matcher: {
components: [
{ name: "source_id", similarity: 1.0, case_sensitive: true
},
]
}
},CBotRecipe Example
The example Bot Recipe below shows a recipe that uses methods in the Cookbook.js Moobot to cluster by topological similarity. It excludes alerts that have a severity of less than minor and clusters alerts that are 80% similar.
{
chef: "CBotRecipe", name: "MaxwellDaemon",
description: "Maxwell Recipe outage", recipe_alert_threshold: 0,
trigger: null,
exclusion: "severity < 3", rate: 1,
#Given in events per minute min_sample_size: 5,
max_sample_size: 10, cluster_match_type : "first_match", matcher: {
initialise_function: "initBuckets", member_function: "checkBucket", similarity: 0.8
}
cook for: 2000,
}
Recipe Types
The Cookbook sigaliser uses the following Recipe types to define alert relationships and control how the Sigaliser clusters alerts:
■ CValueRecipeV2
■ CValueRecipe
■ CBotRecipe
The CValueRecipeV2 and CValueRecipe use different methods to calculate the textual similarity between alerts. The CBotRecipe is a customizable recipe that allows you to call specific functions from a Moobot.
CValueRecipeV2
CValueRecipeV2 extracts and analyzes groups of consecutive characters to measure text similarity between alerts. It is the default Recipe in Cookbook for new Cisco Crosswork Situation Manager v7 installations and for any new Cookbooks you create.
This recipe uses the bag-of-words model and shingling natural language processing methods to calculate the text similarity between alerts. Shingling is the process in which Cookbook extracts groups of consecutive characters called shingles from a source string. Potential sources include the alert source ID or description. To measure similarity, Cookbook calculates the number of identical shingles. You can control the calculation using the shingle_size component property.
For example, if you set the shingle_size to 2 and Cookbook receives two alerts with the source IDs:
Cookbook extracts the following shingles from the source ID strings:
Ten out of the 12 shingles are identical which indicates a high similarity.
If you set the shingle_size to 0 or less, Cookbook treats the string values as words in its text similarity calculation. In the UI, you select whether Cookbook treats string values as shingles or words.
For example, if Cookbook receives two alerts with the source IDs: "database01" and "database02", it treats them as:
These are two words are not identical so the two alerts would be given a low similarity. The default shingle size settings in the CValueRecipeV2 are optimal for most use cases.
CValueRecipe
The first version of the CValueRecipe that uses a string comparison mechanism to cluster alerts by textual similarity.
CValueRecipe uses string metric algorithms to calculate similarity. The calculation breaks strings up into partitions and performs a character-by- character comparison of each partition to measure similarity.
The following example sets the Recipe to monitor alerts with source IDs and descriptions with a similarity of 1.0 on a scale of 0 to 1 where 0 is dissimilar and 1 is identical:
matcher : {
components: [
{ name: "source_id", similarity: 1.0, case_sensitive: true },
{ name: "description", similarity: 1.0, case_sensitive: true }
]
}
In a scenario where Cookbook receives the following alerts:
| Alert |
source_id |
description |
| A |
001 |
database |
| B |
001 |
webserver |
| C |
002 |
database |
| D |
002 |
database |
Based on the Recipe configuration, Cookbook creates three clusters: one containing alert A, one containing alert B and one containing alerts C and D which had identical source IDs and descriptions. The string may contain non-alphabetical characters. CValueRecipe can also convert numeric values to strings for comparison.
The Value Recipe uses the case_sensitive component to enable or disable case sensitivity as a factor in text similarity matching. For example, if you want source IDs to only match if case sensitivity is identical but you do not want descriptions to be case sensitive:
matcher: {
components: [
{ name: "source_id", similarity: 1.0, case_sensitive: true}
{ name: "description", similarity: 0.7, case_sensitive: false}
]
}
If you do not enable case sensitivity, then an alert from a source called "WebServer1" and an alert from a source called "webserver1" would have a lesser similarity.
To make Cookbook match each value in the list individually, set "treat_as : list" in the component configuration. For example:
If you do not use this configuration, Cookbook treats the components value as a string.
CBotRecipe
CBot Recipe is a customizable Recipe that allows you to call certain functions from the Cookbook.js Moobot.
You can configure the Bot recipe to call functions defined in the Cookbook.js Moolet. The Cookbook Moolet defines two functions, an initialisation function called initialise_function and a member_function. You can call the initialise_function once to set up any necessary initialisation of the algorithms you want to write in the Moobot:
You can call the member_function once for every event that passes the trigger. Cookbook considers each of these events for matching and for every candidate cluster in the system.
For example, Cookbook calls the member_function 100 times if there are 100 candidate clusters for each alert that comes through the system. Cookbook compares the alert to candidate clusters that are potential Situations. If the alert's similarity matches or exceeds the matcher value, Cookbook adds the alert to the candidate cluster.
Match List Items in Recipes
You can create Recipes and configure clustering around the use of 'custom_info' list-based fields in Alert Custom Info.
You can also set whether list-based clustering of a custom_field is applied. If not, the field will be treated as string.
Match list items for a Custom Info Field
To match list items for a custom info field:
1. Click on the Clustering tab.
2. Select the 'custom_info' attribute from the Cluster By list. Enter the custom_info field name in the box below.
3. Check the box next to Match List Items to match individual items in custom_info lists.
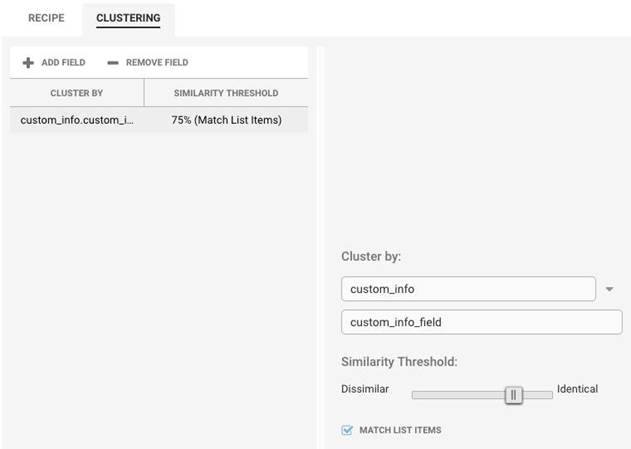
Configure list-based Matching
You can also set list-based matching for Cookbook Recipes defined in moogfarmd. To enable this:
1. Edit $MOOGSOFT_HOME/config/moog_farmd.conf. See Cookbook and Recipe Reference for all available Recipe properties.
2. Add a qualifier treat_as: "list" for any custom_info components in the matcher:
After configuring the Recipe, you can expect the following alerts to arrive in your system:
Example
If you configure your Recipe to treat the custom_field value as list and set the similarity to 1.0:
This configuration would produce four clusters:
■ Cluster A: Alert 1 and alert 2 match for "London".
■ Cluster B: Alert 2 matches for "San Francisco".
■ Cluster C: Alert 3 and alert 4 match on "Venice".
■ Cluster D: Alerts 2, 3 and 4 match on "Bangalore".
This can produce four separate Situations as per the four clusters above, or two Situations because cluster D contains all the alerts in clusters B and C.
If the Recipe does not see custom_info field as a list then it treats the field as a single string. This means in this example all four alerts would end up in separate Situations with no clustering.
Cookbook and Recipe Reference
This is a reference for the Cookbook Sigaliser algorithm and its associated Recipes. The Cookbook configuration properties are found in $MOOGS OFT_HOME/config/moog_farmd.conf.
Moolet
name: Name of the Cookbook Sigaliser algorithm. Do not change.
Type: String
Required: Yes
Default: "Cookbook"
class: Moolet class name. Do not change.
Type: String
Required: Yes
Default: "CCookbook"
run_on_startup: Determines whether Cookbook runs when Cisco Crosswork Situation Manager starts. If you enable this property, Cookbook captures all alerts from the moment the system starts, without you having to configure or start it manually.
Type: Boolean
Required: No
Default: false
persist_state: Enables Cookbook to save its state for High Availability systems so if a failover occurs, the second moogfarmd can continue from the same point.
Type: Boolean
Required: No
Default: false
metric_path_moolet: Determines whether Cisco Crosswork Situation Manager includes Cookbook in the Event Processing calculation for Self Monitoring.
Type: Boolean
Required: No
Default: true
moobot: Specifies which associated Moobot the Cookbook Moolet loads at startup.
Type: String
Required: Yes
Default: "Cookbook.js"
process_output_of: Defines the Moolet source of the alerts for Cookbook.
Type: List
Required: Yes
One of: AlertBuilder, AlertRulesEngine, MaintenanceWindowManager, EmptyMoolet
Default: "MaintenanceWindowManager”
Algorithm
membership_limit: Maximum number of Situations an alert can be part of. This does not impact alerts in merged Situations. Smaller limits result in fewer Situations with many alerts and many Situations with fewer associated alerts. Larger limits result in many Situations with few alerts and a few Situations with many alerts. The optimal value is between 1 and 5.
Type: Integer
Required: Yes
Default: 1
scale_by_severity: Cookbook treat alerts with a high severity like alerts with a high entropy value. Cisco Crosswork Situation Manager divides the severity number by the maximum severity (5) to calculate the scale. For example, for an alert with minor severity, the entropy would be 3/5.
Type: Boolean
Required: No
Default: False
entropy_threshold: Minimum entropy value that an alert must have for Cookbook to consider it for clustering into a Situation. Cookbook does not include any alerts with an entropy value below the threshold in Situations. Set to a value between 0.0 and 1.0. The default of 0.0 means Cookbook processes all alerts.
Type: Decimal
Required: No
Default: 0.0
single_recipe_matching: Enable single_recipe_matching for Cookbook to treat Recipes in priority order, based on the order of configuration in moof_farmd.conf. The first recipe in the list takes highest priority. If an alert appears in a Situation that a recipe with a low priority order creates, it may reappear in a Situation that a Recipe with a higher priority creates.
Type: Boolean
Required: No
Default: false
cluster_match_type: Defines how Cookbook matches clusters. You can select the first_match in order so Cookbook adds alerts to the first cluster over the similarity threshold value. This is the default behavior for Cookbook. Alternatively, select closest_match to add alerts to the cluster with the highest similarity greater than the similarity threshold value. This option may be less efficient because Cookbook needs to compare alerts against each cluster in a Recipe. The Recipe-level match type configuration overrides the Cookbook-level definition.
Type: List
Required: No
One of: first_match, closest_match
Default: "first_match"
cook_for: Time period for which Cookbook clusters alerts before the recipe resets and determines when to start a new cluster. Different cook_for times per Recipe are useful for monitoring systems with different fail rates, to ensure the Recipe clusters all the relevant Events relating to a failure. For example:
■ A Recipe monitoring for network link failures, which have a fast fail rate and many events in a short time, should have a short cook_for time.
■ A Recipe monitoring for disc or CPU issues, which have a slower fail rate as the issue builds, should have a longer cook_for time.
Recipes without cook_for values inherit the value from the Cookbook. Leave empty if you want Recipes to determine the cook_for value.
Recipes
Recipes determine how Cookbook detects relationships between alerts and considers them for clustering into Situations. You can configure Recipes with different event filters, triggers and similarity comparisons using these parameters:
chef: The recipe type: CValueRecipeV2, CValueRecipe or CBotRecipe. The Value Recipes cluster according to the recipe definitions whereas Bot Recipes follow custom clustering logic defined by a Moobot. See Configure a Cookbook Recipe / Migrated to Xyleme for more details.
Type: String
Required: Yes
One of: CValueRecipeV2, CValueRecipe, CBotRecipe
Default: "CValueRecipeV2",
name: Name of the Recipe. Use a unique or descriptive name.
Type: String
Required: Yes
Default: "SplitBySourceAndDescription",
description: Description of the Recipe.
Type: String
Required: No
Default: "Value Recipe outage",
recipe_alert_threshold: Maximum number of alerts to cluster before Cookbook creates a Situation. If left as '0', a single alert can generate a new Situation.
Type: Integer
Required: Yes
Default: 0,
exclusion: Filter that determines the alerts to exclude from Situation creation. By default Cookbook excludes all alerts with a severity less than critical. For details on creating a filter, see Filter Search Data.
Type: String
Required: No
Default: "severity < 5",
trigger: Filter that determines the alerts that Cookbook considers for Situation creation. Cookbook ignores alerts that match the exclusion filter.
Type: String
Required: No
Default: "null",
seed_alert: Filter that determines whether to create a Situation from a seed alert if it meets both trigger and seed_alert filter criteria. Cookbook considers subsequent alerts for clustering if they meet the trigger filter criteria. Alerts that arrived prior to the seed alert that met the trigger filter criteria do not form Situations.
The seed_alert filter is a mechanism to ensure that only specific events create Situations. For example, if you create a seed_alert filter if the description matches 'Switch failure', alerts are eligible for clustering only after a seed alert with the matching description arrives to create a Situation.
Type: String
Required: No
Default: "null",
Example: 'Description' MATCHES "Switch failure",
rate: Filter that determines the minimum event rate per minute required for Cookbook to create a Situation. Cookbook only calculates the rate after the cluster meets the threshold defined by min_sample_size or max_sample_size.
Type: Integer (Number of events per minute).
Required: No
Default: "0",
min_sample_size: Minimum number of events contained in a cluster before Cisco Crosswork Situation Manager calculates the rate.
Type: Integer
Required: No
Default: "5",
max_sample_size: Maximum number of events contained in a cluster before Cisco Crosswork Situation Manager calculates the rate.
Type: Integer
Required: No
Default: "10",
cook_for: Time period for which Cookbook clusters alerts before the recipe resets and determines when to start a new cluster. Different cook_fo times per Recipe are useful for monitoring systems with different fail rates, to ensure the Recipe clusters all the relevant Events relating to a failure. For example:
■ A Recipe monitoring for network link failures, which have a fast fail rate and many events in a short time, should have a short cook_for time.
■ A Recipe monitoring for disc or CPU issues, which have a slower fail rate as the issue builds, should have a longer cook_for time.
Recipes without cook_for values inherit the value from the Cookbook.
Type: Integer
Required: No
Default: "5000"
cluster_match_type: Defines how Cookbook matches alerts to clusters. The first_match default option adds alerts to the first cluster above the similarity threshold value. The alternative is closest_match to add alerts to the cluster with the highest similarity greater than the similarity threshold value. The latter option might be less efficient because it needs to compare alerts against each cluster in a Recipe.
Type: String
Required: No
Default: "first_match",
Matcher
hop_limit: Maximum number of hops between the alert source nodes in order for the alerts to qualify for clustering. Cisco Crosswork Situation Manager measures hop limit from the first alert that formed the Situation and always follows the shortest possible route in the network. You can only use hop limit if you have imported your network topology into the system. See Import a Network Topology for details.
A hop is the jump between two directly connected nodes in a network. For more information on hops, see Vertex Entropy.
Type: Integer
Required: No
Default: "2",
components: Values that alerts must match for Cookbook to include them in a Situation. You can provide multiple values such as source, description, service or using custom_info fields.
The Value Recipe V2 uses the shingle_size component to determine the similarity between different strings. See Recipe Types for more details.
You can enable or disable case sensitivity with CValueRecipe V1. You can also configure Cookbook to match each value in the list individually. See CValue Recipe for details.
Type: String
Required: No
Cookbooks
Speedbird
■ Speedbird's Algorithm
■ Configuration
■ Tuning guidelines
Speedbird groups events related to an actionable outage into clusters of their related alerts. These clusters are service impacting, with the group of ‘clustered’ Alerts providing operational value to someone using the system.
Speedbird allows you to configure a set of parameters of an Event to drive the clustering in addition to time. For example, you may want a group of Alerts and Events together that have a co-incidence in time, but also have a coincidence in another value of the Event, such as, the hostname. Speedbird allows you to create clusters of Alerts with a similar hostname that have also occurred at a similar time.
Speedbird's Algorithm
The algorithmic technique used by SpeedBird is based around K-means, which is a well-understood and traditional clustering algorithm that is a form of unsupervised machine learning. For the SpeedBird Moolet, Cisco Crosswork Situation Manager uses some of the same algorithmic tool chain that is used in the Sigaliser along with the K-means algorithm. For instance, Cisco Crosswork Situation Manager still uses the same time based determination of how many real clusters there are in the data at a given point in time. Non-negative matrix factorisation in the limit collapses into a K-means calculation, but is more computationally efficient.
Configuration
To configure SpeedBird, the following should be read in conjunction with the Tuning guidelines, to enable you to produce optimal results.
sig_resolution
In moog_farmd.conf, there is a general sig_resolution parameter grouping before the Moolet definitions with the following parameters:
■ These parameters are set for all Sigalisers whether it is SpeedBird or the traditional Sigaliser running in a given farmd. The sig_resolution parameters allow you to compare pre-existing Situations and determine if it is an evolution of an existing Situation, or, a new Situation
Moolet and Algorithm
The parameter groups Moolet and Algorithm function in the same way as those in the existing Sigaliser.
| Parameter |
Input |
Description |
Example |
| name |
- |
The name of the Sigaliser |
Speedbird |
| classname |
- |
The classname of the Sigaliser This is hardcoded and should never be changed |
CSpeedbird |
| run_on_startup |
Boolean |
If enabled, an instance of the Sigaliser will be created when moog_farmd starts. This is disabled by default |
false |
| process_output_of |
AlertBuilder AlertRulesEngine |
This sets whether the Sigaliser processes the output of either the Alert Builder or Alert Rules Engine. The latter can only be used if automations are desired prior to the Situation resolution Please note: The Sigaliser can only have one input |
AlertBuilder |
| time_compression |
Boolean |
If enabled the Sigaliser will ignore empty time buckets. If disabled, it will include empty time buckets. Please Note: For low data rates you should set this to ‘true’ for normal data rates set this to ‘false’. |
true |
| scale_by_severity |
Boolean |
If enabled, high severity Alerts are treated as having higher entropy. This scaling is done as the severity constant number divided by the maximum severity (5) |
true |
| entropy_threshold |
Integer |
The value of this parameter is the minimum entropy that the Alert must have to be included in the Sigaliser calculation. Any Alert that arrives at the Sigaliser with a lower entropy than this value will not be included in Situations. Please note: The default value of 0.0 means every Alert will be processed by the Sigaliser |
0.35 |
sig_alert_horizon
The sig_alert_horizon parameter allows you to prune clusters. The value allows you to control when you remove outlying Events from the cluster:
■ If the value is less than <0.0, no pruning is undertaken.
■ At 0.0, members that are further than one standard deviation from the centroid of the cluster are eliminated.
■ At more than > 0.0 the standard deviation is multiplied by sig_alert_horizon, and then members further than mean + sig_alert_h orizon*std_dev distance from centroid are eliminated.
Every cluster has a centroid, which is the average point in the middle of a cluster.
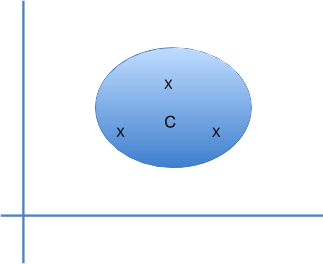 |
In the diagram above there are three points in a defined cluster (X), and the centroid (C), which is not a real point in this space phase but represents the center of the cluster. You compute the distance of each point from the centroid of the cluster, which results in an average distance and standard deviation. You can then work out the standard deviation to determine the spread of the cluster. A low standard deviation, i.e., 0, means all of the points are the same distance from the centroid; whereas, a high standard deviation means they are a highly variable distance from the centroid thus indicating a random cluster.
components
You can choose which parameters of an Event are used by the clustering algorithm. In the following example, "source", "source_id", "description" are declared:
Additionally, the system always takes into consideration the time that the Event arrives in the system (event_time or last_occurred for an Alert). You can have as many components as you like, but, the more components that are selected, the greater numerical complexity is introduced into the system, and there is a chance you will get a smaller number of Alerts per cluster and less correlation.
Partitioning
There are two methods of partitioning the data into Situations. The first is 'partition_by' which splits the clusters according to the parameters specified. The second is 'pre_partition', which splits the incoming Event stream before clustering.
Note: Pre-partitioning is recommended as it does not interfere with the results of the clustering algorithms
partition_by
After clustering has taken place and before you enter merging and resolution, you can split clusters into sub-clusters based on a component of the Events. For example, you can use the manager parameter to ensure the Situations only contain Events from the same manager. In general, and by default, you should comment out the partition_by parameter.
pre_partition
An alternative way of partitioning is to use pre_partition which allows you to specify a component field (from the list of specified components) around which the Event stream will be partitioned before the K-means clustering occurs. The Alerts in the resulting Situations will each contain a single value for the component field chosen.
For example, if the SpeedBird component option was set to:
In the metric below, the description component is being weighted more heavily compared to source and manager. Please note that the metric always contains one more values than the components specified and that the first value always corresponds to time.
This results in Situations containing Alerts with more similar description fields and a variety of source and manager fields.
Adding the following property ensures that Situations contain Alerts with very similar description fields, a variety of source fields but only a single distinct manager field.
pre_partition, like partition_by, is defaulted to false in moog_farmd.conf so has no effect. If pre_partition is not required there is no need to modify the existing moog_farmd.conf files to include the property.
It is possible to configure pre_partition and partition_by at the same time, but the partition_by parameter will only have any effect if it is applied to a different component.
A note on time_compression and pre_partition
pre_partition splits the Events into separate streams based on the component you have specified, as opposed to partition_by, which allows the algorithms to work on the whole Event stream and then splits up the results.
Partitioning the Event stream using pre_partition can make time_compression less effective. There are many things in the tuning parameters and behaviours of the Sigalisers that depend upon the event rate, and because you are splitting the stream up, if you have an event rate of X and you split it into many streams, each of those streams is going to have an event rate of less than X. This can skew whether the tuning parameters you are using are appropriate, so with or without time_compression you should be careful. With time_compression, you expect to avoid silent moments in the Event stream, but this may not be the case because the effect of pre_partition is to split the stream.
For example, if you pre_partition on manager, set time_compression to true, and set window to 10 and resolution to 60, you will store up to 10 one-minute wide buckets of Events for clustering.
The Events could arrive as follows:
| Bucket |
Minute |
Manager |
| 1 |
1 |
Andrew, Alan |
| 2 |
2 |
Alan |
| 3 |
17 |
Alan |
| 4 |
18 |
Alan |
| 5 |
20 |
Andrew |
| 6 |
35 |
Alan |
| 7 |
37 |
Alan |
| 8 |
38 |
Alan |
| 9 |
57 |
Alan |
| 10 |
59 |
Alan |
| 11 |
60 |
Alan |
It should be noted that the minute 1 bucket will be dropped from the Sigaliser window because Cisco Crosswork Situation Manager only keeps the last ten live buckets. Clustering for Events with Manager Alan will only use nine buckets, and clustering for Events with Manager Andrew will only use 1 bucket.
Metric
The metric is a technical and detailed area of configuration, which relates to how Cisco Crosswork Situation Manager measures distance between two events in the phase space used for clustering. Euclidean distance is easy to compute as you calculate the square of the differences in the components (in two dimensions the distance is the hypotenuse of a right-angled triangle, in three dimensions it is the diagonal measurement of a cuboid, and so on...) add them all up and this reveals the square of the distance. This example is a simplification.
For instance, if you have x, y and z as the components of a vector, the square root of the distance is:
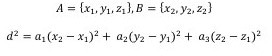 |
You can put a number in front of these sums of squares, and the values are more correctly known as the diagonal metric tensor values. Cisco Crosswork Situation Manager assumes that you should only ever consider the diagonal metric tensor values; however, in general co-ordinate geometry you can contribute to the distance by adding in, for example, (y-z)2. It is not considered useful to compare different attributes of an event for similarity.
This approach allows you to weight the distance between two events based upon their components. For example, if X represents time, Y represents source and Z represents manager, and you make a2 much bigger than a1. Any distance in source creates a lot more distance between the events than the same distance in time. This allows you to weight the importance. This is why you have four component values in all the different metrics. The default is [1,1,1,1]. You can also select a category Field, which is a parameter in the event, i.e., categoryField: "agent".
In the example configuration above, if one of the events has a value DBMON, then you use the metric [100,1,1000,1000000] to weight the distance; otherwise, if NETMON, you use the alternate metric [1,100000000,1,0]. If you have neither of these two values, you use default. This allows configuration of different metric weightings for different sources of events.
string_len_cutoff
This determines the maximum number of characters in a component to use in the distance calculation described in the previous section. This cutoff will apply to all string components being used.
For example, if there are occasionally very long descriptions, you can specify a 64-character cutoff which will avoid excessive computation. See example below:
spread_cutoff
Whereas the sig_alert_horizon is used to take events out of clusters, spread_cutoff determines whether or not to consider a cluster to be worth processing.
■ 0 means all clusters have to be one hundred percent tight, so the same distance from the center with no variation; otherwise, the cluster will be discarded. A higher number allows for looser clusters, i.e. more variation within the cluster.
The spread cutoff uses the cluster standard deviation, after any outliers have been pruned in accordance with the sig_alert_horizon paramet er to determine, which clusters should be rejected. 0.0 means that all clusters have to be one hundred percent tight, i.e., with all members matching the cluster centroid. A higher number allows for more loosely correlated clusters. It is worth noting that the metrics chosen for weighting the components can have a direct impact on the standard deviation of the clusters generated, and it may be necessary to increase the spread_cutoff value to reflect this.
ignore_case
When comparing strings, determines if the translation of strings into a number in ‘phase’ space is case sensitive. In general, case should be ignored. See below:
iterations
Unless “Entropy” seeding is specified, the initial seeds for K-means clustering includes a random element that will lead to different solutions on different iterations. If more than one iteration is chosen Speedbird will select the best solution of those returned for Situation processing. For higher numbers of iterations, K-means clustering will tend to converge on an optimal solution, which in turn leads to lower variance from one Speedbird run to another. Iterations however take both time and CPU resources so a sensible compromise between speed and the optimal solution is needed.
■ Cisco recommends a value of 5
seeding
Seeding can be set to 'Kmpp', 'Lloyd', or 'Entropy'. Both 'Kmpp' (recommended) and' Lloyd' use random elements to select seeds to initialise the clustering process, and therefore have the advantage of finding different cluster solutions over multiple iterations.
Alternatively, 'Entropy' selects the highest entropy Events to seed clusters, and as such, returns the same results on each occasion. It should be noted that this is not necessarily an optimal result.
force_causal
Setting force_causal to true ensures that Events which are part of causal Alerts are preserved. They are never discarded during the K- means clustering process, but are always returned as a member of a cluster.
The entropy range for causal alerts is defined in the moogdb.significance table.
generate_stats
generate_stats provides detailed logging useful for tuning purposes. Detailed logging is written at log level WARN to the moogfarmd.log file. The logging contains detailed information around event clustering, and also includes information about partitioning.
■ If generate_stats is not required there is no need to modify an existing moog_farmd.conf files to include the property
Tuning guidelines
To ensure you produce useful results, it is recommended that you read the following in conjunction with description of the configuration parameters:
1. Disable parameters which remove Alerts from Situations and discard Situations which are poorly correlated. Start with sig_alert_hori zon set to -0.1 (to prevent any outliers from being pruned) and spread_cutoff set to a high value (to prevent any clusters from being discarded). Subsequently modify these parameters to reduce Situation size and numbers.
2. When tuning the system, consider using 'Entropy' seeding and only switching to 'Kmpp' when you are happy with the results. 'Entropy' seeding always produces the same Situations, unlike 'Kmpp' or 'Lloyd', but often not the most appropriate ones. Using 'Entropy' seeding guarantees you can normally run a dataset once to see if the parameters you have used have given you the desired effect. 'Kmpp' seeding usually produces the best Situations with a moderate number of iterations.
3. The K in K-means indicates the number of seeds Cisco Crosswork Situation Manager clusters around and the number of Situations which are produced. It is calculated using a technique that analyses the dataset to establish the number of independent clusters of events. The calculation is dependent on number of time slices (window), and the effective event rate (after entropy thresholds etc.) which determines the number of unique signatures received in resolution*window seconds.
Note: Cisco advises that you start by asking how many tickets/Situations are expected in a day, and you adjust the resolution/window parameters to achieve the same number of Situations in a day’s worth of data. The value of k is never greater than the window and the number of unique alerts in the total window, and is often about 80% of this value.
4. If you are using time and one other component, be prepared to significantly reduce the time metric, as well as, increasing the value of the metric for the other component. For example, assume that you have the following configuration and that you are interested in a series of events that occur over 10 minutes:
The time spread of the cluster you are interested is 600 seconds. If you have increased the metric a lot on the source component, your cluster may contain a single value for source (or very closely related values). Therefore, the cluster spread value will be generated largely or entirely by the event time component. K-means solutions that split this set of events into more than one cluster are preferred over those that keep them in a single cluster. If you use default metrics [1,1], the clustering will mostly be primarily driven by time.
5. The metrics that you use may affect the spread_cutoff. If you increase a metric it may be necessary to increase the spread cut-off by quite a large amount (up to the square root of the increase of the metric).
6. It is the square root of the metric that is applied to a component. If you increase a metric for a component from 1 to 100, you emphasise the effect of that component on the resulting clusters by a factor of 10.
7. Do not vary more than one configuration parameter at a time.
8. Start with small data sets and limited (i.e., time plus one other) components before increasing the size and, or, complexity of your solution.
Classic
■ Introduction
■ Basic concepts
■ Sigaliser configuration walk-through
Introduction
The Sigaliser Moolet, also known as Sigaliser Classic, is where in Event processing, Alert streams from the Alert Builder or the Alert Rules Engine are converted into Situations.
The Sigaliser is self-contained and has no MooBot. It takes every occurrence of an Event in an Alert stream and uses matrix factorisation algorithms to identify clusters of Alerts that are temporally correlated identifying underlying service outages or Situations. The Sigaliser then updates its own internal knowledge of the stores of the Situations and the Cisco Crosswork Situation Manager database before putting updates out on the MooMS bus.
Basic concepts
There are a number of parameters in moog_farmd.conf which allow you to tune the type of Situations created by the Sigaliser. Generally, the types of Situations created for a given set of alerts are dependent on the rate of occurrence of alerts. You correspond by adjusting the resolution of the window of the Sigaliser parameters to try and match the activity.
The algorithms work by spotting signature scatter pattern of Alerts with in a time period. Firstly, how many optimal clusters there are, which should correspond to the number of current, active, service threatening outages in the given window that the Sigaliser operates on. Secondly, it then optimally factorises it down into individual groups, which Cisco Crosswork Situation Manager calls Situations. Once you have a Situation, a Situation Room is created in the MOOG database, and you are notified through the Situation View in the User Interface.
The algorithm is run in semi real-time and is triggered by either:
■ A fixed polled time period
■ A single time slice being filled up, the width of which is set by the resolution parameter in the configuration. For example, the first alert that arrives after the current slice has been filled will trigger the Sigaliser to run its algorithms
Sigaliser configuration walk-through
The behaviour of the Sigaliser is defined in the moog_farmd configuration file in a section titled Sigaliser. In general, the following parameters can be configured to either: produce more Situations with fewer alerts, or, fewer Situations with more alerts. The consequence of having more Situations with fewer alerts is that the same underlying outage could be split across multiple Situations. Fewer Situations with more alerts results in the same Situation containing alerts from multiple service outages. The process of tuning the Sigaliser parameters leads to an optimal configuration, where, Situations sharply reflect the state of the managed systems. Cisco Crosswork Situation Manager refers to Situations being “sharp” and well “resolved” when the parameters give you the best fit of Situations to service outages.
Sigaliser contains a number of parameters. name, classname, and run_on_startup are shared with other Moolets.
name
name is hardcoded and should never be changed from Sigaliser.
classname
The classname, CSigaliser, is hardcoded and should never be changed.
run_on_startup
By default, run_on_startup is set to false, so that when moog_farmd starts, it does not automatically create an instance of the Sigaliser. In this case you can start it using farmd_ctrl.
Undertaking the sigalising
The next two parameters in the Moolet direct which output should be processed:
process_output_of
process_output_of informs the Moolet to process the output of the Alert Builder or Alert Rules Engine. Usually the Sigaliser connects directly to the AlertBuilder, the AlertRulesEngine only being used if automations are desired prior to Situation resolution. The Sigaliser can have only one input.
Algorithmics
The Sigaliser runs the matrix factorisation algorithms, the parameters for which are identified in the configuration below:
time_compression
If set to true, the algorithm will ignore any empty time buckets in the Sigaliser calculation. If set to false, it will include the empty time buckets. Cisco recommends for low data-rates you should set time_compression to true, and for normal data-rates, time_compression should be set to false.
You only require time_compression in scenarios where the data rate is very low when compared to the values of window and resolution. In certain low data-rate scenarios it is possible for a window or resolution to contain no alerts. For example if the data rate is two alerts per hour and the window is 15 minutes, on average, some of the time buckets in any Situation calculation will be empty. When time_compression is true empty time-buckets are removed from the calculation, but the total number of buckets used in the calculation remains the same.
alert_threshold
Defines the minimum number of alerts that a Situation can contain. So, increasing the alert_threshold will reduce the total number of Situations. Cisco recommends an alert_threshold of 2.
alert_threshold can be used in conjunction with small values of membership_limit to produce a smaller number of Situations, each of which has more alerts.
membership_limit
The Situation creation process contains multiple steps, including a resolution and merging step. During the merging phase, the raw Situations from the factorization calculation are compared and merged with the currently active Situations. This detects when a detected Situation is either novel or an evolution in time of an existing Situation.
membership_limit restricts the number of Situations that an alert can appear in. As Situations get merged with each other over time, it is possible for an alert to appear in more Situations than are defined by membership_limit. Changing the value of membership_limit does not have a large impact on the total number of Situations but does change the distribution of the number of alerts in each Situation.
Decreasing the membership_limit results in fewer Situations with more alerts and more Situations containing a small numbers of alerts. Whereas, increasing membership_limit results in, more Situations with a greater number of alerts and fewer Situations containing a small numbers of alerts. Therefore, the optimal value seems to be between one and five, with a recommended membership_limit of three.
sig_similarity_limit (Jaccard Similarity Coefficient)
A measure of the similarity between two Situations before they are merged together. The value is the Jaccard Similarity Coefficient (JSC) defined as the ratio of shared Alerts between two Situations to total unique Alerts in both Situations.
For example, if Situation1 & Situation 2 share two common Alerts, each Situation has one unique Alert:
JSC = 2 (common Alerts) / [1 (unique to Situation 1) + 2 (common to both) + 1 (unique to Situation 2)] = 2/(1+2+1) = 2/4 = 0.5.
Reducing the similarity index will reduce the total number of Situations. Smaller values increase the likelihood of Situations being merged together, as they have to share fewer Alerts in common to be viewed as the same Situation. Conceptually, JSC values less than 0.5 are hard to justify as grounds for merging, so should be used with care. Cisco recommends a sig_similarity_limit of 0.7.
sig_alert_horizon
When the Sigaliser algorithm initially identifies a Situation, it will contain alerts that are more representative of the Situation than others. This parameter, which takes the value between 0.0 and 1.0, allows you to provide a cut off for membership based upon the highest significant alert in the cluster. If you set this value to be 0.5, for example, only alerts that have a “significance” for the Situation that is more than half of the most significant alert in the Situation will be included. 0.5 is the default value.
entropy_threshold
The value of this parameter is the minimum entropy that an alert must possess to be included in the Sigaliser calculation. Any alert that arrives at the Sigaliser with entropy below this value will never be included in a Situation. It has a value between 0.0 and 1.0 and has a default of 0.0 which means every alert will be processed.
scale_by_severity
scaleBySev allows you to bias MOOG so that high severity alerts are treated as having higher entropy. If you had the same alert arrive with a critical severity, versus a minor severity, you would give the critical severity the higher entropy than the minor severity. This scaling is done as the severity constant number divided by the maximum severity (5). So in the case of critical, you get all of the entropy and in the case of minor, you get three fifths of the entropy. In the case of clear you would get an entropy value of 0.0.
Triggers and Time Buckets
The algorithm is run incrementally as Events are ingested, as such Situations are produced and updated in real-time. There are two ways to trigger the algorithm: using a time interval or using the rate of the Event stream.
The optimal trigger for production should be sig_on_bucket=true, provided this ensures satisfactory Situation accuracy and that Situations are being regularly updated. sig_on_bucket can also simulate real-time behavior using historical data.
When Situations are not being updated regularly enough, configure sig_on_bucket = false and set sig_interval to a value no more than half of the real-time size of the window.
In a production environment, set max_backlog to a high value to avoid triggering the Sigaliser between timed executions. This parameter will cause the algorithms to run if the number of Events that arrive before either a scheduled execution, or a bucket being filled is above this value. It should be used with care and only when you have an environment where the event rate is highly variable.
sig_on_bucket
If set to true, the Sigaliser will run whenever a new time bucket occurs. Depending upon the data rate, this has the effect of executing the Sigaliser after every defined number of “resolution” seconds.
sig_on_bucket = true deactivates both the sig_interval and max_backlog triggers.
sig_interval
Executes the Sigaliser algorithm every defined number of seconds, in the example above, every 100 seconds.
sig_interval and max_backlog do not override each other; consequently, it is possible for the Sigaliser to be executed more frequently through the sig_interval value.
max_backlog
Executes the Sigaliser if the number of defined Alerts are received since last execution, in the example above, the Sigaliser is executed after 1,000,000 Alerts are received.
resolution
The duration, in seconds, for each bucket of time that the event stream is divided into. A high value for the resolution will result in Situations that are less “sharp” in time, as the wider the bucket the more likely that alerts from disconnected outages will occur in the same bucket, and potentially in the same Situation.
window
The number of time-buckets to include in the calculation. The width of the window should be chosen to match the average time period over which outages typically evolve. The total amount of time considered in any Sigaliser calculation is window multiplied by the resolution.
In general, for a high data rate you would use a smaller resolution and window than for a low data rate. For a fixed data rate, a smaller resol ution will generally result in more Situations.
Diagrams
The diagram below illustrates how a sigaliser can be triggered every 180 seconds if 'sig_on_bucket' is set to 'true', the time bucket resolution is set to '60' and the window is '3':
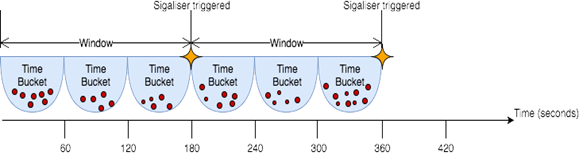 |
The diagram below illustrates how a sigaliser can be triggered if 'sig_interval' is set to 120 seconds and if 'max_backlog' is set to 50,000 Events:
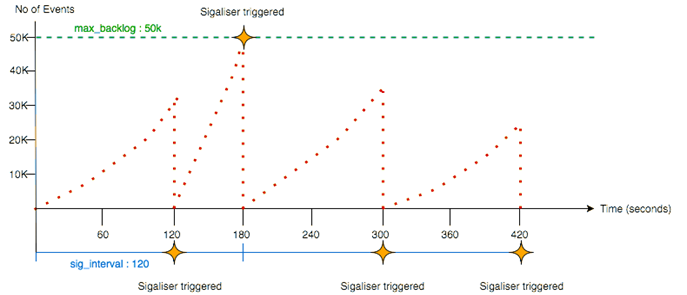
Tempus
Tempus is the time-based algorithm in Cisco Crosswork Situation Manager which clusters alerts into Situations based on the similarity of their timestamps.
The underlying premise of Tempus is that when things go wrong, they go wrong together. For example, if a core element of your network infrastructure such as a switch fails and disconnects then it affects a lot of other interconnected elements and send events at a similar time.
Tempus uses the Jaccard index to calculate the similarity of different alerts. It also uses community detection methods to identify which alerts with similar arrival patterns it should cluster into Situations.
As Tempus is time-based, you should not be use it to detect events relating to the slow or gradual degradation of a service from disks filling up or CPU usage.
One advantage of Tempus is it only uses event timestamps for clustering so no alert enrichment is required.
Time-based Clustering
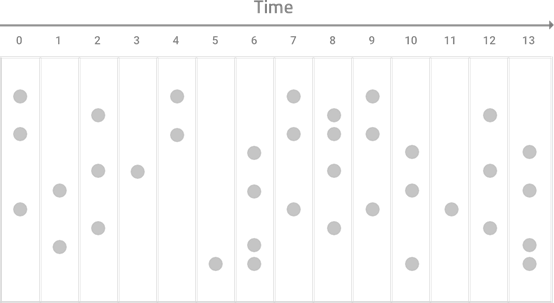
Cisco Crosswork Situation Manager applies Tempus incrementally to alerts as it ingests them so that it can create Situations in real-time. The diagrams below show how Tempus sorts and the groups alerts with similar timestamps into Situations:
Raw alerts from either the AlertBuilder or Alert Rules Engine arrive over a period of time. These are shown as gray dots in the diagram below:
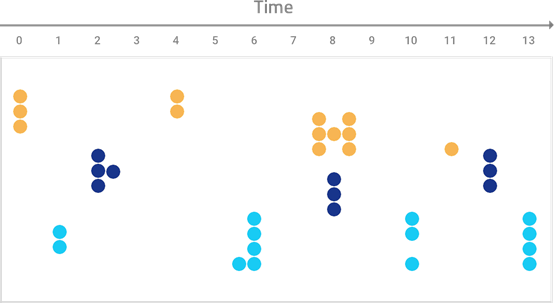
Tempus identifies and sorts which alerts have similar arrival patterns:
 |
Alerts with similar arrival patterns are clustered into Situations:
Configure Tempus
Tempus is configured and tuned using parameters in moog_farmd.conf. The Moolet parameters configure general information about each Sigaliser. The Output parameters control where the output processed by Tempus originates from. The Trigger and Sigalising parameters cont rol the Sigaliser execution and duration.
Moolet Parameters
The parameters that relate to the Tempus Moolet are as follows:
run_on_startup: Determines whether Tempus runs when Cisco Crosswork Situation Manager starts. If enabled, Tempus captures all alerts from the moment the system starts, without you having to configure or start it manually.
Type: Boolean
Default: false
persist_state: Enables Tempus to save its state for High Availability systems so if a failover occurs, the second moogfarmd can continue from the same point.
Type: Boolean
Default: false
metric_path_moolet: Determines whether Tempus is factored into the Event Processing metric for Self Monitoring or not.
Type: Boolean
Default: false
description: Describes the Situation produced by the Sigaliser.
Type: String
Default: A Tempus (a.k.a. Sigaliser V2) Situation
The default Tempus parameters are as follows:
name and classname are hardcoded and should not be changed.
Output Parameters
These parameters control the output processed by the Sigaliser:
process_output_of: Defines the Moolet source of the alerts that Tempus processes. By default, the Sigaliser connects directly to the Alert Builder and Alert Rules Engine is only being used if automations are desired prior to Situation resolution.
Type: List
One of: AlertBuilder, AlertRulesEngine, MaintenanceWindowManager, EmptyMoolet
Default: AlertBuilder
ntropy_threshold: Sets the minimum entropy value for an alert to be clustered into a Situation. Tempus does not include any alerts with an entropy value below the threshold in Situations. Set to a value between 0.0 and 1.0. The default of 0.0 means all alerts are processed.
Type: Integer
Default: 0.0
The default output parameters are as follows:
Trigger and Sigalising Window Parameters
The execution and duration of Tempus is controlled by the trigger, window and bucket parameters:
■ The sig_interval trigger determines when Tempus starts to run
■ The window is the total span of time in seconds in which Alerts will be analyzed each time Tempus runs
■ Time buckets are small five-second subdivisions of the window in which the Alerts are captured.
sig_interval: Executes the Tempus algorithm after a defined number of seconds. In the example above, the Sigaliser will run every 120 seconds (two minutes).
Type: Integer
Default: 120
window_size: Determines the length of time of the window in which Alerts are analysed and a Situation develops each time the Sigaliser is run. By default the Sigalising window is 1200 seconds (20 minutes).
Type: Integer
Default: 1200
bucket_size: Determines the time span of each bucket in which Alerts are captured in seconds. By default each bucket is five seconds long so there will be 240 buckets per window.
Type: Integer
Default: 5
Note: Cisco does not recommend you change the bucket size. If you do want to change the bucket_size then change with caution because Tempus is designed to use small bucket sizes.
arrival_spread: Sets the acceptable latency or arrival window for each Alert in seconds. This can be used to minimise or reduce the impact of multiple Alerts arriving over a small amount of time and landing in separate buckets.
Type: Integer
Default: 15
min_arrival_similarity: Determines how similar Alerts must be to be consider for clustering. This is useful way to determine what proportion of the events two Alerts need to share to have a similar pattern of arrival. By default this is 0.6667 which means Tempus will disregard any Alerts with less than two-thirds similarity.
Type: Integer
Default: 0.6667
The default trigger and sigalising window parameters are as follows:
Partitioning
Partitioning is set to 'null' by default. There are two methods to partition data into Situations. The first is 'partition_by' which splits the clusters according to the parameters specified. The second is 'pre_partition', which splits the incoming event stream before clustering.
Pre-partitioning is recommended as it does not interfere with the results of the clustering algorithms
partition_by: After clustering has taken place and before you enter merging and resolution, you can split clusters into sub-clusters based on a component of the events. For example, you can use the manager parameter to ensure the Situations only contain events from the same manager. In general, and by default, you should comment out the partition_by parameter.
Partitioning by components is not recommended
pre_partition: An alternative way of partitioning is to use pre_partition which allows you to specify a component field (from the list of specified components) around which the event stream will be partitioned before clustering occurs. The Alerts in the resulting Situations will each contain a single value for the component field chosen.
Significance
You can configure Tempus to only create Situations from alerts that meet a certain degree of constant significance based upon Poisson distribution calculations.
significance_test: Calculation that determines how significant a cluster of alerts or potential Situation must be for Tempus to detect it. The default, Poisson1, looks at the data of a single alert cluster to calculate how significant it is. The default is more likely to detect all significant alert clusters but with a higher risk of creating insignificant alert clusters. Use this option when your alerts originate from different networks or unrelated topologies. Poisson2 is a more thorough test that looks at an alert cluster and all alerts outside the cluster with a similar event rate. It is more likely to exclude all insignificant alert clusters but with a high risk of excluding significant alert clusters. Use this option if you expect all of your alerts to come from the same connected network.
Type: String
One of: Poisson1, Poisson2
Default: Poisson1
significance_threshold: Sets the maximum significance score in order for Tempus to create a Situation. The score is proportional to the probability that the alert cluster or potential Situation was coincidence. The lower the score, the more significant the cluster and the least likely it was a coincidence. The significance_threshold score ranges from 0-100.
Type: Integer
Default: 1
Tempus Example
Tempus appears in moog_farmd.conf as shown below:
Vertex Entropy
Vertex Entropy is a Cisco Crosswork Situation Manager algorithm that indicates the critical nodes within your network and their tendency to produce important events.
You can use Vertex Entropy if you want to cluster alerts into Situations based on their topological importance. Once the calculation is run against a topological map of the connected nodes in your network, it applies a Vertex Entropy value for each node or "vertex".
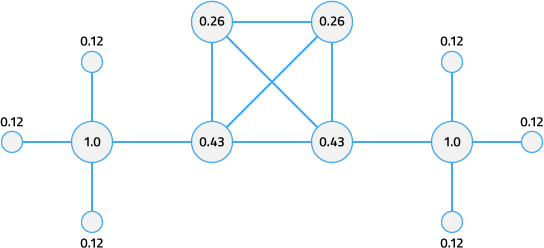
This diagram shows the Vertex Entropy values for a network of 12 connected nodes. A Vertex Entropy value of 1.0 indicates a node of highest topological importance.
Node - a device or base unit that forms part of a larger network. This is known as a 'vertex' in graph theory.
Link - a connection between two directly connected nodes. This is known as an 'edge' in graph theory.
Hop - a jump between two directly connected nodes.
Before You Begin
Before you perform the Vertex Entropy calculation and enable its associated features, ensure you have met the following requirements:
■ You have a map of the connected nodes in your network in a comma-separated value (.csv) file.
■ Your .csv topology file contains all of the nodes that you expect to send events.
■ You have run the topology builder utility to import your network topology. See Import a Network Topology.
Calculate the Vertex Entropy
To enable the features associated with Vertex Entropy, follow these steps:
1. Import your network topology .csv file into the database using the topology builder found at $MOOGSOFT_HOME/bin/utils:
The topology builder utility uses the source data to build a topology. If there is no pre-existing topology, topology builder records host names in the entity_catalog table. By default topology builder assigns each node to the 'Network' group and the 'Unix servers' competency. See Configuration Management Database for more details. The utility records the topological information in the moo g_reference.one_hop_topo and moog_reference.topo_nodes tables. See Import a Network Topology for more information.
2. Run the graph analyser from $MOOGSOFT_HOME/bin/utils to calculate the Vertex Entropy for the nodes or "vertices" in your network. This is a one-off calculation:
Graph analyser disregards any weight values included in your imported network topology. See Graph Analyser Command Reference.
Once the graph analyser has been run and each node has a Vertex Entropy value, you can start using these values in other areas of Cisco Crosswork Situation Manager.
Add a Vertex Entropy Filter
You can use Vertex Entropy as either a trigger or an exclusion filter in a Cookbook Recipe. These filters include or exclude alerts with similar importance in terms of network connectivity. For example, you can set a trigger so Cookbook considers alerts with a Vertex Entropy value of over 0.5 for Situation creation.
To do this, follows these steps:
1. Create a new Recipe under your Cookbook Moolet in $MOOGSOFT_HOME/config/moog_farmd.conf
2. Add the following value for the trigger parameter:
Alternatively, you can create an exclusion filter to exclude alerts with a Vertex Entropy value of less than 0.3 from Situation creation:
Add a Hop Limit
You can add a hop_limit filter as part of the matcher configuration in a CValueRecipe so Cookbook clusters alerts from nodes within a certain number of hops from each other. This can be used alongside Vertex Entropy trigger or exclusion filters.
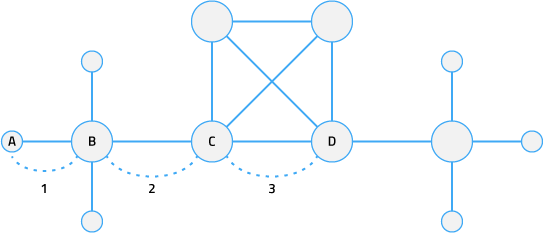 |
In this diagram, a hop limit of '3' means Cookbook includes alerts from all nodes between node A and node D.
The hop_limit filter ensures Cookbook only clusters alerts that originated from nodes that are close together. For more information, see Cookbo ok configuration.
Add a Seed Alert
You can add a seed_alert filter to a Recipe to ensure Cookbook only creates a new Situation if an alert has a specific Vertex Entropy value.
For example, if you only want to create Situations when there is an issue with the most critical nodes in your network, you can set the seed_alert filter to only create Situations from alerts with a Vertex Entropy value of 1.0:
If enabled, the initial seed alert must meet both the trigger and seed_alert conditions. For more information, see Cookbook configuration.
The seed_alert filter is not specific to Vertex Entropy and can be used for other conditions such as severity.
Cookbook Recipe Example
The example Cookbook Recipe below filters for alerts with a high Vertex Entropy:
Graph Analyser Command Reference
This is a reference for the graph_analyser utility used to calculate Vertex Entropy. The graph_analyser command-line utility accepts the following arguments:
| Argument |
Input |
Description |
| -h,--help |
- |
Display the graph_analyser utility syntax and option descriptions. |
| -l, --loglevel |
DEBUG | INFO | WARN | FATAL |
Log level controlling the amount of information that graph_analyser logs. Defaults to WARN. |
THE SOFTWARE LICENSE AND LIMITED WARRANTY FOR THE ACCOMPANYING PRODUCT ARE SET FORTH IN THE INFORMATION PACKET THAT SHIPPED WITH THE PRODUCT AND ARE INCORPORATED HEREIN BY THIS REFERENCE. IF YOU ARE UNABLE TO LOCATE THE SOFTWARE LICENSE OR LIMITED WARRANTY, CONTACT YOUR CISCO REPRESENTATIVE FOR A COPY.
The Cisco implementation of TCP header compression is an adaptation of a program developed by the University of California, Berkeley (UCB) as part of UCB’s public domain version of the UNIX operating system. All rights reserved. Copyright © 1981, Regents of the University of California.
NOTWITHSTANDING ANY OTHER WARRANTY HEREIN, ALL DOCUMENT FILES AND SOFTWARE OF THESE SUPPLIERS ARE PROVIDED “AS IS” WITH ALL FAULTS. CISCO AND THE ABOVE-NAMED SUPPLIERS DISCLAIM ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING, WITHOUT LIMITATION, THOSE OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE.
IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THIS MANUAL, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
Any Internet Protocol (IP) addresses and phone numbers used in this document are not intended to be actual addresses and phone numbers. Any examples, command display output, network topology diagrams, and other figures included in the document are shown for illustrative purposes only. Any use of actual IP addresses or phone numbers in illustrative content is unintentional and coincidental.
All printed copies and duplicate soft copies are considered un-Controlled copies and the original on-line version should be referred to for latest version.
Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices.
Cisco and the Cisco logo are trademarks or registered trademarks of Cisco and/or its affiliates in the U.S. and other countries. To view a list of Cisco trademarks, go to this URL: www.cisco.com/go/trademarks. Third-party trademarks mentioned are the property of their respective owners. The use of the word partner does not imply a partnership relationship between Cisco and any other company. (1110R)
© 2018 Cisco Systems, Inc. All rights reserved.
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)