Einleitung
Dieses Dokument beschreibt die Fehlerbehebung bei Problemen mit hoher Festplattenspeichernutzung für das /dev/vda3-Dateisystem in RCM.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über folgende Kenntnisse verfügen:
- Systemarchitektur und -verwaltung von StarOS Control and User Plane Separation (CUPS).
- Grundlegende Linux/Unix-Befehle zur Überwachung der Dateisystem- und Festplattennutzung.
Verwendete Komponenten
Dieses Dokument ist nicht auf bestimmte Software- und Hardware-Versionen beschränkt.
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Überblick
In Cisco Ultra Packet Core-Bereitstellungen mit Control und User Plane Separation (CUPS) spielt der Redundancy Control Manager (RCM) eine entscheidende Rolle für Betrieb und Management der Kontrollebene. Eine stabile Auslastung des Dateisystems auf RCM-Knoten ist wichtig, um einen reibungslosen Betrieb der Protokollierung, Überwachung und Teilnehmersitzungsverwaltung sicherzustellen.
Eine hohe Auslastung des Festplattenspeichers im Root-Dateisystem (/dev/vda3) kann zu Systeminstabilität, Fehlern bei Protokollschreibvorgängen oder sogar einem Neustart des Dienstes führen, wenn diese Option nicht aktiviert ist. In diesem Artikel werden die Analyse, die Schritte zur Fehlerbehebung und die vorbeugenden Maßnahmen zur Vermeidung einer hohen Festplattenauslastung in RCM-Knoten beschrieben.
Analyse und Beobachtung
Bei der Überwachung wurde festgestellt, dass der RCM-Knoten eine Auslastung von 72 % im Root-Dateisystem erreichte.
Snapshot der Festplattenauslastung
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 27G 11G 72% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Bei weiteren Untersuchungen wurde festgestellt, dass die Journalprotokolle unter /var/log/journal/ erheblich gestiegen waren. Allein die im Juli generierten Protokolle hatten einen Speicherbedarf von ~3 GB.
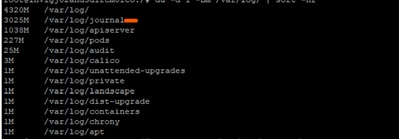
Fehlerbehebung
Um die Festplattenauslastung unter Kontrolle zu bringen, wurden die erforderlichen Schritte zur Änderungsimplementierung durchgeführt:
Schritt 1: Alte Protokolle mit journalctl Vacuum bereinigen
Nur die letzten 2 Wochen der Protokolle aufbewahren:
sudo journalctl --vacuum-time=2weeks
Oder begrenzen Sie die Journalgröße (z. B. nur 600 MB):
sudo journalctl --vacuum-size=600M
Schritt 2: Konfigurieren der Journalaufbewahrung zur Verhinderung zukünftiger Ereignisse
Journalkonfiguration bearbeiten:
vi /etc/systemd/journald.conf
Parameter hinzufügen/ändern:
MaxRetentionSec=2week
Konfiguration anwenden:
sudo systemctl restart systemd-journald
Optionaler Schritt 3: Beheben des Neustartfehlers
Wenn Sie den Dienst systemd-journald in Schritt 2 neu starten, erhalten Sie einen besorgten Fehler:
Error : Failed to allocate directory watch: Too many open files
-
systemd-journald verwendet inotify, um Protokollverzeichnisse auf Änderungen zu überwachen.
-
Jede Beobachtung oder Überwachung setzt Zählungen für bestimmte Kernelgrenzen fest.
Im problematischen RCM sind folgende Stromgrenzwerte definiert:
cat /proc/sys/fs/inotify/max_user_watches
501120
cat /proc/sys/fs/inotify/max_user_instances
128
ulimit -n
1024
Aus der gesammelten Ausgabe:
- Max. Identifizierungsuhren: 501120
- Max. Inotify-Instanzen: 128
Dateideskriptorlimit für Journal öffnen: 1024
Entweder (oder alle) der Ausgabewerte Grenze könnte getroffen haben, um den Fehler zu führen. Wir sammelten also den aktuell verwendeten Wert und verglichen ihn mit dem gesammelten Leistungsgrenzwert:
sudo lsof -p $(pidof systemd-journald) | wc -l
65
echo "Root inotify instances: $(sudo find /proc/*/fd -user root -type l -lname 'anon_inode:inotify' 2>/dev/null | wc -l) / $(cat /proc/sys/fs/inotify/max_user_instances)"
Root inotify instances: 126 / 128
Es sieht so aus, als ob der Root bereits 126 von 128 erlaubten Inotify-Instanzen verwendet. Das lässt Journald fast keinen Raum, um eine neue Inotify-Instanz zu erstellen, wenn wir sie neu starten.
So beheben Sie den Fehler: können wir den Wert max_user_instance erhöhen und dann den Dienst neu starten:
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
Überprüfung nach der Änderung
Nach der Übernahme der Änderungen ging die Festplattenauslastung auf 61 % zurück, wodurch der Knoten wieder in den normalen Betriebszustand zurückversetzt wurde.
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 23G 15G 61% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
Empfehlung
-
Implementieren Sie dieselbe Konfiguration für alle RCM-Knoten in der Bereitstellung, um die Festplattenauslastung innerhalb sicherer Grenzen zu halten.
-
Versetzen Sie den Ziel-RCM vor dem Durchführen der Änderungen immer in den Standby-Modus, um Beeinträchtigungen des aktiven Datenverkehrs zu vermeiden.
-
Regelmäßige Überwachung der /dev/vda3-Nutzung und des Wachstums von Journalprotokollen im Rahmen proaktiver Systemstatusprüfungen
 Feedback
Feedback