Fehlerbehebung bei Inter-Rack-Replikationsfehlern mit Fehlercode "424-Geo-Replikation: Checksum Mismatch"
Download-Optionen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
In diesem Dokument werden verschiedene Untersuchungsmethoden zur Fehlerbehebung bei Unterschieden bei der Prüfsumme für die Georeplikation zwischen dem lokalen und dem Remote-Rack beschrieben.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in folgenden Bereichen verfügen:
- Geo-Redundanz in der Sitzungsmanagement-Funktion (SMF)
- SMF
- TCP-Verbindungsbeendigung (Transmission Control Protocol)
Verwendete Komponenten
Dieses Dokument ist nicht auf bestimmte Software- und Hardware-Versionen beschränkt.
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Hintergrundinformationen
Was ist Georedundanz in SMF?
-
SMF unterstützt die geografische (Geo)-Redundanz (GR) im Aktiv-Aktiv-Modus.
-
GR-Setup ist auch für die Replikation von
etcd/cacheDaten auf das Standby-Rack verantwortlich. -
SMF unterstützt die primäre/Standby-Redundanz, bei der Daten von der primären auf die Standby-Instanz repliziert werden.
-
Wenn die primäre Instanz ausfällt, wird die Standby-Instanz zur primären Instanz und übernimmt den Betrieb.
-
Um eine optimale Übertragungsrate zu erreichen, können zwei primäre/Standby-Paare eingerichtet werden, wobei jeder Standort den Datenverkehr aktiv verarbeitet und der Standby-Modus als Backup für den Remote-Standort fungiert.
Geo-Replikations-Pod
-
Geo-Replikations-Pod wird für die Kommunikation zwischen Racks und Standorten sowie zur Überwachung von POD/BFD im Rack eingeführt.
-
Zwei Instanzen von GR-POD werden auf jedem Rack/Standort ausgeführt
-
Zwei GR-PODs funktionieren im Aktiv/Standby-Modus.
-
GR PODs werden auf dem Proto-Knoten/VM erzeugt
-
GR POD verwendet zwei virtuelle IP-Adressen (VIPs)
-
Intern - VIP für Inter-POD-Kommunikation (innerhalb des Racks)
-
External-VIP für die GR POD-Kommunikation zwischen Racks/am Standort
-
Für GR POD konfigurierte VIPs können auf einem der Protoknoten/virtuellen Systeme aktiv sein.
-
Wenn der aktive GR POD neu gestartet wird, wird VIP auf einen anderen Proto-Knoten/VM umgeschaltet, und der Standby-GR POD, der auf dem anderen Proto-Knoten/VM ausgeführt wird, kann aktiv werden.
GR-POD-Referenzkonfiguration:
smf# show running-config instance instance-id 1 endpoint geo
Thu Oct 20 06:25:25.319 UTC+00:00
instance instance-id 1
endpoint geo
replicas 1
nodes 2
interface geo-internal
vip-ip a.b.c.d vip-port 7001
exit
interface geo-external
vip-ip Y.Y.Y.Y vip-port 7002
exit
exit
exit
Identifizieren des aktiven Geo Pod und des Standby Geo Pod
Um den aktiven Geo-Pod zu identifizieren, müssen Sie in den Geo-Pod-Protokollen nach Fehlern oder Ereignissen suchen.
Aktiver POD:
user@smf-ims-master-1:~$ kubectl logs georeplication-pod-0 -n smf-smfix1|tail -3
[ERROR] [grcacachepod.go:339] [gr_deferred_sync.application.app] Periodic Sync: Total time taken to sync IPAM cache pod data: 500.563723ms”
[ERROR] [GeoAdminStreamClient.go:276] [gr_pod.geo_admin_client.app] no one waiting for received response for txnID:CP0XXXOKCP0XXX-SMF-IMS-smfix1111163550 of host=geo-admin-pod2
Standby-Pod:
user@cp0xxx-smf-ims-master-1:~$ kubectl logs georeplication-pod-1 -n smf-smfix1|tail -3
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
Funktionen des GR POD
GR-PODs replizieren die ETCD- und Cache-POD-Daten am Standort
Verwenden Sie die CLI, um Replikationsdetails für ETCD- und Cache-Pod-Daten anzuzeigen:
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Thu Oct 20 07:11:52.409 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- -------
1 ETCD 1666249907
IPAM CACHE 1666249907
NRFMgmt CACHE 1666249907
Lokale Instanzrollen in ETCD verwalten
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.2, with role as PRIMARY
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.1, with role as STANDBY
Überwachen des Status des lokalen Standorts (POD-Status/BFD-Status)
[cp0xxx-smf-ims/smfix1] smf# show running-config geomonitor podmonitor pods smf-service
Thu Oct 20 07:36:41.280 UTC+00:00
geomonitor podmonitor pods smf-service
retryCount 2
retryInterval 900
retryFailOverInterval 500
failedReplicaPercent 60
Standort-Rollen
PRIMARY : Die Site ist bereit und nimmt aktiv Datenverkehr für die angegebene Instanz auf.
STANDBY: Der Standort befindet sich im Standby-Modus und kann Datenverkehr aufnehmen, jedoch nicht für eine bestimmte Instanz.
STANDBY_ERROR: Die Site ist in einem Problem, nicht aktiv und nicht bereit, Datenverkehr für eine bestimmte Instanz aufzunehmen.
FAILOVER_INIT: Der Standort hat mit einem Failover begonnen und ist nicht in der Lage, Datenverkehr aufzunehmen, Pufferzeit von 2 s, damit die Anwendung ihre Aktivität abschließen kann.
FAILOVER_COMPLETE: Der Standort hat den Failover abgeschlossen und versucht, den Peer-Standort über den Failover für die angegebene Instanz zu informieren. Pufferzeit von 2s.
FAILBACK_STARTED: Das manuelle Failover wird vom Remote-Standort für eine bestimmte Instanz mit einer Verzögerung ausgelöst.

Anmerkung: Cache/ETCD-Replikation und CDL-Replikation würden auch in allen Rollen durchgeführt. Wenn GR-Verbindungen ausfallen/ein periodischer Heartbeat ausfällt, werden GR-Trigger ausgesetzt.
GR-Trigger
CLI zum Überprüfen der GR-Instanzrollen im Rack
Show role instance id 1
Show role instance id 2
CLI zum Zurücksetzen der Rolle von Standby-Fehler in Standby
Geo reset-role instance-id <1/2> role standby
Fehler: CLI zu Switch-Rolle von Standby zu Standby
Geo switch-role instance-id <1/2> role standby failback-interval 0
CLI für Switch-Rolle von Standby zu Primär
Um diese Switch-Rolle zu initiieren, müssen Sie die CLI vom Rack aus auslösen, das eine der Instanzen als primär hat.
Geo switch-role instance-id <1/2> role standby failback-interval 0
Anmerkung: Szenario des sonnigen Tages: Rack1-Instanz1-Primär, Instanz2-Standby Rack2-Instanz1-Standby, Instanz2-Primär.
Regentag-Szenario: Rack1-Instanz 1 und Instanz 2-primär; Rack2-Instanz 1 und Instanz 2-standby.
Terminierung der TCP-Verbindung
Das TCP-Protokoll ist ein verbindungsorientiertes Protokoll, das bedeutet, dass eine Verbindung aufgebaut und aufrechterhalten wird, bis die Anwendungsprogramme an jedem Ende den Austausch von Nachrichten beendet haben. TCP arbeitet mit dem Internetprotokoll (IP) zusammen.
TCP-Handshake wird auch als 3-Wege-Handshake bezeichnet. Wenn eine Verbindung vom Client-Rechner zum Server-Rechner initiiert wird, tauschen Client und Server SYN- und ACK-Pakete aus, bevor die Daten übertragen werden.
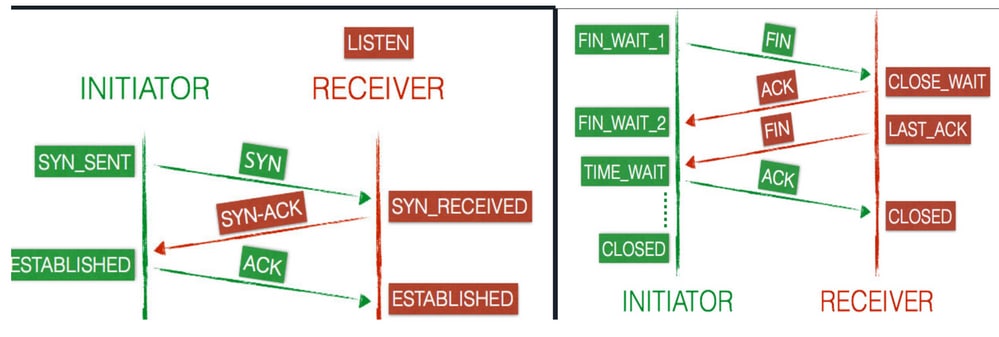 Transmission Control Protocol: Client- und Server-Verbindungsstatus
Transmission Control Protocol: Client- und Server-Verbindungsstatus
Eine Verbindung durchläuft eine Reihe von Zuständen während ihres gesamten Lebens. Die Bundesstaaten sind: LISTEN, SYN-SENT, SYN-RECEIVED ESTABLISHED, FIN-WAIT-1 FIN-WAIT-2,,CLOSE-WAITCLOSING, LAST-ACK, TIME-WAITCLOSED, und der fiktive Zustand ist nicht mehr zu verwechseln.
- Wenn eine neue TCP-Verbindung geöffnet wird, sendet der Client (Initiator) ein
SYNPaket an den Server (Empfänger) und aktualisiert seinen Status aufSYN-SENT. - Der Server sendet dann eine Antwort
SYN-ACKan den Client, der seinen Verbindungsstatus inSYN-RECEIVEDändert.
- Der Client antwortet mit einem
ACKund die Verbindung wird auf beiden Endpunkten alsESTABLISHEDmarkiert, nun sind der Client und der Server bereit, Daten zu übertragen.
- Der Client sendet ein
FINPaket an den Server und aktualisiert seinen Status aufFIN-WAIT-1. - Der Server empfängt die Beendigungsanforderung vom Client und antwortet mit einem
ACK. Nach der Antwort gelangt der Server in einenCLOSE-WAITZustand. - Sobald der Client die Antwort vom Server erhält, geht er in den
FIN-WAIT-2Zustand über. - Der Server befindet sich noch im
CLOSE-WAITStatus und wird unabhängig von einer FIN weitergeleitet, die den Status aufLAST-ACKaktualisiert. - Nun erhält der Client die Beendigungsanforderung und antwortet mit einem
ACK, woraus sich einTIME-WAITZustand ergibt. - Der Server ist nun fertig und stellt die Verbindung auf
CLOSEDsofort ein. - Der Client verbleibt maximal vier Minuten im
TIME-WAITZustand, bevor die VerbindungCLOSEDhergestellt wird.
Problem
Szenario 1: Die Georeplikations-Prüfsumme für Instanz-ID 1 weist einen IPAM-Cache und eine NRFMgmt-Cache-Prüfsummenkonflikt auf.
Der Geo-Replikationsstatus smfix1/smfix2 ist fehlgeschlagen (Replikation zwischen Racks an Remote-Standort fehlgeschlagen).
FEHLER: Admin-Befehl fehlgeschlagen [pod internal-gr-pod-1, URL http://X.X.0.0:15290/commands] mit Code 424, Meldung fehlgeschlagen: Replikationsprüfsumme stimmt nicht überein.
Das Problem wurde am 23. August um 00:36:19 als "Inter-Rack-Replikation fehlgeschlagen" beobachtet.
From CEE alerts:
Inter_Rack_Replication 9ca45362a049 critical 08-23T00:36:19 System
Inter rack replication to Remote Site failed
Aus dieser CLI-Ausgabe geht hervor, dass Instanz-ID 1 Prüfsummen-Diskrepanzen für die IP-Adressverwaltung (IPAM) und den NRF-Cache aufweist.
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:27.762 UTC+00:00
checksum-details
-- --- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1662367102
NRFMgmtCACHE 1662367102
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:30.767 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1661214831
NRFMgmtCACHE 1661214831
Szenario 2: Geo-Replikationsprüfsumme für Instanz-ID 2 weist ETCD-Prüfsummenkonflikt auf
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:37.852 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
2 ETCD 1661214828
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:39.118 UTC+00:00
checksum-details
-- ---- -------
ID Type Checksum
-- ---- --------
2 ETCD 1662367107
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
3. Szenario: Fehler beim Herstellen der TCP-Verbindung mit dem Remote-Standort
Rack1-smfix1-Protokolle:
Aus GR Pod-Protokollen können Sie beobachten, wie der Aktualisierungs-Cache-POD-Prüfpunkt gestoppt wird, die sofortige Replikation fehlgeschlagen ist und kein Remote-Server verfügbar ist.
2022/08/23 00:34:00.035 [ERROR] [grreplicationclient.go:201] [gr_pod.geo_replication_client_stream.app] HandleImmediateReplication failed: [RPCNoRemoteHostAvailable] No remote host available for this request
2022/08/23 00:34:02.086 [ERROR] [grreplicationclient.go:466] [gr_pod.geo_replication_client_stream.app] Stream disconnected, closing logQueueCounter=0xc0093b08b0
2022/08/23 00:34:04.124 [ERROR] [GeoAdminStreamClient.go:215] [gr_pod.geo_admin_client.app] ADMIN(geo-admin-pod2) : exit outgoing request loop stream closed
2022/08/23 00:34:43.623 [ERROR] [grreplicationclient.go:270] [gr_pod.geo_replication_client_stream.app] Update etcd checkpointing stopped for grinstance: 1
Rack2-smfix2-Protokolle:
Aus GR Pod-Protokollen können Sie beobachten, wie die Verbindung zum Stream unterbrochen wurde und die CACHE-Prüfsummendifferenz größer als erwartet ist.
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:62] [gr_pod.geo_replication_server_stream.app] Stream disconnected, closing logQueueCounter=0xc001b85d08
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:314] [gr_pod.geo_replication_server_stream.app] handleCachePodSyncRequests : Stream closed of connection=0xc002ee08f0
2022/08/23 00:34:56.751 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661214892]
2022/08/23 00:34:56.678 [ERROR] [etcdAuditReplHandler.go:196] [gr_pod.application.app] SyncETCDData periodic sync : For ETCD [C.GR.1.] key, the remote site data size is: [10833]
2022/08/23 00:36:56.757 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661215012]
Szenario 4. Auf Server mit Master-Knoten beobachteter DIMM-Fehler
ECC-Fehler tritt auf dem Master-1-Knoten auf, der Geo-Replikation-Pod-0 etwa zur gleichen Zeit hostet wie der Fehler Stream getrennt.
CP0XXX-Server9-02# scope sel
CP0XXX-Server9-02 /sel # show entries
Time Severity Description
----------------------- ------------- ----------------------------------------
2022-08-23 00:33:59 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
2022-08-22 22:59:45 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
- Die Kommunikation zwischen dem Geo-Replikations-Pod auf Rack1 und dem Geo-Replikations-Pod auf Rack2 ist unterbrochen.
-
DIMM-Fehler tritt auf einem der Master-Knoten auf, wodurch die Stream-Verbindung zwischen Rack1 und Rack2 unterbrochen wurde.
-
Vom Rack1-Geo-Replication-Pod konnte keine Anforderung an Rack2 repliziert oder gesendet werden. Der Fehler "Remote Host" ist nicht verfügbar.
-
Bei der Ausgabe des netstat-Befehls für Rack1 und Rack2 für den 7002-Port wurde festgestellt, dass der Rack1-Socket im Status "FIN_WAIT1" und der Rack2-Socket im Status "SYN_RECV" feststeckt.
-
Auf der Serverseite, d. h. auf Rack2, ist der Socket im Zustand SYNC_RECV fixiert, und die neu erstellte Verbindung geht ebenfalls in den Zustand SYNC_RECV und kann nicht miteinander kommunizieren.
-
Die Verbindung befindet sich im SYN_RECV-Zustand, da der Kernel ein SYN-Paket für einen Port empfangen hat, also im LISTENING-Modus, aber das andere Ende hat nicht mit ACK geantwortet.
smfix2-Master-2 hat eine externe VIP (Y.Y.Y.Y:7002) installiert, aber der TCP-Verbindungsstatus des Remote-Hosts (SMFIX1) ist im Status SYN_RECV und nicht im Status ESTABLISHED. a.b.c.d und a.b.c.e sind Master-1- und 2-IPs von smfix1 (Rack1).
user@cp0xxx-smf-ims-master-2:~$ netstat -anp | grep 7002
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:35542 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:47046 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:36248 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:42686 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:38248 SYN_RECV -
Status der externen Geo-VIP-TCP-Verbindung auf smfix1 (Rack1) für Remote-Peer im Zustand FIN-WAIT1:
user@cp0xxx-smf-ims-master-1:~$ netstat -anp | grep 7002
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN -
tcp 0 1 a.b.c.d:60866 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:52274 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:59674 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:47926 Y.Y.Y.Y:7002 FIN_WAIT1 -
Lösung
Rack 1:
-
Löschen Sie zunächst den Standby-Geo-Pod, warten Sie, bis der Pod wiederhergestellt ist, und löschen Sie dann den aktiven Geo-Pod. Melden Sie sich bei Master VIP an, und löschen Sie den GR-Pod:
kubectl delete pod-n
Rack 2:
- Löschen Sie zunächst den Standby-Geo-Pod, warten Sie, bis der Pod wiederhergestellt ist, und löschen Sie dann den aktiven Geo-Pod.
-
Überprüfen Sie den Geo-Replikationsstatus aus der CLI, und veröffentlichen Sie das Löschen von Geo-Pods.
show georeplication-status
- Nachdem Sie den Geo-Pod auf Rack1 und Rack2 gelöscht haben, wird Ihnen die externe Geo-VIP angezeigt: Der TCP-Port wechselt in den Status "ETABLISHED".
- Georeplikationsstatus "Bestanden".
- Beim Replikationsstatus in den Racks wurde keine Ungleichheit bei der Prüfsumme festgestellt.
smfix2 (Rack2):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN 36854
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:46402 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 1a.b.c.e:54708 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:55152 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:46530 ESTABLISHED 36854/grpod
tcp 0 0 10.59.0.0:7002 10.59.0.0:46532 ESTABLISHED 36854/grpod
smfix1 (Rack1):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN 53932/grpod
tcp 0 0 a.b.c.d:46530 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 0 a.b.c.d:46402 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 17 a.b.c.d:46532 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
2. Status der Geo-Replikation:
[okcp0xx-smf-ims/smfix1] smf# show georeplication-status
result "pass"
[okcp0xx-smf-ims/smfix2] smf# show georeplication-status
result "pass"
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
05-Dec-2022
|
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Manasa G KambiCisco TAC Engineer
- Krishna Kishore D VCisco Technical Leader
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)