Wiederherstellungsverfahren für Ultra-M AutoVNF Cluster Failure - vEPC
Download-Optionen
-
ePub (420.3 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
Dieses Dokument beschreibt die erforderlichen Schritte zur Wiederherstellung des Ultra Automation Services (UAS)- oder AutoVNF Cluster-Ausfalls in einem Ultra-M-Setup, das StarOS Virtual Network Functions (VNFs) hostet.
Hintergrundinformationen
Ultra-M ist eine vorkonfigurierte und validierte virtualisierte Mobile Packet Core-Lösung, die die Bereitstellung von VNFs vereinfacht.
Die Ultra-M-Lösung besteht aus den genannten VM-Typen:
- Auto-IT
- Automatische Bereitstellung
- UAS oder AutoVNF
- Element Manager (EM)
- Elastic Services Controller (ESC)
- Kontrollfunktion (CF)
- Sitzungsfunktion (SF)
Die High-Level-Architektur von Ultra-M und die beteiligten Komponenten sind in diesem Bild dargestellt:
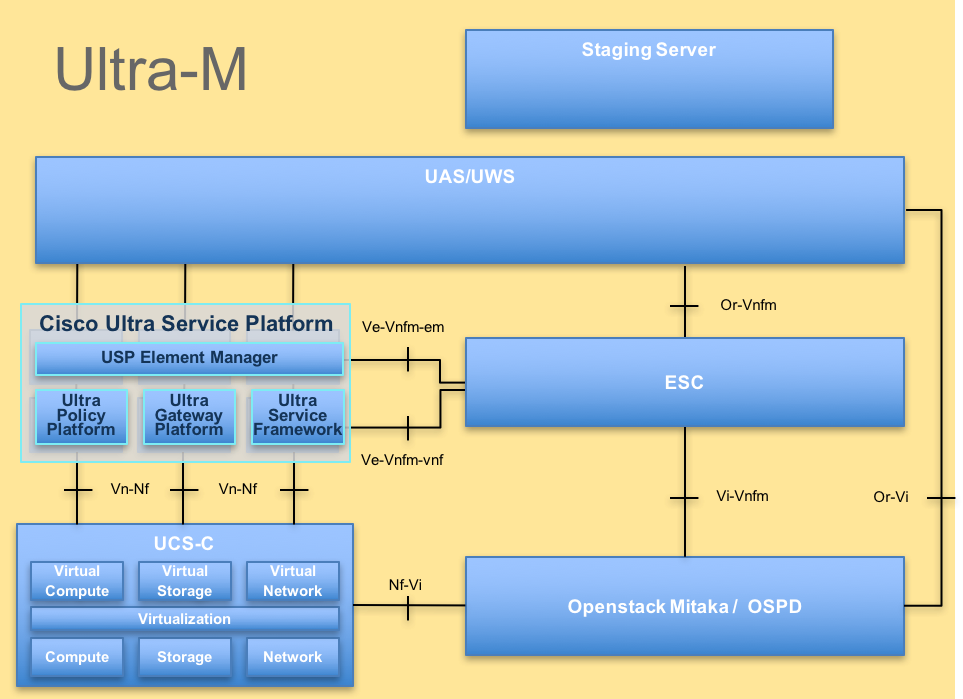 UltraM-Architektur
UltraM-Architektur
Dieses Dokument ist für Mitarbeiter von Cisco bestimmt, die mit der Cisco Ultra-M-Plattform vertraut sind.
Anmerkung: Die Ultra M 5.1.x-Version wird bei der Definition der in diesem Dokument beschriebenen Verfahren berücksichtigt.
Abkürzungen
| VNF | Virtuelle Netzwerkfunktion |
| KF | Kontrollfunktion |
| SF | Dienstfunktion |
| WSA | Elastischer Service-Controller |
| MOPP | Verfahrensweise |
| OSD | Objektspeicherplatten |
| Festplatte | Festplattenlaufwerk |
| SSD | Solid-State-Laufwerk |
| VIM | Manager für virtuelle Infrastruktur |
| VM | Virtuelles System |
| EM | Element-Manager |
| USA | Ultra-Automatisierungsservices |
| UUID | Universeller eindeutiger IDentifier |
Workflow des MoP
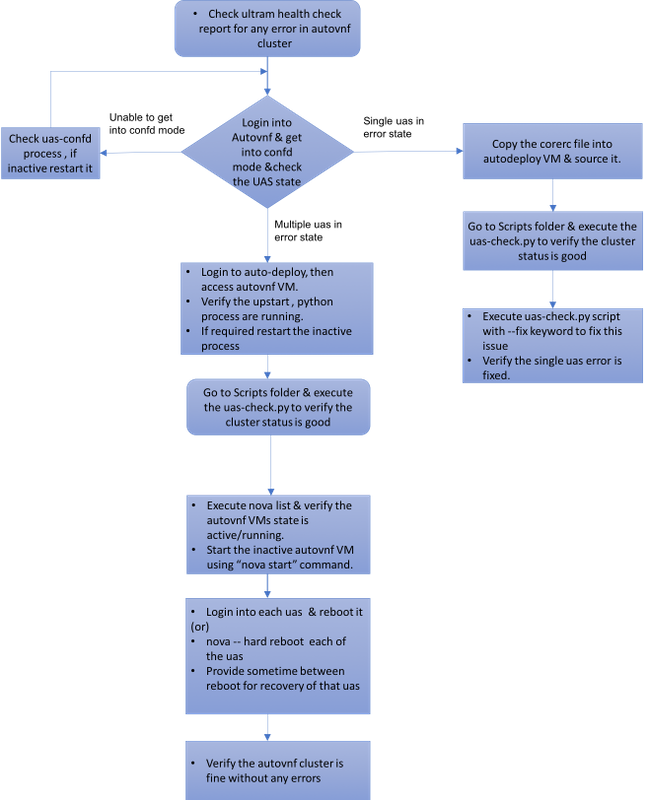
Fall 1: Wiederherstellung eines einzelnen Ausfalls des UAS-Clusters
Statusüberprüfung
1. Ultra-M Manager führt die Integritätsprüfung des Ultra-M-Knotens durch. Navigieren Sie zu den Berichten/var/log/cisco/ultram-health/directory, und navigieren Sie zum UAS-Bericht.
-
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. Der erwartete Status des UAS-Clusters ist wie dargestellt, wobei alle drei UAS aktiv sind.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive NA
Fehler beim Herstellen einer Verbindung mit dem Confd-Server, wenn Sie versuchen, eine Verbindung mit UAS herzustellen
1. In einigen Fällen können Sie keine Verbindung zum konfd-Server herstellen.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Failed to connect to server
2. Überprüfen Sie den Status des uas-config-Prozesses.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl status uas-confd
uas-confd stop/waiting
3. Wenn der konfd-Server nicht ausgeführt wird, starten Sie den Dienst neu.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl start uas-confd
uas-confd start/running, process 7970
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 172.16.180.9 using ssh on autovnf1-uas-0
UAS aus Fehlerzustand wiederherstellen
1. Bei Ausfall eines AutoVNF im Cluster zeigt der UAS-Cluster eines der UAS im Fehlerstatus an.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive error
2. Kopieren Sie die corerc-Datei (rc-Datei Ihrer VNF) von/home/stack im OSPD-Server zu AutoDeploy und beziehen Sie sie.
3. Überprüfen Sie den Status Ihrer UAS/AutoVNF mithilfe des Skripts uas-check.py . autovnf1 ist der AutoVNF-Name.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1
2017-11-17 14:52:20,186 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:22,172 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:22,172 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:22,172 - INFO: Check completed, AutoVNF cluster has recoverable errors
4. Wiederherstellen der UAS mit der Verwendung von uas-check.py Skript und add —fix Schlüsselwort.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1 --fix
2017-11-17 14:52:27,493 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:29,215 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:29,215 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:29,215 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-17 14:52:29,386 - INFO: Creating instance 'autovnf1-uas-2' and attaching volume 'autovnf1-uas-vol-2'
2017-11-17 14:52:47,600 - INFO: Created instance 'autovnf1-uas-2'
5. Sie sehen, dass das neu erstellte USV aktiv ist und Teil des Clusters ist.
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.13 alive NA
Fall 2: Alle drei UAS (AutoVNF) befinden sich im Fehlerstatus
1. Ultra-M Manager führt die Zustandsprüfung des Ultra-M-Knotens durch.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA,Node: 172.16.180.9, Status: error, Role: NA,Node: 172.16.180.10, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. Wie in der Ausgabe festgestellt, meldet der Ultra-M-Manager einen Fehler für AutoVNF und zeigt an, dass sich alle drei UAS des Clusters im Fehlerstatus befinden.
Überprüfen Sie den Zustand von UAS mit uas-check.py Skript
1. Melden Sie sich bei Auto-Deploy an, und prüfen Sie, ob Sie auf AutoVNF UAS zugreifen und den Status abrufen können.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts$ ./uas-check.py auto-vnf autovnf1 --os-tenant-name core
2017-12-05 11:41:09,834 - INFO: Check of AutoVNF cluster started
2017-12-05 11:41:11,342 - INFO: Found 3 ACTIVE AutoVNF instances
2017-12-05 11:41:11,343 - INFO: Check completed, AutoVNF cluster is fine
2. Von Auto-Deploy, Secure Shell (SSH) zu AutoVNF-Knoten und in den konfd-Modus. Überprüfen Sie den Status mit show uas.
ubuntu@auto-deploy-iso-590-uas-0:~$ ssh ubuntu@172.16.180.9
password:
autovnf1-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
----------------------------
172.16.180.9 error NA
172.16.180.10 error NA
172.16.180.12 error NA
3. Es wird empfohlen, den Status aller drei UAS-Knoten zu überprüfen.
Überprüfen des Status der virtuellen Systeme auf OpenStack-Ebene
Überprüfen Sie den Status der AutoVNF VMs in der Nova-Liste. Falls erforderlich, führen Sie nova start aus, um das Abschalten der VM zu starten.
[stack@pod1-ospd ultram-health]$ nova list | grep autovnf
| 83870eed-b4e9-47b3-976d-cc3eddecf866 | autovnf1-uas-0 | ACTIVE | - | Running | orchestr=172.16.180.12; mgmt=172.16.181.6
| 201d9ce5-538c-42f7-a46c-fc8cdef1eabf | autovnf1-uas-1 | ACTIVE | - | Running | orchestr=172.16.180.10; mgmt=172.16.181.5
| 6c6d25cd-21b6-42b9-87ff-286220faa2ff | autovnf1-uas-2 | ACTIVE | - | Running | orchestr=172.16.180.9; mgmt=172.16.181.13
Zookeeper-Ansicht überprüfen
1. Überprüfen Sie den Zustand des Zoowärters, um den Modus als Führer zu überprüfen.
ubuntu@autovnf1-uas-0:/var/log/upstart$ /opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
2. Zookeeper sollte normalerweise oben sein.
Fehlerbehebung in AutoVNF - Prozesse und Aufgaben
1. Identifizieren Sie den Grund für den Error-Status der Knoten. Damit AutoVNF ausgeführt werden kann, müssen eine Reihe von Prozessen wie folgt eingerichtet und ausgeführt werden:
AutoVNF
uws-ae
uas-confd
cluster_manager
uas_manager
ubuntu@autovnf1-uas-0:~$ sudo initctl list | grep uas
uas-confd stop/waiting ====> this is not good, the uas-confd process is not running
uas_manager start/running, process 2143
root@autovnf1-uas-1:/home/ubuntu# sudo initctl list
....
uas-confd start/running, process 1780
....
autovnf start/running, process 1908
....
....
uws-ae start/running, process 1909
....
....
cluster_manager start/running, process 1827
....
.....
uas_manager start/running, process 1697
......
......
2. Vergewissern Sie sich, dass diese Python-Prozesse ausgeführt werden:
uas_manager.py
cluster_manager.py
usp_autovnf.py
root@autovnf1-uas-1:/home/ubuntu# ps -aef | grep pyth
root 1819 1697 0 Jun13 ? 00:00:50 python /opt/cisco/usp/uas/manager/uas_manager.py
root 1858 1827 0 Jun13 ? 00:09:21 python /opt/cisco/usp/uas/manager/cluster_manager.py
root 1908 1 0 Jun13 ? 00:01:00 python /opt/cisco/usp/uas/autovnf/usp_autovnf.py
root 25662 24750 0 13:16 pts/7 00:00:00 grep --color=auto pyth
3. Wenn sich einer der erwarteten Prozesse nicht im Start-/Ausführungszustand befindet, starten Sie den Prozess neu, und überprüfen Sie den Status. Wenn der Fehlerstatus immer noch angezeigt wird, befolgen Sie die im nächsten Abschnitt beschriebenen Schritte, um dieses Problem zu beheben.
Korrektur für mehrere UAS im Fehlerzustand
1. nova —hard reboot <Name der VM> von OSPD, geben Sie etwas Zeit für die Wiederherstellung dieser VM, bevor Sie mit der nächsten UAS fortfahren. Führen Sie dies auf allen UAS VMs aus.
Oder
2.Melden Sie sich bei jedem der UAS an, und verwenden Sie sudo reboot. Warten Sie auf die Wiederherstellung, und fahren Sie dann mit anderen UAS VMs fort.
Aktivieren Sie bei Transaktionsprotokollen die Option:
/var/log/upstart/autovnf.log
show logs xxx | display xml
Auf diese Weise wird das Problem behoben und der Zustand "UAS from Error" wiederhergestellt.
1. Überprüfen Sie dies mit dem Bericht ultram_health_check.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | :-) |
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
Beiträge von Cisco Ingenieuren
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)