Einleitung
In diesem Dokument wird beschrieben, wie Instant Message and Presence (IM&P) High Availability in einer IM&P-Umgebung des Unternehmens funktioniert und wie Fehler behoben werden.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in folgenden Bereichen verfügen:
- Cisco Unified IM&P
- Cisco Jabber-Clients
Verwendete Komponenten
- Cisco Unified IM&P 10.0 und höher
- Cisco Jabber Clients 9.6 und höher
Die Informationen in diesem Dokument stammen aus den Komponenten einer bestimmten Laborumgebung. Alle in diesem Dokument verwendeten Komponenten wurden mit einer gelöschten (Standard-) Konfiguration gestartet. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Hochverfügbarkeit für IM und Presence
Der IM und Presence Service Server bietet eine hohe Verfügbarkeit oder Redundanz in Form von logischen Servergruppen in der CUCM-Konfiguration. Diese Konfiguration wird an IM und Presence übergeben und dann verwendet, um die Redundanz bei einem IM- und Presence-Service oder Serverausfall zu gewährleisten. Wenn ein HA-Ereignis eintritt, werden die Sitzungen des Endbenutzers vom ausgefallenen Server zum Backup verschoben. Wenn der Server wieder in den normalen Zustand versetzt wurde, werden die Benutzersitzungen entweder automatisch oder manuell vom Administrator zurückverschoben.
Konfiguration der Redundanzgruppe
Die Redundanzgruppe ist das logische Serverpaar, das die Zuweisung eines Servers zum IM- und Presence-Untercluster sowie die Konfiguration für HA ermöglicht. Um auf diesen Teil der Konfiguration zuzugreifen, finden Sie ihn auf der CUCM-Server-Webseite.
System > Presence-Redundanzgruppen
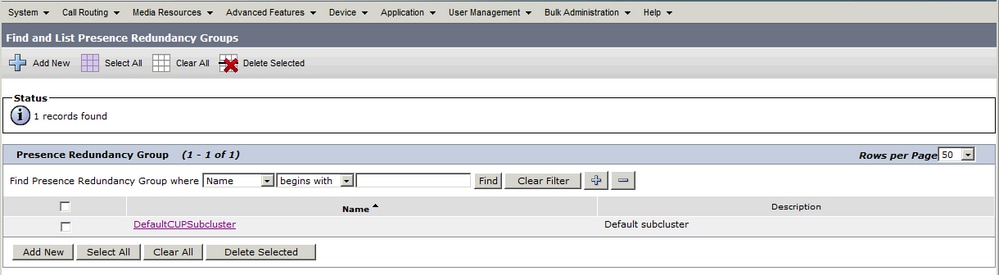
Wenn der Administrator den IM&P Publisher der Konfiguration System > Server auf dem CUCM hinzufügt und der IM&P-Server gespeichert wird, wird die Redundanzgruppe DefaultCUPSubCluster mit dem zugewiesenen Publisher erstellt.
Beim Erstellen sieht die Redundanzgruppe wie folgt aus:
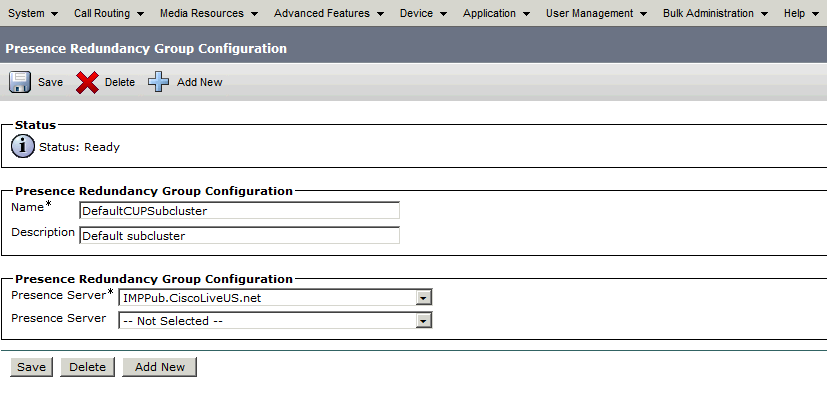
Diese Redundanzgruppe wird in das IM- und Presence-Subcluster übersetzt. Im aktuellen Zustand der Konfiguration der Redundanzgruppe in CUCM würde dies auf der Webseite für die IM- und Presence-Cluster-Topologie angezeigt:
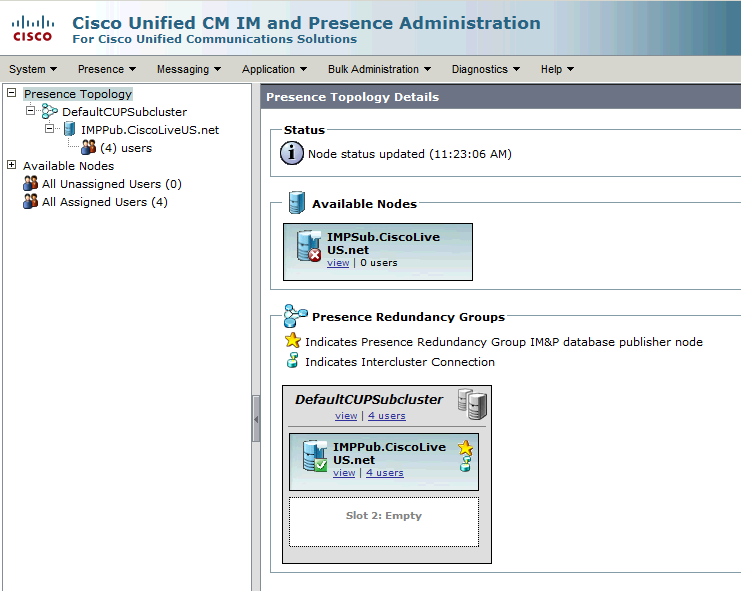
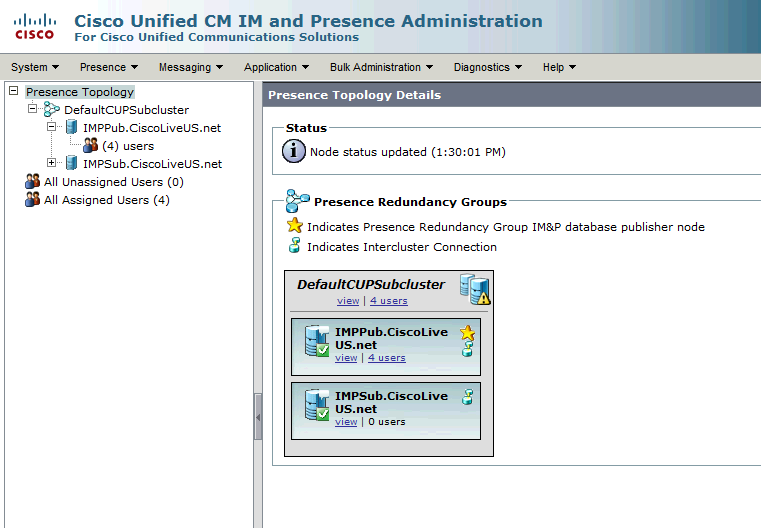
Sie sehen, dass der IM&P Publisher dem DefaultCUPSubcluster zugewiesen ist und der Subscriber-Server nicht. Der Grund hierfür ist, dass der IM&P-Subscriber-Server der Redundanzgruppe in der CUCM-Konfiguration nicht zugewiesen ist.
Weisen Sie den Abonnenten der Redundanzgruppe zu.
Um den Subscriber-Server der Redundanzgruppe zuzuweisen, wählen Sie den Subscriber-Server aus dem Dropdown-Menü aus, und speichern Sie die Konfigurationsänderung.
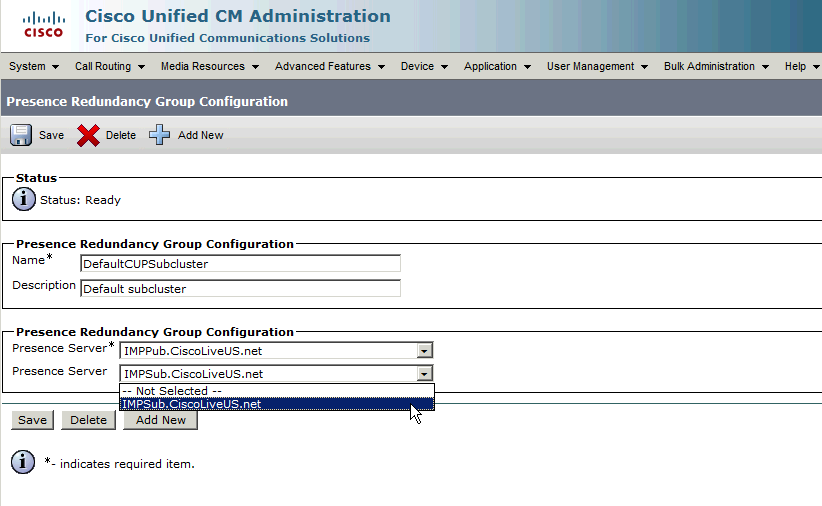
Wenn der IM&P-Subscriber zur Redundanzgruppe hinzugefügt wurde:
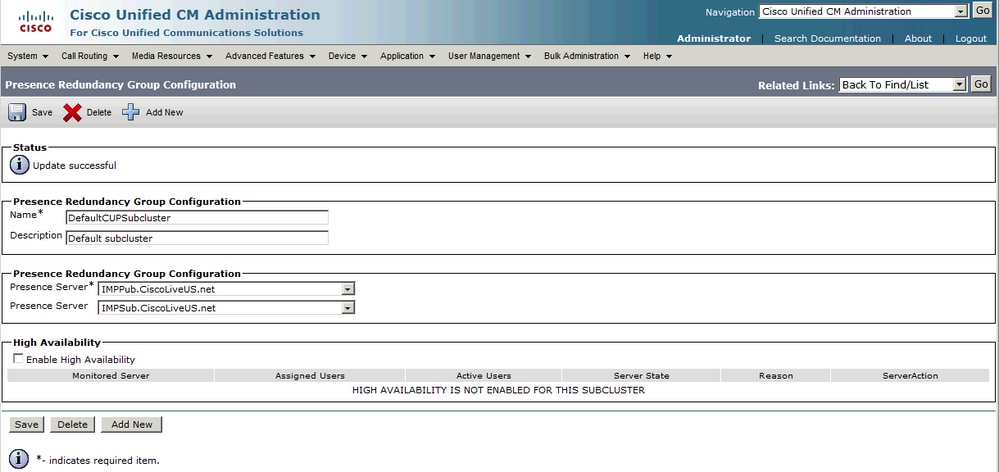
Nach dem Hinzufügen des sekundären Knotens (des Subscribers) können Sie die Option für hohe Verfügbarkeit auswählen. Um Hochverfügbarkeit zu aktivieren, müssen Sie nur das Kontrollkästchen Hochverfügbarkeit aktivieren auswählen und die Konfigurationsänderung speichern.
Nach Aktivierung von High Availability:
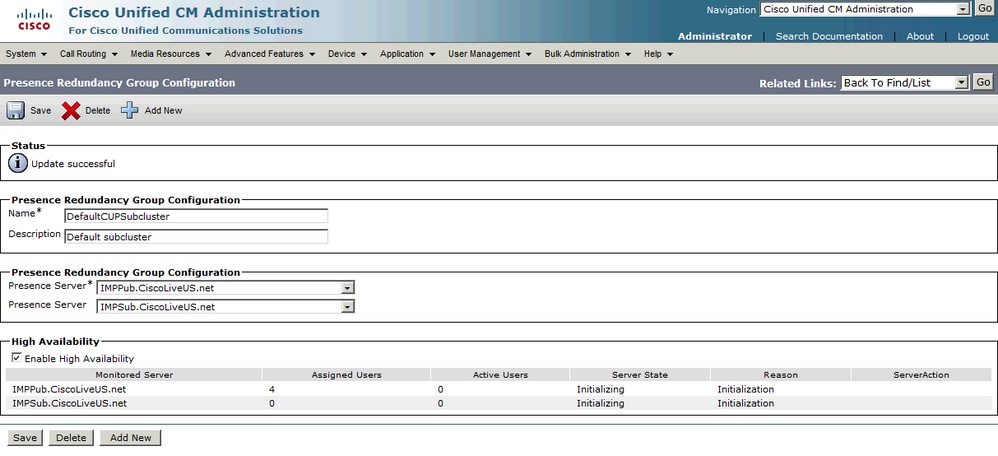
Auf der Seite werden dann Serverstatus und Grund automatisch aktualisiert. Wenn sich der Server in einem Initialisierungszustand befindet, bedeutet dies, dass die beiden Server miteinander kommunizieren können. Die Server überprüfen dann den Dienststatus, bevor der Status in den Status "Normal" wechselt. Wenn die beiden Server miteinander verbunden werden können und alle überwachten Dienste auf beiden Geräten aktiv sind, erhalten Sie den Status Normal-Normal. Das bedeutet, dass alle überwachten Dienste auf den IM&P-Servern aktiv sind.
Status der Normal-Normal-Redundanz-Gruppe:
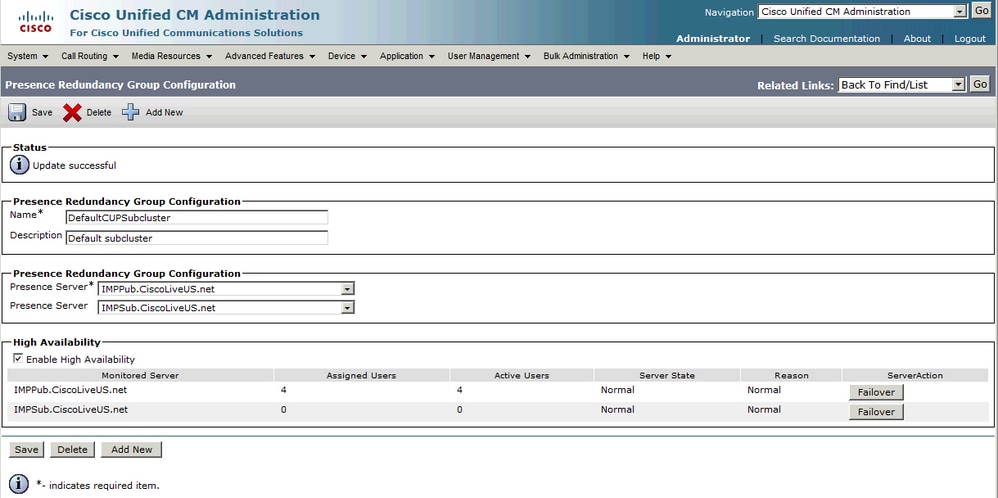
Normal-Normal High Availability State in der IM&P-Topologieseite:
Überwachte IM- und Presence-Services
Da verschiedene Bereitstellungsmodelle möglich sind: Nur IM, IM mit SIP/XMPP-Federation, IM mit Compliance, IM mit persistentem Chat, Nur Remote Call Control usw., ist die Liste der zu überwachenden Prozesse dynamisch. Standardmäßig werden diese Elemente immer überwacht, wenn HA aktiviert ist:
- IDS-Datenbank
- Presence Engine (falls aktiviert)
- XCP-Router
Der Server Recovery Manager überprüft, ob die Compliance (Message Archiver), der persistente Chat (Text Conference Manager), der SIP-Verbund (SIP Federation Connection Manager) und der XMPP-Verbund (XMPP Federation Connection Manager) konfiguriert und aktiviert sind.
Wenn beide konfiguriert und aktiviert sind, überwacht auch der Server Recovery Manager (SRM) diese Dienste.
Vorsicht: Bevor Sie mit einem Neustart eines oder mehrerer der überwachten Dienste fortfahren, müssen Sie die Hochverfügbarkeit in den Presence Redundancy Groups (DRS) auf dem CUCM-Server deaktivieren. Dasselbe gilt, wenn ein Neustart eines oder mehrerer IM&P-Knoten durchgeführt wird.
Benutzer-Failover-Prozess
Wenn ein Failover stattfindet (automatisch oder manuell), ist es wichtig, sich daran zu erinnern, dass das Benutzerkonto nicht von einem Server auf den anderen verschoben wird, sondern nur die Benutzersitzung in der Presence Engine. Bei Instant Messaging- und Presence-Versionen vor 10 Jahren wurde die Benutzerzuweisung von einem Server auf den anderen übertragen. Diese Benutzerverschiebung war für die Serverressourcen sehr kostspielig und hat zu der Last auf dem Server beigetragen. In Version 10.x und höher bleibt der Benutzer auf dem Server, dem er zugewiesen ist, zu Hause, und die Back-End-Benutzersitzung in der Presence Engine wird vom ausgefallenen Knoten zum Funktionsknoten verschoben. Der Benutzer muss Jabber nicht verlassen und sich erneut anmelden, wenn die Änderung mit dem Server Recovery Manager (SRM) erfolgt.
Timer für erneute Anmeldung des Jabber-Clients
Damit die Benutzersitzung auf dem sekundären IM&P-Knoten nach einem Failover-Ereignis vollständig aktiv wird, muss der Benutzer versuchen, sich über SOAP (Client Profile Agent) bei diesem Server anzumelden. Dies geschieht automatisch mit dem einmaligen Passwort, das von der IMDB-Datenbank übergeben wird. Da Anmeldungen für Ressourcen auf dem IM- und Presence-Server äußerst kostspielig sind, muss es möglich sein, Anmeldungen bei einem Failover-Ereignis zu drosseln. Diese Drosselung oder dieser Puffer ermöglicht allen Benutzern, sich beim sekundären Knoten anzumelden, ohne dass der Dienst für Benutzer auf dem sekundären Knoten unterbrochen wird. Die Mechanismen, die zur Drosselung von Benutzeranmeldungen verwendet werden, sind die Dienstparameter Client Re-Login Lower Limit (Unteres Limit) und Client Re-Login Upper Limit (Oberes Limit) Server Recovery Manager (SRM).
Unterer Grenzwert für Client-Neuanmeldung - Der Parameter, der die Mindestdauer (in Sekunden) definiert, die der Jabber-Client wartet, bevor der Client bei einem HA-Ereignis versucht, sich beim sekundären Server anzumelden.
Client Re-Login Upper Limit - Der Parameter, der die maximale Wartezeit (in Sekunden) definiert, die der Jabber-Client bei einem HA-Ereignis wartet, bevor der Client versucht, sich beim sekundären Server anzumelden.
Der Jabber-Client empfängt diese Parameter bei der Anmeldung am Server und speichert die Werte für die zukünftige Verwendung. Wenn Sie ein HA-Ereignis vom IM&P-Server empfangen, wählt der Client eine zufällige Anzahl von Sekunden zwischen der oberen und der unteren Grenze aus und wartet diese Zeit ab, bevor der Jabber-Client versucht, sich beim sekundären Server anzumelden. Nach Ablauf des Timers versucht der Client, sich beim sekundären Knoten anzumelden.
IM- und Presence-Fallbacktypen
Wenn ein Benutzer-Failover vorliegt, muss ein Benutzer-Fallback vorhanden sein, wenn der Dienst auf dem problematischen Server wiederhergestellt wird. Es gibt zwei Arten von Server-Fallbacks:
Manueller Fallback
Ein manueller Fallback (Standardkonfiguration für den Server Recovery Manager) erfolgt, wenn der Service wiederhergestellt wurde und die Redundanzgruppe die Schaltfläche "Fallback" aktiviert. Wenn diese Schaltfläche ausgewählt ist, werden die Benutzersitzungen, die auf den sekundären Knoten verschoben wurden, zurück zu ihrem gehosteten Knoten verschoben. Der Jabber-Client wendet dann die Nachmeldeobergrenze und die Nachmeldeuntergrenze für den Fallback an.
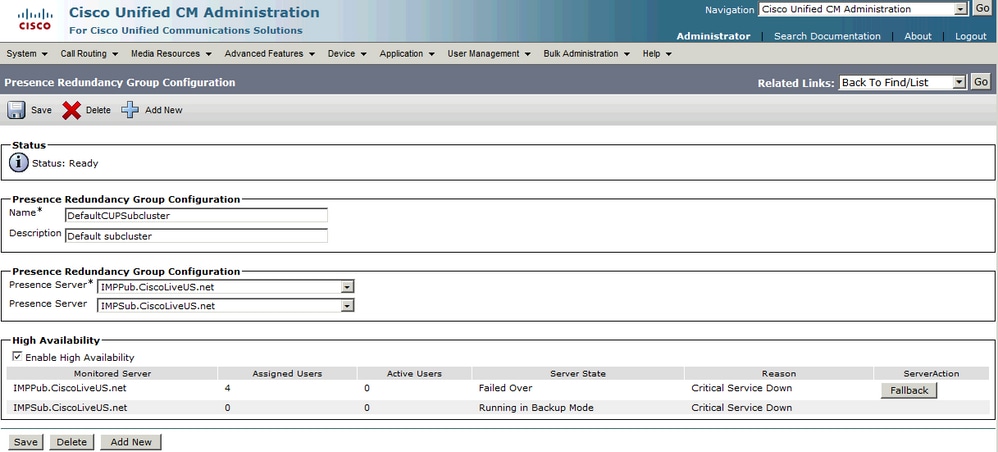
Automatischer Fallback
Der automatische Fallback findet statt, wenn der Server die Dienste überwacht und der Server Recovery Manager (SRM)-Dienst Benutzer automatisch auf ihre gehosteten Knoten zurückgreift. Der Schlüssel bei dieser Konfiguration besteht darin, dass der Server Recovery Manager (SRM)-Dienst 30 Minuten wartet, bis ein ausgefallener Dienst/Server aktiv bleibt, bevor ein automatischer Fallback initiiert wird. Sobald diese 30-minütige Betriebszeit hergestellt ist, werden die Benutzersitzungen wieder zu den gehosteten Knoten verschoben. Der Jabber-Client wendet dann die Nachmeldeobergrenze und die Nachmeldeuntergrenze für den Fallback an.

Hinweis: Der automatische Fallback ist nicht die Standardkonfiguration, kann aber aktiviert werden. Um den automatischen Fallback zu aktivieren, ändern Sie den Parameter "Enable Automatic Fallback" (Automatisches Fallback aktivieren) in den Dienstparametern des Serverwiederherstellungs-Managers in den Wert True.
Fehlerbehebung
In diesem Abschnitt erhalten Sie Informationen zur Behebung von Fehlern in Ihrer Konfiguration.
Bei der Fehlerbehebung für Hochverfügbarkeit auf dem IM&P-Dienstserver müssen zwei wichtige Timer berücksichtigt werden.
- Die Server tauschen alle 60 Sekunden 4 Keepalives aus. Wenn nach 60 Sekunden keine Antwort erfolgt, geht der Cisco Service Recovery Manager (SRM) davon aus, dass der nicht reagierende Knoten offline ging und einen Failover-Befehl auslöst. Wie der nächste Ausschnitt zeigt, trat der letzte Herzschlag vor 62 Sekunden auf.
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
Tipp: Wenn Sie in diesem Szenario eine gewisse Latenz in Ihrem Netzwerk festgestellt haben, wird empfohlen, den Heartbeat-Timeout-Timer von 60 auf 90 Sekunden zu erhöhen.
Navigieren Sie zur CUCM-Administration-Webseite > System > Service parameters configuration > Select the IM&P Server > Select Cisco Recovery Manager Settings. Erhöhen Sie nach Erreichen des "Keep Alive"-Timeouts die Anzahl auf 90 Sekunden.
- Der IM&P-Subscriber-Server wartet 90 Sekunden. Erkennt er, dass einer oder mehrere der überwachten Dienste ausfallen, übernimmt der Subscriber-Server.
Protokolle zur Fehlerbehebung sammeln
- Der Server Recover Manager (SRM) protokolliert vor und nach dem Failover-Ereignis (wenn möglich, auf Debugebene).
- Die Ausgabe des Befehls über die IM&P-Befehlszeilenschnittstelle führt sql select * aus EnterpriseSubcluster aus.
- Die Enterprise-Subclustertabelle in IM&P enthält die Konfiguration der Redundanzgruppe.
- Die Ausgabe des Befehls über die IM&P-Befehlszeilenschnittstelle führt sql select * aus enterprisenode aus.
- Die Enterprise-Knoten-Tabelle zeigt die Knoteninformationen und die Teilclusterzuordnung des Knotens an.
- Wenn das Failover durch einen Dienst erzeugt wird, der beendet wird, sammeln Sie:
- Ereignisanzeige - Systemprotokolle
- Anwendungsprotokolle der Ereignisanzeige
- Protokolle des Diensts, die beendet werden.
 Feedback
Feedback