Eine Einführung in IGRP
Inhalt
Einleitung
Dieses Dokument enthält eine Einführung in Interior Gateway Routing Protocol (IGRP). Es dient zwei Zwecken. Der eine besteht in der Einführung in die IGRP-Technologie für alle, die an ihrer Verwendung, Evaluierung und möglicherweise Implementierung interessiert sind. Der andere besteht darin, einige interessante Ideen und Konzepte, die in IGRP enthalten sind, bekannter zu machen. Informationen zur Konfiguration von IGRP finden Sie in den Abschnitten „Configuring IGRP“ (IGRP konfigurieren), „The Cisco IGRP Implementation“ (Die Implementierung von Cisco IGRP) und „IGRP Commands“ (IGRP-Befehle).
Ziele für IGRP
Das IGRP-Protokoll ermöglicht einer Reihe von Gateways die Koordination ihres Routings. Die Ziele des Programms lauten wie folgt:
-
Stabiles Routing auch in sehr großen oder komplexen Netzwerken. Es sollten keine Routing-Schleifen auftreten, auch nicht als Transienten.
-
Schnelle Reaktion auf Änderungen in der Netzwerktopologie.
-
Geringer Overhead: Das bedeutet, IGRP selbst sollte nicht mehr Bandbreite nutzen, als tatsächlich für seine Aufgabe benötigt wird.
-
Aufteilung des Datenverkehrs auf mehrere parallele Routen, wenn diese von ungefähr gleicher Erwünschtheit sind.
-
Berücksichtigung von Fehlerquoten und des Datenverkehrsvolumens auf unterschiedlichen Pfaden.
Die aktuelle IGRP-Implementierung übernimmt das Routing für TCP/IP. Das grundlegende Design soll jedoch in der Lage sein, eine Vielzahl von Protokollen zu verarbeiten.
Kein Tool wird alle Routing-Probleme lösen. Üblicherweise wird das Routing-Problem in mehrere Teile zerlegt. Protokolle wie IGRP werden als "interne Gateway-Protokolle" (IGPs) bezeichnet. Sie sind für die Verwendung in einem einzigen Satz von Netzwerken vorgesehen, entweder unter einer einzigen Verwaltung oder unter eng koordinierten Verwaltungen. Solche Netzwerke sind über "externe Gateway-Protokolle" (EGPs) verbunden. IGPs sind darauf ausgelegt, eine Vielzahl von Details zur Netzwerktopologie zu verfolgen. Bei der Entwicklung eines IGP liegt der Schwerpunkt auf der Erstellung optimaler Routen und der schnellen Reaktion auf Änderungen. Ein EGP soll ein System von Netzwerken vor Fehlern oder vorsätzlicher Falschdarstellung durch andere Systeme schützen. BGP ist ein solches Exterior Gateway Protocol. Priorität bei der Konzipierung eines EGP haben Stabilität und Verwaltungskontrollen. Oft reicht es aus, wenn eine EGP eine vernünftige Route erstellt, anstatt die optimale Route.
IGRP weist einige Ähnlichkeiten mit älteren Protokollen auf, z. B. Xerox's Routing Information Protocol, Berkeley's RIP und Dave Mills' Hello. Sie unterscheidet sich von diesen Protokollen in erster Linie dadurch, dass sie für größere und komplexere Netzwerke konzipiert sind. Im Abschnitt Vergleich mit RIP finden Sie einen detaillierteren Vergleich mit RIP, dem am häufigsten verwendeten der älteren Protokollgeneration.
Wie diese älteren Protokolle ist IGRP ein Distanzvektorprotokoll. Bei einem solchen Protokoll tauschen Gateways Routing-Informationen nur mit benachbarten Gateways aus. Diese Routing-Informationen enthalten eine Zusammenfassung der Informationen über den Rest des Netzwerks. Es lässt sich mathematisch zeigen, dass alle Gateways zusammengenommen ein Optimierungsproblem lösen, indem es auf einen verteilten Algorithmus hinausläuft. Jedes Gateway muss nur einen Teil des Problems lösen und nur einen Teil der Gesamtdaten empfangen.
Die wichtigste Alternative zum IGRP ist Enhanced IGRP (EIGRP) und eine Klasse von Algorithmen, die als SPF (Shortest-Path First) bezeichnet wird. OSPF verwendet dieses Konzept. Weitere Informationen zu OSPF finden Sie im OSPF-Designleitfaden. OSPF Diese basieren auf einer Überflutungstechnik, bei der jedes Gateway über den Status jeder Schnittstelle an jedem anderen Gateway auf dem neuesten Stand gehalten wird. Jedes Gateway löst das Optimierungsproblem selbstständig aus seiner Sicht unter Verwendung von Daten für das gesamte Netzwerk. Jeder Ansatz hat Vorteile. Unter bestimmten Umständen kann SPF schneller auf Änderungen reagieren. Um Routingschleifen zu vermeiden, muss IGRP neue Daten nach bestimmten Änderungen einige Minuten lang ignorieren. Da SPF über Informationen direkt von jedem Gateway verfügt, kann es diese Routing-Schleifen vermeiden. So kann es sofort auf neue Informationen reagieren. SPF muss jedoch wesentlich mehr Daten verarbeiten als IGRP, sowohl in internen Datenstrukturen als auch in Nachrichten zwischen Gateways.
Das Routing-Problem
IGRP ist für die Verwendung in Gateways vorgesehen, die mehrere Netzwerke verbinden. Wir gehen davon aus, dass die Netzwerke paketbasierte Technologie verwenden. Im Prinzip fungieren die Gateways als Paket-Switches. Wenn ein mit einem Netzwerk verbundenes System ein Paket an ein System in einem anderen Netzwerk senden möchte, adressiert es das Paket an einen Gateway. Wenn sich das Ziel in einem der mit dem Gateway verbundenen Netzwerke befindet, leitet das Gateway das Paket an das Ziel weiter. Wenn das Ziel weiter entfernt ist, leitet das Gateway das Paket an ein anderes Gateway weiter, das sich näher am Ziel befindet. Gateways verwenden Routing-Tabellen, um zu entscheiden, was mit Paketen geschehen soll. Es folgt eine einfache Beispiel-Routing-Tabelle. (Die in den Beispielen verwendeten Adressen sind IP-Adressen der Rutgers University. Beachten Sie, dass das grundlegende Routing-Problem auch für andere Protokolle ähnlich ist. In dieser Beschreibung wird jedoch davon ausgegangen, dass IGRP für das Routing von IP verwendet wird.)
Abbildung 1
network gateway interface ------- ------- --------- 128.6.4 none ethernet 0 128.6.5 none ethernet 1 128.6.21 128.6.4.1 ethernet 0 128.121 128.6.5.4 ethernet 1 10 128.6.5.4 ethernet 1
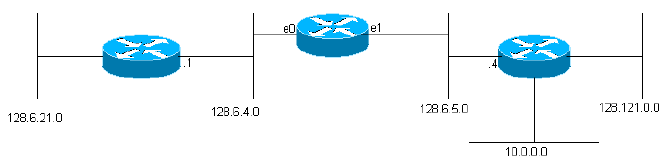
(Die tatsächlichen IGRP-Routing-Tabellen enthalten zusätzliche Informationen für die einzelnen Gateways.) Dieses Gateway ist mit zwei Ethernet-Netzen verbunden, die 0 und 1 heißen. Ihnen wurden IP-Netzwerknummern (eigentlich Subnetznummern) 128.6.4 und 128.6.5 gegeben. So können Pakete, die für diese spezifischen Netzwerke adressiert sind, direkt an das Ziel gesendet werden, einfach mithilfe der entsprechenden Ethernet-Schnittstelle. In der Nähe befinden sich zwei Gateways: 128.6.4.1 und 128.6.5.4. Pakete für andere Netzwerke als 128.6.4 und 128.6.5 werden an das eine oder das andere dieser Gateways weitergeleitet. Die Routing-Tabelle gibt an, welches Gateway für welches Netzwerk verwendet werden soll. Beispielsweise sollten Pakete, die an einen Host im Netzwerk 10 adressiert sind, an das Gateway 128.6.5.4 weitergeleitet werden. Es ist zu hoffen, dass dieses Gateway näher am Netzwerk 10 liegt, d.h. dass der beste Pfad zum Netzwerk 10 durch dieses Gateway verläuft. Der Hauptzweck von IGRP besteht darin, den Gateways die Erstellung und Verwaltung solcher Routing-Tabellen zu ermöglichen.
Zusammenfassung des IGRP
Wie oben erwähnt, ist IGRP ein Protokoll, das es Gateways ermöglicht, ihre Routing-Tabelle aufzubauen, indem sie Informationen mit anderen Gateways austauschen. Ein Gateway beginnt mit Einträgen für alle Netzwerke, die direkt mit ihm verbunden sind. Er erhält Informationen über andere Netzwerke, indem er Routing-Updates mit benachbarten Gateways austauscht. Im einfachsten Fall findet das Gateway einen Pfad, der die beste Verbindung zu jedem Netzwerk darstellt. Ein Pfad ist gekennzeichnet durch das nächste Gateway, an das Pakete gesendet werden sollen, die zu verwendende Netzwerkschnittstelle und Metrikinformationen. Metrische Informationen sind Zahlenwerte, die angeben, wie gut der Pfad ist. Auf diese Weise kann das Gateway Pfade vergleichen, die es von verschiedenen Gateways gehört hat, und sich für die Verwendung entscheiden. In vielen Fällen ist es sinnvoll, den Datenverkehr auf zwei oder mehr Pfade aufzuteilen. Dies wird vom IGRP immer dann durchgeführt, wenn zwei oder mehr Pfade gleich gut sind. Der Benutzer kann den Switch auch so konfigurieren, dass Datenverkehr aufgeteilt wird, wenn die Pfade nahezu gleich gut sind. In diesem Fall wird mehr Datenverkehr über den Pfad mit der besseren Metrik gesendet. Der Datenverkehr kann zwischen einer 9600-Bit/s-Leitung und einer 19200-Bit/s-Leitung aufgeteilt werden, und die 19200-Leitung erhält ungefähr doppelt so viel Datenverkehr wie die 9600-Bit/s-Leitung.
IGRP verwendet u. a. folgende Kennzahlen:
-
Topologische Verzögerungszeit
-
Bandbreite des Segments mit der engsten Bandbreite des Pfades
-
Kanalbelegung der Strecke
-
Zuverlässigkeit des Pfades
Die topologische Verzögerungszeit ist die Zeit, die benötigt wird, um das Ziel entlang dieses Pfads zu erreichen, vorausgesetzt, es wird ein Netzwerk entladen. Natürlich gibt es eine zusätzliche Verzögerung, wenn das Netzwerk geladen wird. Die Auslastung wird jedoch anhand der Kanalbelegung berücksichtigt, nicht durch den Versuch, tatsächliche Verzögerungen zu messen. Die Pfadbandbreite ist einfach die Bandbreite in Bit pro Sekunde der langsamsten Verbindung im Pfad. Die Kanalbelegung gibt an, welcher Anteil dieser Bandbreite derzeit genutzt wird. Es wird gemessen und ändert sich mit der Last. Zuverlässigkeit gibt die aktuelle Fehlerrate an. Dies ist der Anteil der Pakete, die unbeschädigt am Ziel ankommen. Es wird gemessen.
Obwohl sie nicht als Teil der Metrik verwendet werden, werden zwei zusätzliche Informationen mitgegeben: Hop Count und MTU Die Hop-Anzahl ist einfach die Anzahl der Gateways, die ein Paket durchlaufen muss, um das Ziel zu erreichen. MTU ist die maximale Paketgröße, die ohne Fragmentierung über den gesamten Pfad gesendet werden kann. (Dies ist das Minimum der MTUs aller am Pfad beteiligten Netzwerke.)
Basierend auf den Metrikinformationen wird eine einzelne "zusammengesetzte Metrik" für den Pfad berechnet. Die zusammengesetzte Metrik kombiniert den Effekt der verschiedenen metrischen Komponenten in einer einzigen Zahl, die die "Güte" dieses Pfades repräsentiert. Es ist die zusammengesetzte Metrik, die tatsächlich verwendet wird, um den besten Weg zu entscheiden.
Jedes Gateway sendet regelmäßig seine gesamte Routing-Tabelle (mit einer gewissen Zensur aufgrund der Split-Horizon-Regel) an alle benachbarten Gateways. Wenn ein Gateway diese Übertragung von einem anderen Gateway empfängt, vergleicht es die Tabelle mit der vorhandenen Tabelle. Alle neuen Ziele und Pfade werden der Routing-Tabelle des Gateways hinzugefügt. Die Pfade im Broadcast werden mit vorhandenen Pfaden verglichen. Wenn ein neuer Pfad besser ist, kann er den vorhandenen ersetzen. Die Informationen im Broadcast werden auch verwendet, um die Kanalbelegung und andere Informationen über vorhandene Pfade zu aktualisieren. Dieses allgemeine Verfahren ähnelt dem, das von allen Distanzvektorprotokollen verwendet wird. Er wird in der mathematischen Literatur als Bellman-Ford-Algorithmus bezeichnet. Eine detaillierte Entwicklung der grundlegenden Prozedur, die RIP, ein älteres Distanzvektorprotokoll, beschreibt, finden Sie unter RFC 1058![]() .
.
Im IGRP wird der allgemeine Bellman-Ford-Algorithmus in drei kritischen Punkten geändert. Zunächst wird anstelle einer einfachen Metrik ein Vektor von Metriken verwendet, um Pfade zu charakterisieren. Zweitens wird der Datenverkehr nicht auf einen einzelnen Pfad mit der kleinsten Kennzahl festgelegt, sondern auf mehrere Pfade aufgeteilt, deren Kennzahlen in einen angegebenen Bereich fallen. Drittens werden verschiedene Funktionen eingeführt, um in Situationen, in denen sich die Topologie ändert, für Stabilität zu sorgen.
Der beste Pfad wird auf der Grundlage einer zusammengesetzten Metrik ausgewählt:
[(K1 / Be) + (K2 * Dc)] r
wobei K1, K2 = Konstanten, Be = entladene Pfadbandbreite x (1 - Kanalbelegung), Dc = topologische Verzögerung und r = Zuverlässigkeit.
Der Pfad mit der kleinsten zusammengesetzten Metrik ist der beste Pfad. Wenn mehrere Pfade zum gleichen Ziel vorhanden sind, kann das Gateway die Pakete über mehrere Pfade routen. Dies erfolgt gemäß der zusammengesetzten Metrik für jeden Datenpfad. Wenn beispielsweise ein Pfad eine Composite-Metrik von 1 und ein anderer Pfad eine Composite-Metrik von 3 hat, werden dreimal so viele Pakete über den Datenpfad mit der Composite-Metrik von 1 gesendet.
Die Verwendung eines Vektors mit metrischen Informationen hat zwei Vorteile. Zum einen bietet es die Möglichkeit, mehrere Servicetypen aus demselben Datensatz zu unterstützen. Der zweite Vorteil ist eine verbesserte Genauigkeit. Wenn eine einzelne Metrik verwendet wird, wird sie normalerweise wie eine Verzögerung behandelt. Jeder Link im Pfad wird zur Gesamtmetrik hinzugefügt. Wenn eine Verbindung mit niedriger Bandbreite vorhanden ist, wird sie normalerweise durch eine große Verzögerung dargestellt. Bandbreitenbeschränkungen wirken sich jedoch nicht auf die Art und Weise aus, wie Verzögerungen auftreten. Wenn die Bandbreite als separate Komponente behandelt wird, kann sie korrekt verarbeitet werden. Ebenso kann die Last über eine separate Kanalbelegungsnummer abgewickelt werden.
IGRP stellt ein System zur Verbindung von Computernetzwerken bereit, das eine allgemeine Diagrammtopologie einschließlich Schleifen stabil handhaben kann. Das System verwaltet vollständige Pfadmetrieinformationen, d. h. es kennt die Pfadparameter zu allen anderen Netzwerken, mit denen ein Gateway verbunden ist. Der Datenverkehr kann über parallele Pfade verteilt werden, und mehrere Pfadparameter können gleichzeitig über das gesamte Netzwerk berechnet werden.
Vergleich mit RIP
In diesem Abschnitt wird IGRP mit RIP verglichen. Dieser Vergleich ist nützlich, da RIP für ähnliche Zwecke wie IGRP häufig verwendet wird. Dies ist jedoch nicht ganz fair. RIP sollte nicht alle denselben Ziele wie IGRP erfüllen. RIP wurde für den Einsatz in kleinen Netzwerken mit relativ einheitlicher Technologie konzipiert. In solchen Anwendungen ist sie in der Regel ausreichend.
Der grundlegendste Unterschied zwischen IGRP und RIP ist die Struktur ihrer Metriken. Leider ist dies keine Änderung, die einfach auf RIP nachgerüstet werden kann. Es erfordert die neuen Algorithmen und Datenstrukturen, die im IGRP vorhanden sind.
RIP verwendet eine einfache "Hop Count"-Metrik zur Beschreibung des Netzwerks. Anders als IGRP, bei dem jeder Pfad durch eine Verzögerung, Bandbreite usw. beschrieben wird, wird er in RIP durch eine Zahl zwischen 1 und 15 beschrieben. Normalerweise wird diese Zahl verwendet, um die Anzahl der Gateways darzustellen, die der Pfad durchläuft, bevor er zum Ziel gelangt. Dies bedeutet, dass zwischen einer langsamen seriellen Leitung und einem Ethernet nicht unterschieden wird. Bei einigen RIP-Implementierungen kann der Systemadministrator festlegen, dass ein bestimmter Hop mehr als einmal gezählt werden soll. Langsame Netzwerke lassen sich durch eine große Anzahl von Hops darstellen. Aber da das Maximum 15 ist, kann das nicht sehr viel. Wenn z. B. ein Ethernet durch 1 und eine 56Kb-Leitung durch 3 dargestellt wird, können maximal 5 56Kb-Leitungen in einem Pfad vorhanden sein, oder das Maximum von 15 wird überschritten. Studien von Cisco legen nahe, dass eine 24-Bit-Metrik erforderlich ist, um die gesamte Bandbreite der verfügbaren Netzwerkgeschwindigkeiten abbilden und ein großes Netzwerk ermöglichen zu können. Wenn die maximale Größe zu niedrig ist, hat der Systemadministrator eine unangenehme Wahl: entweder kann er nicht zwischen schnellen und langsamen Strecken unterscheiden, oder er kann sein gesamtes Netzwerk nicht an die Grenze bringen. Tatsächlich sind einige nationale Netze inzwischen so groß, dass RIP sie nicht bewältigen kann, selbst wenn jeder Hop nur einmal gezählt wird. RIP kann für solche Netzwerke einfach nicht verwendet werden.
Die naheliegende Antwort wäre, RIP zu modifizieren, um eine größere Metrik zuzulassen. Leider wird das nicht funktionieren. Wie alle Distanzvektorprotokolle hat RIP das Problem, "bis ins Unendliche zu zählen". Dies wird in RFC 1058 genauer beschrieben![]() . Wenn sich die Topologie ändert, werden falsche Routen eingeführt. Die Kennzahlen für diese unberechtigten Routen nehmen langsam zu, bis sie 15 erreichen. An diesem Punkt werden die Routen entfernt. 15 ist ein ausreichend kleines Maximum, dass dieser Prozess ziemlich schnell konvergiert, vorausgesetzt, dass ausgelöste Updates verwendet werden. Wenn RIP so modifiziert würde, dass eine 24-Bit-Metrik zulässig ist, würden Schleifen lange genug bestehen, um die Metrik bis zu 2**24 zu zählen. Dies ist nicht tolerierbar. IGRP verfügt über Funktionen, die die Einführung von unechten Routen verhindern. Diese werden nachfolgend in Abschnitt 5.2 erläutert. Es ist nicht zweckmäßig, komplexe Netzwerke zu handhaben, ohne solche Funktionen einzuführen oder ein Protokoll wie SPF zu ändern.
. Wenn sich die Topologie ändert, werden falsche Routen eingeführt. Die Kennzahlen für diese unberechtigten Routen nehmen langsam zu, bis sie 15 erreichen. An diesem Punkt werden die Routen entfernt. 15 ist ein ausreichend kleines Maximum, dass dieser Prozess ziemlich schnell konvergiert, vorausgesetzt, dass ausgelöste Updates verwendet werden. Wenn RIP so modifiziert würde, dass eine 24-Bit-Metrik zulässig ist, würden Schleifen lange genug bestehen, um die Metrik bis zu 2**24 zu zählen. Dies ist nicht tolerierbar. IGRP verfügt über Funktionen, die die Einführung von unechten Routen verhindern. Diese werden nachfolgend in Abschnitt 5.2 erläutert. Es ist nicht zweckmäßig, komplexe Netzwerke zu handhaben, ohne solche Funktionen einzuführen oder ein Protokoll wie SPF zu ändern.
IGRP trägt nicht nur dazu bei, die zulässigen Kennzahlen zu erhöhen. Sie strukturiert die Metrik neu, um Verzögerung, Bandbreite, Zuverlässigkeit und Last zu beschreiben. Solche Überlegungen können in einer einzigen Metrik dargestellt werden, z. B. in RIPs. Der IGRP-Ansatz ist jedoch potenziell genauer. Bei einer einzigen Metrik beispielsweise scheinen mehrere aufeinander folgende schnelle Verbindungen einer einzigen langsamen zu entsprechen. Dies kann bei interaktivem Datenverkehr der Fall sein, bei dem Verzögerungen das Hauptproblem darstellen. Bei der Übertragung großer Datenmengen ist die Bandbreite jedoch das wichtigste Anliegen, und das Hinzufügen von Metriken zusammen ist nicht der richtige Ansatz. IGRP behandelt Verzögerungen und Bandbreite separat und kumuliert Verzögerungen, wobei jedoch das Minimum der Bandbreiten verwendet wird. Es ist nicht leicht zu erkennen, wie die Auswirkungen von Zuverlässigkeit und Last in eine Einkomponenten-Metrik integriert werden können.
Meiner Meinung nach ist einer der großen Vorteile von IGRP die einfache Konfiguration. Es kann direkt Größen darstellen, die eine physische Bedeutung haben. Das bedeutet, dass die Einrichtung automatisch nach Schnittstellentyp, Leitungsgeschwindigkeit usw. erfolgen kann. Mit einer Einkomponenten-Metrik ist es wahrscheinlicher, dass die Metrik "gekocht" werden muss, um die Auswirkungen verschiedener Dinge zu berücksichtigen.
Andere Innovationen sind eher eine Frage von Algorithmen und Datenstrukturen als des Routing-Protokolls. IGRP spezifiziert beispielsweise Algorithmen und Datenstrukturen, die die Aufteilung des Datenverkehrs auf mehrere Routen unterstützen. Es ist sicherlich möglich, eine Implementierung von RIP zu entwerfen, die dies tut. Nach der erneuten Implementierung des Routings besteht jedoch kein Grund, an RIP festzuhalten.
Bisher habe ich "generisches IGRP" beschrieben, eine Technologie, die Routing für beliebige Netzwerkprotokolle unterstützen könnte. In diesem Abschnitt sollte jedoch etwas mehr über die spezifische TCP/IP-Implementierung erwähnt werden. Dies ist die Implementierung, die mit RIP verglichen werden wird.
RIP-Aktualisierungsnachrichten enthalten lediglich Snapshots der Routing-Tabelle. Das heißt, sie haben eine Reihe von Zielen und metrischen Werten, und sonst wenig. Die IP-Implementierung des IGRP weist eine zusätzliche Struktur auf. Zunächst wird die Aktualisierungsnachricht durch eine "autonome Systemnummer" identifiziert. Diese Terminologie entstammt der Arpanet-Tradition und hat dort eine spezifische Bedeutung. Für die meisten Netzwerke bedeutet dies jedoch, dass Sie mehrere verschiedene Routing-Systeme im gleichen Netzwerk ausführen können. Dies ist nützlich für Orte, an denen Netzwerke aus verschiedenen Organisationen zusammenlaufen. Jede Organisation kann ihr eigenes Routing verwalten. Da jedes Update mit einem Label versehen ist, können Gateways so konfiguriert werden, dass nur das richtige berücksichtigt wird. Bestimmte Gateways werden so konfiguriert, dass sie Updates von verschiedenen autonomen Systemen empfangen. Sie geben Informationen zwischen den Systemen kontrolliert weiter. Beachten Sie, dass dies keine vollständige Lösung für Probleme mit der Routing-Sicherheit ist. Jedes Gateway kann so konfiguriert werden, dass es Updates von jedem autonomen System abhört. Es ist jedoch nach wie vor ein sehr nützliches Tool für die Implementierung von Routing-Richtlinien, wenn ein angemessenes Maß an Vertrauen zwischen den Netzwerkadministratoren besteht.
Die zweite Strukturfunktion zu IGRP-Aktualisierungsnachrichten wirkt sich auf die Behandlung von Standard-Routen durch IGRP aus. Die meisten Routing-Protokolle haben ein Konzept der Standardroute. Oft ist es nicht sinnvoll, bei Routing-Updates jedes Netzwerk weltweit aufzulisten. In der Regel benötigen eine Reihe von Gateways detaillierte Routing-Informationen für Netzwerke innerhalb ihrer Organisation. Der gesamte Datenverkehr für Ziele außerhalb des Unternehmens kann an einen der wenigen Grenz-Gateways gesendet werden. Diese Grenzgateways können vollständigere Informationen enthalten. Die Route zum Gateway mit den besten Grenzen ist eine "Standardroute". Hierbei handelt es sich um einen Standard, der verwendet wird, um zu einem Ziel zu gelangen, das nicht explizit in den internen Routing-Updates aufgeführt ist. RIP und einige andere Routing-Protokolle verbreiten Informationen über die Standardroute, als wäre sie ein echtes Netzwerk. IGRP verfolgt einen anderen Ansatz. Anstelle eines einzelnen gefälschten Eintrags für die Standardroute ermöglicht IGRP die Markierung echter Netzwerke als Standard. Dies wird dadurch erreicht, dass Informationen über diese Netzwerke in einem speziellen Abschnitt außerhalb der Update-Nachricht platziert werden. Es ist jedoch auch denkbar, dass ein mit diesen Netzwerken verbundenes Bit aktiviert wird. IGRP scannt regelmäßig alle möglichen Standardrouten und wählt das Routing mit der niedrigsten Kennzahl als tatsächliche Standardroute aus.
Möglicherweise ist dieser Standardansatz etwas flexibler als der der meisten RIP-Implementierungen. In der Regel können RIP-Gateways so konfiguriert werden, dass sie eine Standardroute mit einer bestimmten Metrik generieren. Dies soll an Grenzübergängen erfolgen.
Detaillierte Beschreibung
Dieser Abschnitt enthält eine detaillierte Beschreibung des IGRP.
Allgemeine Beschreibung
Beim ersten Einschalten eines Gateways wird dessen Routing-Tabelle initialisiert. Dies kann durch einen Bediener von einem Konsolenterminal aus oder durch das Lesen von Informationen aus Konfigurationsdateien erfolgen. Es wird eine Beschreibung jedes mit dem Gateway verbundenen Netzwerks bereitgestellt, einschließlich der topologischen Verzögerung entlang der Verbindung (z. B. wie lange es dauert, die Verbindung mit einem einzelnen Bit zu durchqueren) und der Bandbreite der Verbindung.
Abbildung 2
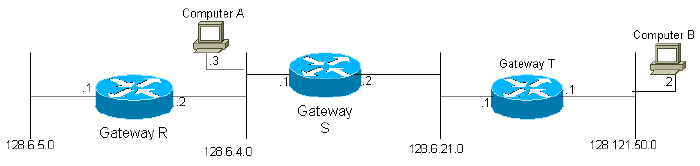
Beispielsweise würde in dem obigen Diagramm dem Gateway S mitgeteilt, dass es über die entsprechenden Schnittstellen mit den Netzen 2 und 3 verbunden ist. Das Gateway 2 weiß also zunächst nur, dass es einen beliebigen Zielrechner in den Netzwerken 2 und 3 erreichen kann. Alle Gateways sind so programmiert, dass sie periodisch die Informationen, mit denen sie initialisiert wurden, sowie Informationen, die von anderen Gateways gesammelt wurden, an ihre benachbarten Gateways übertragen. Das Gateway S würde also Updates von den Gateways R und T erhalten und erfahren, dass es Computer im Netzwerk 1 über das Gateway R und Computer im Netzwerk 4 über das Gateway T erreichen kann. Da das Gateway S seine gesamte Routing-Tabelle sendet, wird das Gateway T im nächsten Zyklus lernen, dass es über das Gateway S zu Netzwerk 1 gelangen kann. Es ist leicht zu erkennen, dass Informationen über jedes Netzwerk im System irgendwann jedes Gateway im System erreichen, vorausgesetzt, dass das Netzwerk vollständig verbunden ist.
Abbildung 3
________ Network 1
|
gw A --nw2-- gw C
| / |
| / |
nw3 nw4 nw5
| / |
| / |
gw B gw D
_|_____________|____ Network 6
Jedes Gateway berechnet eine zusammengesetzte Metrik, um die Zweckmäßigkeit der Datenpfade zu den Zielcomputern zu bestimmen. Im obigen Diagramm würde beispielsweise Gateway A (gw A) für ein Ziel in Netzwerk 6 metrische Funktionen für zwei Pfade über Gateways B und C berechnen. Beachten Sie, dass Pfade einfach durch den nächsten Hop definiert werden. Es gibt drei mögliche Routen von A zu Netzwerk 6:
-
Direkt zu B
-
Nach C und dann nach B
-
Nach C und dann nach D
Gateway A muss jedoch nicht zwischen den beiden Routen mit C wählen. Die Routing-Tabelle in A enthält einen einzigen Eintrag, der den Pfad zu C darstellt. Seine Metrik stellt die beste Möglichkeit dar, von C zum endgültigen Ziel zu gelangen. Wenn A ein Paket an C sendet, muss C entscheiden, ob B oder D verwendet werden soll.
Gleichung 1
Die für jeden Datenpfad berechnete zusammengesetzte metrische Funktion ist wie folgt:
[(K1 / Be) + (K2 * Dc)] r
Dabei gilt r = normierte Zuverlässigkeit (% der Übertragungen, die am nächsten Hop erfolgreich empfangen werden), Dc = kombinierte Verzögerung, Be = effektive Bandbreite: entladene Bandbreite x (1 - Kanalbelegung) und K1 und K2 = Konstanten.
Gleichung 2
Im Prinzip könnte die zusammengesetzte Verzögerung Dc wie folgt bestimmt werden:
Dc = Ds + Dcir + Dt
Ds = Schaltverzögerung, Dcir = Schaltungsverzögerung (Übertragungsverzögerung von 1 Bit) und DT = Übertragungsverzögerung (Leerlaufverzögerung bei einer 1500-Bit-Nachricht).
In der Praxis wird jedoch für jeden Netzwerktechnologietyp eine Standardverzögerungszahl verwendet. So gibt es beispielsweise eine Standardverzögerungszahl für Ethernet und für serielle Leitungen mit einer beliebigen Bitrate.
Im Folgenden finden Sie ein Beispiel dafür, wie die Routing-Tabelle von Gateway A im obigen Diagramm zu Netzwerk 6 aussehen könnte. (Die einzelnen Komponenten des metrischen Vektors sind der Einfachheit halber nicht dargestellt.)
Routing-Tabelle Beispiel:
| Netzwerk | Schnittstelle | Nächstes Gateway | Kennzahl |
|---|---|---|---|
| 1 | NW 1 | None | Direkt verbunden |
| 2 | NW 2 | None | Direkt verbunden |
| 3 | NW 3 | None | Direkt verbunden |
| 4 | NW 2 | C | 1270 |
| NW 3 | B | 1180 | |
| 5 | NW 2 | C | 1270 |
| NW 3 | B | 2130 | |
| 6 | NW 2 | C | 2040 |
| NW 3 | B | 1180 |
Der grundlegende Prozess des Aufbaus einer Routing-Tabelle durch den Austausch von Informationen mit Nachbarn wird durch den Bellman-Ford-Algorithmus beschrieben. Der Algorithmus wurde bereits in früheren Protokollen wie RIP (RFC 1058) verwendet. Um mit komplexeren Netzwerken umgehen zu können, fügt IGRP dem Bellman-Ford-Algorithmus drei Funktionen hinzu:
-
Anstelle einer einfachen Metrik wird ein Vektor von Metriken verwendet, um Pfade zu charakterisieren. Aus diesem Vektor kann gemäß Gleichung 1 oben eine einzige zusammengesetzte Metrik berechnet werden. Die Verwendung eines Vektors ermöglicht es dem Gateway, verschiedene Arten von Diensten aufzunehmen, indem mehrere verschiedene Koeffizienten in Gleichung 1 verwendet werden. Außerdem ermöglicht sie eine genauere Darstellung der Merkmale des Netzwerks als eine einzelne Metrik.
-
Anstatt einen Pfad mit der kleinsten Kennzahl zu wählen, wird der Datenverkehr auf mehrere Pfade aufgeteilt, wobei die Kennzahlen in einen angegebenen Bereich fallen. Auf diese Weise können mehrere Routen parallel verwendet werden, wodurch eine größere effektive Bandbreite als bei jeder einzelnen Route zur Verfügung steht. Eine Variante V wird vom Netzwerkadministrator festgelegt. Alle Pfade mit minimaler zusammengesetzter Metrik M werden beibehalten. Darüber hinaus werden alle Pfade, deren Metrik kleiner als V x M ist, beibehalten. Der Datenverkehr wird umgekehrt proportional zu den zusammengesetzten Metriken auf mehrere Pfade verteilt.
-
Es gibt einige Probleme mit diesem Konzept der Varianz. Es ist schwierig, Strategien zu entwickeln, die Varianzwerte größer als 1 verwenden und nicht auch zu Paketschleifen führen. In Cisco Version 8.2 ist die Varianzfunktion nicht implementiert. (Ich bin mir nicht sicher, in welcher Version die Funktion entfernt wurde.) Dies bewirkt, dass die Varianz permanent auf 1 gesetzt wird.
-
Verschiedene Funktionen werden eingeführt, um Stabilität in Situationen zu gewährleisten, in denen sich die Topologie ändert. Diese Funktionen sollen Routing-Schleifen und "Zählen bis unendlich" verhindern, die frühere Versuche charakterisiert haben, Ford-Algorithmen für diese Art von Anwendungen zu verwenden. Die wichtigsten Stabilitätsmerkmale sind "Holddowns", "ausgelöste Updates", "Split Horizon" und "Poisoning". Diese werden im Folgenden ausführlicher besprochen.
Verkehrsaufteilung (Punkt 2) bringt eine eher subtile Gefahr mit sich. Die Variante V ist so ausgelegt, dass Gateways parallele Pfade mit unterschiedlichen Geschwindigkeiten nutzen können. Aus Redundanzgründen könnte beispielsweise eine 9600-Bit/s-Leitung parallel zu einer 19200-Bit/s-Leitung betrieben werden. Wenn die Varianz V 1 ist, wird nur der beste Pfad verwendet. Daher wird die 9600-Bit/s-Leitung nicht verwendet, wenn die 19200-Bit/s-Leitung eine angemessene Zuverlässigkeit bietet. (Wenn jedoch mehrere Pfade identisch sind, wird die Last auf diese verteilt.) Wenn wir die Varianz erhöhen, können wir den Datenverkehr zwischen der besten Route und anderen Routen aufteilen, die fast genauso gut sind. Bei ausreichend großen Abweichungen wird der Datenverkehr auf die beiden Leitungen aufgeteilt. Die Gefahr besteht darin, dass bei einer ausreichend großen Varianz Wege zugelassen werden, die nicht nur langsamer sind, sondern sich tatsächlich "in die falsche Richtung" bewegen. Daher sollte es eine zusätzliche Regel geben, um zu verhindern, dass Datenverkehr "Upstream" gesendet wird: Es wird kein Datenverkehr über Pfade gesendet, deren zusammengesetzte Remote-Metrik (die zusammengesetzte Metrik, die am nächsten Hop berechnet wird) größer ist als die zusammengesetzte Metrik, die am Gateway berechnet wird. Im Allgemeinen wird Systemadministratoren empfohlen, die Varianz nicht über 1 zu setzen, außer in bestimmten Situationen, in denen parallele Pfade verwendet werden müssen. In diesem Fall wird die Varianz sorgfältig eingestellt, um die "richtigen" Ergebnisse zu liefern.
IGRP soll mehrere "Diensttypen" und Protokolle verarbeiten. Type of Service ist eine Spezifikation in einem Datenpaket, die die Art und Weise der Auswertung von Pfaden ändert. Das TCP/IP-Protokoll ermöglicht es dem Paket beispielsweise, die relative Bedeutung einer hohen Bandbreite, einer geringen Verzögerung oder einer hohen Zuverlässigkeit anzugeben. Im Allgemeinen geben interaktive Anwendungen eine geringe Verzögerung an, während Massenübertragungsanwendungen eine hohe Bandbreite angeben. Diese Anforderungen bestimmen die relativen Werte von K1 und K2, die für die Verwendung in Eq. 1. Jede Kombination von Spezifikationen in dem zu unterstützenden Paket wird als "Type of Service" (Servicetyp) bezeichnet. Für jeden Diensttyp muss ein Satz von Parametern K1 und K2 gewählt werden. Für jeden Servicetyp wird eine Routing-Tabelle gespeichert. Dies geschieht, weil Pfade gemäß der zusammengesetzten Metrik ausgewählt und sortiert werden, die durch Eq definiert ist. 1. Dies ist je nach Servicetyp unterschiedlich. Die Informationen aus all diesen Routing-Tabellen werden kombiniert, um die Routing-Aktualisierungsnachrichten zu erzeugen, die von den Gateways ausgetauscht werden, wie in Abbildung 7 beschrieben.
Stabilitätsmerkmale
Dieser Abschnitt beschreibt Holddowns, ausgelöste Updates, Split Horizon und Vergiftungen. Diese Funktionen sollen verhindern, dass Gateways fehlerhafte Routen übernehmen. Wie in RFC 1058![]() beschrieben, kann dies passieren, wenn eine Route aufgrund eines Ausfalls eines Gateways oder eines Netzwerks unbrauchbar wird. Die benachbarten Gateways erkennen grundsätzlich Ausfälle. Anschließend werden Routing-Updates gesendet, die die alte Route als unbrauchbar anzeigen. Es ist jedoch möglich, dass Updates bestimmte Teile des Netzwerks gar nicht erreichen oder das Erreichen bestimmter Gateways verzögert wird. Ein Gateway, das die alte Route immer noch für gut hält, kann diese Informationen weiter verbreiten und die ausgefallene Route so erneut in das System eingeben. Diese Informationen verbreiten sich schließlich über das Netzwerk und kehren zum Gateway zurück, von dem sie erneut eingespeist wurden. Das Ergebnis ist eine Kreisroute.
beschrieben, kann dies passieren, wenn eine Route aufgrund eines Ausfalls eines Gateways oder eines Netzwerks unbrauchbar wird. Die benachbarten Gateways erkennen grundsätzlich Ausfälle. Anschließend werden Routing-Updates gesendet, die die alte Route als unbrauchbar anzeigen. Es ist jedoch möglich, dass Updates bestimmte Teile des Netzwerks gar nicht erreichen oder das Erreichen bestimmter Gateways verzögert wird. Ein Gateway, das die alte Route immer noch für gut hält, kann diese Informationen weiter verbreiten und die ausgefallene Route so erneut in das System eingeben. Diese Informationen verbreiten sich schließlich über das Netzwerk und kehren zum Gateway zurück, von dem sie erneut eingespeist wurden. Das Ergebnis ist eine Kreisroute.
Tatsächlich gibt es bei den Gegenmaßnahmen eine gewisse Redundanz. Grundsätzlich sollten Holddowns und ausgelöste Updates ausreichen, um Fehlrouten von vornherein zu vermeiden. In der Praxis können jedoch Kommunikationsfehler verschiedener Art dazu führen, dass sie unzureichend sind. Split Horizon und Route Poisoning sollen Routing Loops in jedem Fall verhindern.
In der Regel werden neue Routing-Tabellen regelmäßig (standardmäßig alle 90 Sekunden) an benachbarte Gateways gesendet. Dies kann jedoch vom Systemadministrator angepasst werden. Ein ausgelöstes Update ist eine neue Routing-Tabelle, die als Reaktion auf eine Änderung sofort gesendet wird. Die wichtigste Änderung ist die Entfernung einer Route. Dies kann daran liegen, dass ein Timeout abgelaufen ist (wahrscheinlich ist ein benachbartes Gateway oder eine benachbarte Leitung ausgefallen) oder dass eine Aktualisierungsnachricht vom nächsten Gateway im Pfad anzeigt, dass der Pfad nicht mehr verwendbar ist. Wenn ein Gateway G erkennt, dass eine Route nicht mehr nutzbar ist, löst es sofort ein Update aus. Diese Aktualisierung zeigt an, dass diese Route nicht verwendbar ist. Überlegen Sie, was passiert, wenn dieses Update die benachbarten Gateways erreicht. Wenn die Route des Nachbarn zurück auf G zeigt, muss der Nachbar die Route entfernen. Dadurch löst der Nachbar ein Update aus usw. Ein Fehler löst daher eine Welle von Aktualisierungsnachrichten aus. Diese Welle breitet sich im gesamten Netzwerkbereich aus, in dem die Routen das ausgefallene Gateway oder Netzwerk durchlaufen haben.
Ausgelöste Updates würden ausreichen, wenn wir garantieren könnten, dass die Welle der Updates sofort alle geeigneten Gateways erreicht. Es gibt jedoch zwei Probleme. Zum einen können Pakete, die die Aktualisierungsnachricht enthalten, durch eine Verbindung im Netzwerk verworfen oder beschädigt werden. Zweitens passieren die ausgelösten Updates nicht sofort. Es ist möglich, dass ein Gateway, das das ausgelöste Update noch nicht erhalten hat, ein regelmäßiges Update zur falschen Zeit ausgibt, wodurch die fehlerhafte Route in einen Nachbarn wieder eingefügt wird, der das ausgelöste Update bereits erhalten hat. Holddowns sollen diese Probleme umgehen. Die Holddown-Regel besagt, dass nach dem Entfernen einer Route für einen bestimmten Zeitraum keine neue Route für dasselbe Ziel akzeptiert wird. Dies gibt den ausgelösten Updates Zeit, um zu allen anderen Gateways zu gelangen, sodass wir sicher sein können, dass alle neuen Routen, die wir erhalten, nicht nur irgendein Gateway sind, das das alte wieder einfügt. Der Haltezeitraum muss lang genug sein, damit die Welle der ausgelösten Updates durch das Netzwerk gehen kann. Darüber hinaus sollte es einige reguläre Broadcast-Zyklen umfassen, um verlorene Pakete zu verarbeiten. Überlegen Sie, was passiert, wenn eine der ausgelösten Updates gelöscht oder beschädigt wird. Das Gateway, von dem das Update bereitgestellt wurde, führt beim nächsten regulären Update ein weiteres Update durch. Dadurch wird die Welle der ausgelösten Updates bei Nachbarn, die die ursprüngliche Welle verpasst haben, neu gestartet.
Die Kombination aus ausgelösten Updates und Holddowns sollte ausreichen, um abgelaufene Routen zu entfernen und zu verhindern, dass sie wieder eingesetzt werden. Dennoch lohnt es sich, einige zusätzliche Vorsichtsmaßnahmen zu treffen. Sie ermöglichen sehr verlustbehaftete und partitionierte Netzwerke. Die zusätzlichen Vorsichtsmaßnahmen, die IGRP fordert, sind Split Horizon und Route Poisoning. Split Horizon entsteht aus der Beobachtung, dass es nie sinnvoll ist, eine Route zurück in die Richtung zu senden, aus der sie kam. Betrachten Sie folgende Situation:
network 1 network 2
-------------X-----------------X
gateway A gateway B
Gateway A teilt B mit, dass es eine Route zu Netzwerk 1 hat. Wenn B Updates an A sendet, gibt es keinen Grund, Netzwerk 1 zu erwähnen. Da A näher an 1 ist, gibt es keinen Grund, über B zu gehen. Die Split-Horizon-Regel besagt, dass für jeden Nachbarn (eigentlich jedes benachbarte Netzwerk) eine separate Update-Nachricht generiert werden sollte. Bei der Aktualisierung für einen bestimmten Nachbarn sollten Routen, die auf diesen Nachbarn verweisen, weggelassen werden. Diese Regel verhindert Schleifen zwischen benachbarten Gateways. Beispiel: Die A-Schnittstelle zu Netzwerk 1 ist fehlerhaft. Ohne die Split-Horizon-Regel würde B A mitteilen, dass es zu 1 kommen kann. Da es keine echte Route mehr hat, könnte A diese Route übernehmen. In diesem Fall hätten A und B beide Routen zu 1. Aber A würde auf B und B auf A zeigen. Natürlich sollten ausgelöste Updates und Holddowns dies verhindern. Aber da es keinen Grund gibt, Informationen dorthin zurückzuschicken, wo sie herkommen, lohnt sich Split Horizon trotzdem. Zusätzlich zu seiner Rolle bei der Vermeidung von Schleifen hält Split Horizon die Größe von Update-Nachrichten niedrig.
Der Split Horizon sollte Schleifen zwischen benachbarten Gateways verhindern. Routenvergiftung soll größere Schleifen durchbrechen. Die Regel lautet, dass es eine Schleife gibt, wenn ein Update anzeigt, dass die Metrik für eine vorhandene Route ausreichend erhöht wurde. Die Route sollte entfernt und zurückgehalten werden. Derzeit gilt die Regel, dass eine Route entfernt wird, wenn die zusammengesetzte Metrik um mehr als den Faktor 1,1 zunimmt. Es ist nicht sicher, dass nur jede Erhöhung der zusammengesetzten Metrik das Entfernen der Route auslöst, da aufgrund von Änderungen der Kanalbelegung oder der Zuverlässigkeit kleine metrische Änderungen auftreten können. Der Faktor 1.1 ist also nur eine Heuristik. Der genaue Wert ist nicht entscheidend. Wir erwarten, dass diese Regel nur benötigt wird, um sehr große Schleifen zu durchbrechen, da kleine durch ausgelöste Updates und Holddowns verhindert werden.
Zurückstellungen deaktivieren
Ab Version 8.2 bietet der Cisco-Code eine Option zum Deaktivieren von Holddowns. Der Nachteil von Holddowns besteht darin, dass sie die Einführung einer neuen Route verzögern, wenn eine alte Route ausfällt. Bei Verwendung von Standardparametern kann es nach einer Änderung einige Minuten dauern, bis ein Router eine neue Route übernimmt. Aus den oben erläuterten Gründen ist es jedoch nicht sicher, einfach Holddowns zu entfernen. Das Ergebnis würde bis unendlich gezählt, wie in RFC 1058 beschrieben. Wir vermuten, können aber nicht beweisen, dass mit einer stärkeren Version der Streckenvergiftung Verweigerungen nicht mehr nötig sind, um das Zählen bis ins Unendliche zu stoppen. Die Deaktivierung von Holddowns ermöglicht diese stärkere Form der Routenvergiftung. Beachten Sie, dass Split Horizon und ausgelöste Updates weiterhin gültig sind.
Die stärkere Form der Routenvergiftung basiert auf einer Hop-Count. Wenn die Anzahl der Hops für einen Pfad zunimmt, wird die Route entfernt. Dadurch werden natürlich noch gültige Routen entfernt. Wenn sich etwas Anderes im Netzwerk ändert, sodass der Pfad nun über ein weiteres Gateway verläuft, erhöht sich die Anzahl der Hops. In diesem Fall ist die Route immer noch gültig. Es gibt jedoch keine absolut sichere Möglichkeit, diesen Fall von Routing-Schleifen (count to infinity) zu unterscheiden. Der sicherste Ansatz besteht daher darin, die Route zu entfernen, wenn die Anzahl der Hops zunimmt. Wenn die Route immer noch legitim ist, wird sie bis zum nächsten Update neu installiert. Dies führt zu einem ausgelösten Update, durch das die Route an einer anderen Stelle im System neu installiert wird.
Generell können Distanzvektoralgorithmen1 neue Routen einfach übernehmen. Das Problem besteht darin, alte Geräte vollständig aus dem System zu entfernen. Daher sollte eine Regel, die verdächtige Routen übermäßig aggressiv entfernt, sicher sein.
Details des Aktualisierungsprozesses
Die in den Abbildungen 4 bis 8 beschriebenen Prozesse sind für die Verarbeitung eines einzelnen Netzwerkprotokolls bestimmt, z. B. TCP/IP, DECnet oder das ISO/OSI-Protokoll. Protokolldetails werden jedoch nur für TCP/IP angegeben. Ein Gateway kann Daten verarbeiten, die mehreren Protokollen folgen. Da jedes Protokoll unterschiedliche Adressierungsstrukturen und Paketformate aufweist, wird der Computercode, der zur Implementierung der Abbildungen 4 bis 8 verwendet wird, für jedes Protokoll im Allgemeinen unterschiedlich sein. Der in Abbildung 4 beschriebene Prozess unterscheidet sich am stärksten, wie in den ausführlichen Hinweisen zu Abbildung 4 beschrieben. Die in Abbildung 5 bis 8 beschriebenen Prozesse weisen den gleichen allgemeinen Aufbau auf. Der Hauptunterschied zwischen den einzelnen Protokollen besteht im Format des Routing-Update-Pakets, das für die Kompatibilität mit einem bestimmten Protokoll ausgelegt sein muss.
Beachten Sie, dass die Definition eines Ziels von Protokoll zu Protokoll variieren kann. Das hier beschriebene Verfahren kann für das Routing zu einzelnen Hosts, zu Netzwerken oder für komplexere hierarchische Adressschemata verwendet werden. Welcher Routing-Typ verwendet wird, hängt von der Adressierungsstruktur des Protokolls ab. Die aktuelle TCP/IP-Implementierung unterstützt nur Routing zu IP-Netzwerken. "Ziel" bedeutet also wirklich IP-Netzwerk- oder Subnetz-Nummer. Subnetzinformationen werden nur für verbundene Netzwerke gespeichert.
Die Abbildungen 4 bis 7 zeigen den Pseudocode für verschiedene Teile des Routingprozesses, die von den Gateways verwendet werden. Zu Beginn des Programms werden akzeptable Protokolle und Parameter eingegeben, die jede Schnittstelle beschreiben.
Das Gateway verarbeitet nur bestimmte Protokolle, die in der Liste aufgeführt sind. Jegliche Kommunikation von einem System, das ein Protokoll verwendet, das nicht in der Liste aufgeführt ist, wird ignoriert. Die Dateneingaben sind:
-
Netzwerke, mit denen das Gateway verbunden ist.
-
Ungeladene Bandbreite jedes Netzwerks.
-
Topologische Verzögerung jedes Netzwerks.
-
Zuverlässigkeit jedes Netzwerks
-
Kanalbelegung jedes Netzwerks
-
MTU der einzelnen Netzwerke.
Die metrische Funktion für jeden Datenpfad wird dann gemäß Gleichung 1 berechnet. Beachten Sie, dass die ersten drei Elemente relativ dauerhaft sind. Sie sind eine Funktion der zugrunde liegenden Netzwerktechnologie und nicht von der Last abhängig. Sie können aus einer Konfigurationsdatei oder durch direkte Eingabe des Operators festgelegt werden. Beachten Sie, dass IGRP keine gemessene Verzögerung verwendet. Sowohl die Theorie als auch die Erfahrung legen nahe, dass es für Protokolle mit gemessenen Verzögerungen sehr schwierig ist, ein stabiles Routing aufrechtzuerhalten. Es gibt zwei gemessene Parameter: Zuverlässigkeit und Kanalbelegung. Die Zuverlässigkeit basiert auf Fehlerquoten, die von der Hardware oder Firmware der Netzwerkschnittstelle gemeldet werden.
Zusätzlich zu diesen Eingaben benötigt der Routing-Algorithmus einen Wert für mehrere Routing-Parameter. Dazu gehören Timerwerte, Varianz und ob Holddowns aktiviert sind. Dies wird normalerweise durch eine Konfigurationsdatei oder eine Operatoreingabe festgelegt. (Ab Cisco Version 8.2 ist die Varianz dauerhaft auf 1 festgelegt.)
Nach der Eingabe der Anfangsinformationen werden Vorgänge im Gateway durch Ereignisse ausgelöst - entweder durch das Eintreffen eines Datenpakets an einer der Netzwerkschnittstellen oder durch den Ablauf eines Timers. Die in den Abbildungen 4 bis 7 beschriebenen Prozesse werden wie folgt ausgelöst:
-
Wenn ein Paket ankommt, wird es gemäß Abbildung 4 verarbeitet. Dies führt dazu, dass das Paket über eine andere Schnittstelle gesendet, verworfen oder zur weiteren Verarbeitung angenommen wird.
-
Wird ein Paket von dem Gateway zur Weiterverarbeitung angenommen, so wird es in einer in dieser Schrift nicht beschriebenen protokollspezifischen Weise analysiert. Wenn es sich bei dem Paket um ein Routing-Update handelt, wird es gemäß Abbildung 5 verarbeitet.
-
Abbildung 6 zeigt Ereignisse, die durch einen Zeitgeber ausgelöst wurden. Der Timer ist so eingestellt, dass er einmal pro Sekunde einen Interrupt generiert. Wenn der Interrupt auftritt, wird der in Abbildung 6 dargestellte Prozess ausgeführt.
-
Abbildung 7 zeigt eine Routing-Update-Unterroutine. Aufrufe dieser Unterroutine sind in den Abbildungen 5 und 6 dargestellt.
-
Außerdem zeigt Abbildung 8 Einzelheiten der in den Abbildungen 5 und 7 genannten metrischen Berechnungen.
Es gibt vier kritische Zeitkonstanten, die die Weiterleitung und den Ablauf von Routen steuern. Diese Zeitkonstanten können vom Systemadministrator festgelegt werden. Es gibt jedoch Standardwerte. Diese Zeitkonstanten sind:
-
Broadcast-Zeit - Updates werden so häufig von allen Gateways an allen verbundenen Schnittstellen gesendet. Der Standardwert ist alle 90 Sekunden.
-
Ungültige Zeit - Wenn innerhalb dieser Zeit keine Aktualisierung für einen bestimmten Pfad empfangen wurde, liegt ein Timeout vor. Diese sollte das Mehrfache der Übertragungszeit betragen, damit Pakete, die ein Update enthalten, vom Netzwerk verworfen werden können. Der Standardwert ist das Dreifache der Sendezeit.
-
Haltezeit: Wenn ein Ziel nicht erreichbar ist (oder die Metrik so weit angehoben wurde, dass eine Vergiftung ausgelöst wurde), wird das Ziel blockiert. Während dieses Zustands wird für diesen Zeitraum kein neuer Pfad für dasselbe Ziel akzeptiert. Die Haltezeit gibt an, wie lange dieser Zustand andauern soll. Es sollte ein Mehrfaches der Sendezeit sein. Der Standardwert ist das Dreifache der Sendezeit plus 10 Sekunden. (Wie im Abschnitt Zurückstellungen deaktivieren beschrieben, können Sie Zurückstellungen deaktivieren.)
-
Flush Time (Löschzeit): Wenn innerhalb dieser Zeit kein Update für ein bestimmtes Ziel empfangen wurde, wird der Eintrag für dieses Ziel aus der Routing-Tabelle entfernt. Beachten Sie den Unterschied zwischen ungültiger Zeit und Leerungszeit: Nach Ablauf der ungültigen Zeit ist ein Pfad abgelaufen und wird entfernt. Wenn es keine verbleibenden Pfade zu einem Ziel gibt, ist das Ziel jetzt nicht erreichbar. Der Datenbankeintrag für das Ziel bleibt jedoch erhalten. Es muss bleiben, um den Holddown durchzusetzen. Nach der Leerungszeit wird der Datenbankeintrag aus der Tabelle entfernt. Sie sollte etwas länger sein als die ungültige Zeit zuzüglich der Haltezeit. Der Standardwert ist das 7-fache der Sendezeit.
Diese Zahlen setzen die folgenden Hauptdatenstrukturen voraus. Für jedes vom Gateway unterstützte Protokoll wird ein separater Satz dieser Datenstrukturen aufbewahrt. Innerhalb jedes Protokolls wird für jeden zu unterstützenden Diensttyp ein separater Satz von Datenstrukturen aufbewahrt.
Für jedes dem System bekannte Ziel gibt es eine (möglicherweise Null-)Liste von Pfaden zum Ziel, eine Verweildauer und eine letzte Aktualisierungszeit. Die letzte Aktualisierungszeit gibt an, wann ein Pfad für dieses Ziel zuletzt in eine Aktualisierung von einem anderen Gateway aufgenommen wurde. Beachten Sie, dass für jeden Pfad auch Aktualisierungszeiten gelten. Wenn der letzte Pfad zu einem Ziel entfernt wird, wird das Ziel zurückgehalten, es sei denn, die Zurückstellungen sind deaktiviert (weitere Informationen finden Sie im Abschnitt Zurückstellungen deaktivieren). Die Verfallszeit gibt den Zeitpunkt an, zu dem die Verweildauer abläuft. Die Tatsache, dass es sich um einen Wert ungleich null handelt, weist darauf hin, dass sich das Ziel im Holddown befindet. Um Berechnungszeit zu sparen, ist es auch sinnvoll, für jedes Ziel eine "beste Metrik" zu verwenden. Dies ist lediglich die Mindestanzahl der zusammengesetzten Metriken für alle Pfade zum Ziel.
Für jeden Pfad zu einem Ziel gibt es die Adresse des nächsten Hop im Pfad, die zu verwendende Schnittstelle, einen Vektor von Metriken, die den Pfad charakterisieren, einschließlich topologischer Verzögerung, Bandbreite, Zuverlässigkeit und Kanalbelegung. Außerdem werden jedem Pfad weitere Informationen zugeordnet, einschließlich Hop-Anzahl, MTU, Informationsquelle, Remote-Composite-Metrik und einer Composite-Metrik, die aus diesen Zahlen gemäß Gleichung 1 berechnet wird. Es gibt auch eine letzte Aktualisierungszeit. Die Informationsquelle gibt an, woher die letzte Aktualisierung für diesen Pfad stammt. In der Praxis entspricht dies der Adresse des nächsten Hop. Die letzte Aktualisierungszeit ist einfach die Zeit, zu der die letzte Aktualisierung für diesen Pfad angekommen ist. Sie wird verwendet, um Pfade mit Zeitüberschreitung zu beenden.
Beachten Sie, dass eine IGRP-Aktualisierungsnachricht drei Bereiche umfasst: Interieur, System (bedeutet "dieses autonome System", aber nicht Interieur) und Exterieur. Der Innenbereich ist für Routen zu Subnetzen vorgesehen. Nicht alle Subnetzinformationen sind enthalten. Es sind nur Subnetze eines Netzwerks enthalten. Dies ist das Netzwerk, das mit der Adresse verknüpft ist, an die das Update gesendet wird. Normalerweise werden Updates auf jeder Schnittstelle übertragen, also ist dies einfach das Netzwerk, in dem der Broadcast gesendet wird. (Weitere Fälle treten bei Antworten auf eine IGRP-Anfrage und Point-to-Point-IGRP auf.) Wichtige Netzwerke (z. B. Nicht-Subnetze) werden in den Systemteil der Aktualisierungsnachricht eingefügt, es sei denn, sie werden ausdrücklich als Extern markiert.
Ein Netzwerk wird als extern markiert, wenn es von einem anderen Gateway abgerufen wurde und die Informationen im externen Teil der Aktualisierungsnachricht eingegangen sind. Die Implementierung von Cisco ermöglicht es dem Systemadministrator, bestimmte Netzwerke als Extern zu deklarieren. Exterior-Routen werden auch als "Candidate Default" (Pleite-Kandidat) bezeichnet. Hierbei handelt es sich um Routen, die zu oder über Gateways verlaufen. Diese werden als Standard betrachtet und verwendet, wenn keine explizite Route zu einem Ziel vorhanden ist. Bei Rutgers konfigurieren wir beispielsweise das Gateway, das Rutgers mit unserem regionalen Netzwerk verbindet, sodass es die Route zum NSFnet-Backbone als Extern markiert. Die Implementierung bei Cisco wählt eine Standardroute aus, indem die externe Route mit der kleinsten Kennzahl ausgewählt wird.
Die folgenden Abschnitte sollen einige Abschnitte der Abbildungen 4 bis 8 verdeutlichen.
Paket-Routing
Abbildung 4 beschreibt die Gesamtverarbeitung von Eingangspaketen. Dies dient lediglich zur Verdeutlichung der Terminologie. Es ist offensichtlich, dass dies keine vollständige Beschreibung der Funktionen eines IP-Gateways ist.
Bei diesem Prozess werden die Liste der unterstützten Protokolle und die Informationen zu den Schnittstellen verwendet, die bei der Initialisierung des Gateways eingegeben werden. Die Details der Paketverarbeitung hängen vom vom Paket verwendeten Protokoll ab. Dies wird in Schritt A festgelegt. Schritt A ist der einzige Teil von Abbildung 4, der von allen Protokollen gemeinsam verwendet wird. Sobald der Protokolltyp bekannt ist, wird die Implementierung von Abbildung 4 entsprechend dem Protokolltyp verwendet. Einzelheiten zum Paketinhalt werden durch die Spezifikationen des Protokolls beschrieben. Die Spezifikationen eines Protokolls umfassen eine Prozedur zur Bestimmung des Ziels eines Pakets, eine Prozedur zum Vergleichen des Ziels mit den eigenen Adressen des Gateways, um zu bestimmen, ob das Gateway selbst das Ziel ist, eine Prozedur zur Bestimmung, ob ein Paket eine Broadcast ist, und eine Prozedur zur Bestimmung, ob das Ziel Teil eines bestimmten Netzwerks ist. Diese Verfahren werden in den Schritten B und C von Abbildung 4 verwendet. Der Test in Schritt D erfordert eine Suche nach den in der Routing-Tabelle aufgeführten Zielen. Der Test ist erfüllt, wenn ein Eintrag in der Routing-Tabelle für das Ziel vorhanden ist und diesem Ziel mindestens ein verwendbarer Pfad zugeordnet ist. Beachten Sie, dass die in diesem und im nächsten Schritt verwendeten Ziel- und Pfaddaten für jeden unterstützten Servicetyp separat verwaltet werden. Dieser Schritt beginnt also damit, den durch das Paket spezifizierten Diensttyp zu ermitteln und den entsprechenden Satz von Datenstrukturen auszuwählen, die für diesen und den nächsten Schritt verwendet werden sollen.
Ein Pfad kann für die Schritte D und E verwendet werden, wenn seine entfernte zusammengesetzte Metrik kleiner als seine zusammengesetzte Metrik ist. Ein Pfad, dessen entfernte zusammengesetzte Metrik größer ist als seine zusammengesetzte Metrik, ist ein Pfad, dessen nächster Hop, gemessen durch die Metrik, "weiter weg" vom Ziel ist. Dies wird als "Upstream-Pfad" bezeichnet. Normalerweise würde man erwarten, dass die Verwendung von Metriken die Auswahl von Upstream-Pfaden verhindert. Es ist leicht zu erkennen, dass ein Upstream-Pfad niemals der beste sein kann. Wenn jedoch eine große Varianz zulässig ist, können andere Pfade als die besten verwendet werden. Einige davon könnten Upstream sein.
In Schritt E wird der zu verwendende Pfad berechnet. Pfade, deren entfernte zusammengesetzte Metrik nicht kleiner als ihre zusammengesetzten Metriken ist, werden nicht berücksichtigt. Wenn mehr als ein Pfad akzeptabel ist, werden solche Pfade in einer gewichteten Form des Round-Robin-Wechsels verwendet. Die Frequenz, mit der ein Pfad verwendet wird, ist umgekehrt proportional zu seiner zusammengesetzten Metrik.
Empfang von Routing-Updates
Abbildung 5 beschreibt die Verarbeitung einer Routing-Aktualisierung, die von einem benachbarten Gateway empfangen wurde. Solche Updates bestehen aus einer Liste von Einträgen, die jeweils Informationen für ein einziges Ziel enthalten. Bei einem Routing-Update können mehrere Einträge für dasselbe Ziel vorhanden sein, um mehrere Servicetypen zu berücksichtigen. Jeder dieser Einträge wird einzeln verarbeitet, wie in Abbildung 5 beschrieben. Wenn sich ein Eintrag im äußeren Abschnitt der Aktualisierung befindet, wird die äußere Markierung für das Ziel festgelegt, wenn sie als Ergebnis dieses Prozesses hinzugefügt wird.
Der gesamte in Abbildung 5 beschriebene Prozess muss einmal für jeden vom Gateway unterstützten Diensttyp wiederholt werden. Dabei werden die Ziel-/Pfadinformationen verwendet, die mit diesem Diensttyp verknüpft sind. Dies wird in der äußersten Schleife in Abbildung 5 gezeigt. Die gesamte Routing-Aktualisierung muss für jeden Diensttyp einmal verarbeitet werden. (Beachten Sie, dass die aktuelle IGRP-Implementierung mehrere Diensttypen nicht unterstützt, sodass die äußerste Schleife nicht tatsächlich implementiert wird.)
In Schritt A werden grundlegende Annehmbarkeitstests für den Pfad durchgeführt. Dies sollte Plausibilitätstests für das Ziel umfassen. Unmögliche ("marsianische") Netzwerknummern sollten abgelehnt werden. (Weitere Informationen finden Sie unter RFC 1009![]() und RFC 1122
und RFC 1122![]() .) Aktualisierungen werden auch dann abgelehnt, wenn sich das Ziel, auf das sie sich beziehen, im Holddown befindet, d. h. wenn die Holddown-Ablaufzeit ungleich null und später als die aktuelle Zeit ist.
.) Aktualisierungen werden auch dann abgelehnt, wenn sich das Ziel, auf das sie sich beziehen, im Holddown befindet, d. h. wenn die Holddown-Ablaufzeit ungleich null und später als die aktuelle Zeit ist.
In Schritt B wird in der Routing-Tabelle gesucht, ob dieser Eintrag einen bereits bekannten Pfad beschreibt. Ein Pfad in der Routing-Tabelle wird definiert durch das Ziel, mit dem er verknüpft ist, den nächsten Hop, der als Teil des Pfads aufgeführt wird, die für den Pfad zu verwendende Ausgabeschnittstelle und die Informationsquelle (die Adresse, von der das Update stammt - in der Praxis normalerweise die gleiche wie der nächste Hop). Der Eintrag aus dem Aktualisierungspaket beschreibt einen Pfad, dessen Ziel im Eintrag aufgelistet ist, dessen Ausgangsschnittstelle die Schnittstelle ist, in der das Update eingetroffen ist, und dessen nächster Hop und Informationsquelle die Adresse des Gateways ist, das das Update gesendet hat (die "Quelle" S).
In Schritt H und Schritt T wird der in Abbildung 7 beschriebene Aktualisierungsvorgang geplant. Dieser Prozess wird ausgeführt, nachdem der gesamte in Abbildung 5 beschriebene Prozess abgeschlossen ist. Das bedeutet, dass der in Abbildung 7 beschriebene Aktualisierungsvorgang nur einmal durchgeführt wird, selbst wenn er während der in Abbildung 5 beschriebenen Verarbeitung mehrmals ausgelöst wird. Außerdem müssen Vorkehrungen getroffen werden, um zu verhindern, dass Updates zu häufig veröffentlicht werden, wenn sich das Netzwerk schnell ändert.
Schritt K wird durchgeführt, wenn das Ziel, das durch den aktuellen Eintrag im Update-Paket beschrieben wird, bereits in der Routing-Tabelle vorhanden ist. K vergleicht die neue zusammengesetzte Metrik, die aus den Daten im Aktualisierungspaket berechnet wird, mit der besten zusammengesetzten Metrik für das Ziel. Beachten Sie, dass die beste zusammengesetzte Metrik zu diesem Zeitpunkt nicht neu berechnet wird. Wenn der berücksichtigte Pfad also bereits in der Routing-Tabelle enthalten ist, vergleicht dieser Test möglicherweise neue und alte Metriken für denselben Pfad.
Schritt L wird für die Pfade ausgeführt, die schlechter sind als die vorhandene beste zusammengesetzte Metrik. Dies umfasst sowohl neue Pfade, die schlechter sind als vorhandene, als auch bestehende Pfade, deren zusammengesetzte Metrik sich erhöht hat. Schritt L testet, ob der neue Pfad akzeptabel ist. Beachten Sie, dass dieser Test sowohl den Test, ob ein neuer Pfad gut genug ist, um zu halten, als auch die Route Poisoning implementiert. Um akzeptabel zu sein, darf der Verzögerungswert nicht der spezielle Wert sein, der ein nicht erreichbares Ziel angibt (für die aktuelle IP-Implementierung alle Werte in einem 24-Bit-Feld), und die zusammengesetzte Metrik (berechnet wie in Abbildung 8 angegeben) muss akzeptabel sein. Um festzustellen, ob die zusammengesetzte Metrik zulässig ist, vergleichen Sie sie mit den zusammengesetzten Metriken aller anderen Pfade zum Ziel. Lasst M das Minimum davon sein. Der neue Pfad ist akzeptabel, wenn er < V X M ist, WOBEI V DER VARIANZSATZ IST, WENN DAS GATEWAY INITIALISIERT WURDE. WENN V = 1 (WAS AB CISCO VERSION 8.2 IMMER DER FALL IST), IST EINE KENNZAHL, DIE SCHLECHTER IST ALS DIE VORHANDENE, NICHT AKZEPTABEL. DAVON GIBT ES EINE AUSNAHME: WENN DER PFAD BEREITS VORHANDEN IST UND DER EINZIGE PFAD ZUM ZIEL IST, WIRD DER PFAD BEIBEHALTEN, WENN DIE METRIK NICHT UM MEHR ALS 10 % ERHÖHT WURDE (ODER WENN DIE HALTEZAHL DEAKTIVIERT IST, WENN DIE HOPFZAHL NICHT ERHÖHT WURDE).
Schritt V wird ausgeführt, wenn die neuen Informationen für einen Pfad darauf hinweisen, dass die zusammengesetzte Metrik verringert wird. Die zusammengesetzten Metriken aller Pfade zum Ziel D werden verglichen. In diesem Vergleich wird die neue zusammengesetzte Metrik für P verwendet, nicht die, die in der Routing-Tabelle erscheint. Es wird die minimale zusammengesetzte Metrik M berechnet. Dann werden alle Wege nach D nochmals untersucht. Wenn die zusammengesetzte Metrik für einen Pfad > M x V ist, wird dieser Pfad entfernt. V ist die Varianz, die bei der Initialisierung des Gateways eingegeben wurde. (Ab Cisco Version 8.2 ist die Varianz dauerhaft auf 1 festgelegt.)
Regelmäßige Verarbeitung
Der in Abbildung 6 beschriebene Prozess wird einmal pro Sekunde ausgelöst. Dabei werden verschiedene Timer in der Routing-Tabelle überprüft, um festzustellen, ob sie abgelaufen sind. Diese Timer sind oben beschrieben.
In Schritt U wird der in Abbildung 7 beschriebene Prozess aktiviert.
Die Schritte R und S sind erforderlich, da die in der Routing-Tabelle gespeicherten zusammengesetzten Metriken von der Kanalbelegung abhängen, die sich im Laufe der Zeit aufgrund von Messungen ändert. Die Kanalbelegung wird regelmäßig neu berechnet, wobei ein gleitender Durchschnitt des gemessenen Datenverkehrs über die Schnittstelle verwendet wird. Wenn sich der neu berechnete Wert vom vorhandenen Wert unterscheidet, müssen alle zusammengesetzten Metriken, die diese Schnittstelle betreffen, angepasst werden. Jeder in der Routing-Tabelle angezeigte Pfad wird überprüft. Bei jedem Pfad, dessen nächster Hop die Schnittstelle "I" verwendet, wird die zusammengesetzte Metrik neu berechnet. Dies geschieht gemäß Gleichung 1, wobei als Kanalbelegung das Maximum des in der Routing-Tabelle gespeicherten Wertes als Teil der Pfadmetrik und die neu berechnete Kanalbelegung der Schnittstelle verwendet wird.
Aktualisierungsnachrichten generieren
Abbildung 7 beschreibt, wie das Gateway Aktualisierungsnachrichten generiert, die an andere Gateways gesendet werden. Für jede mit dem Gateway verbundene Netzwerkschnittstelle wird eine separate Nachricht generiert. Diese Nachricht wird dann an alle anderen Gateways gesendet, die über die Schnittstelle erreichbar sind (Schritt J). Im Allgemeinen geschieht dies, indem die Nachricht als Broadcast gesendet wird. Wenn die Netzwerktechnologie oder das Netzwerkprotokoll jedoch keine Broadcasts zulässt, kann es erforderlich sein, die Nachricht einzeln an jedes Gateway zu senden.
Im Allgemeinen wird die Nachricht erstellt, indem in Schritt G für jedes Ziel ein Eintrag in der Routing-Tabelle hinzugefügt wird. Beachten Sie, dass die Ziel-/Pfaddaten, die den einzelnen Diensttypen zugeordnet sind, verwendet werden müssen. Im schlimmsten Fall wird der Aktualisierung für jedes Ziel für jeden Servicetyp ein neuer Eintrag hinzugefügt. Vor dem Hinzufügen eines Eintrags zur Aktualisierungsnachricht in Schritt G werden jedoch die bereits hinzugefügten Einträge gescannt. Wenn der neue Eintrag bereits in der Aktualisierungsnachricht vorhanden ist, wird er nicht erneut hinzugefügt. Ein neuer Eintrag dupliziert einen vorhandenen, wenn die Ziele und die Next-Hop-Gateways identisch sind.
Der Einfachheit halber lässt der Pseudocode eine Sache außen vor - IGRP-Aktualisierungsnachrichten bestehen aus drei Teilen: Innen-, System- und Außenbereich, was bedeutet, dass es tatsächlich drei Schleifen über Ziele gibt. Die erste beinhaltet nur Subnetze des Netzwerks, an die das Update gesendet wird. Das zweite umfasst alle wichtigen Netzwerke (z. B. Nicht-Subnetze), die nicht als extern gekennzeichnet sind. Das dritte umfasst alle größeren Netzwerke, die als extern gekennzeichnet sind.
Schritt E implementiert den Split Horizon Test. Im Normalfall schlägt dieser Test bei Routen fehl, deren bester Pfad über dieselbe Schnittstelle verläuft, über die das Update gesendet wird. Wenn das Update jedoch an ein bestimmtes Ziel gesendet wird (z. B. als Antwort auf eine IGRP-Anforderung von einem anderen Gateway oder als Teil von "Point-to-Point-IGRP"), schlägt Split Horizon nur fehl, wenn der beste Pfad ursprünglich von diesem Ziel kam (seine "Informationsquelle" ist die gleiche wie das Ziel) und seine Ausgangsschnittstelle dieselbe ist wie die Schnittstelle, von der die Anforderung kam.
Kennzahleninformationen berechnen
Abbildung 8 beschreibt, wie die Metrikinformationen aus Aktualisierungsnachrichten verarbeitet werden, die vom Gateway empfangen werden, und wie sie für Aktualisierungsnachrichten generiert werden, die vom Gateway gesendet werden. Beachten Sie, dass der Eintrag auf einem bestimmten Pfad zum Ziel basiert. Wenn es mehr als einen Pfad zum Ziel gibt, wird ein Pfad ausgewählt, dessen zusammengesetzte Metrik das Minimum ist. Wenn mehr als ein Pfad die minimale zusammengesetzte Metrik aufweist, wird eine beliebige Trennregel verwendet. (Bei den meisten Protokollen basiert dies auf der Adresse des nächsten Hop-Gateways.)
Abbildung 4: Verarbeiten eingehender Pakete
Data packet arrives using interface I
A Determine protocol used by packet
If protocol is not supported
then discard packet
B If destination address matches any of gateway's addresses
or the broadcast address
then process packet in protocol-specific way
C If destination is on a directly-connected network
then send packet direct to the destination, using
the encapsulation appropriate to the protocol and link type
D If there are no paths to the destination in the routing
table, or all paths are upstream
then send protocol-specific error message and discard the packet
E Choose the next path to use. If there are more than
one, alternate round-robin with frequency proportional
to inverse of composite metric.
Get next hop from path chosen in previous step.
Send packet to next hop, using encapsulation appropriate
to protocol and data link type.
Abbildung 5: Verarbeiten eingehender Routing-Updates
Routing update arrives from source S
For each type of service supported by gateway
Use routing data associated with this type of service
For each destination D shown in update
A If D is unacceptable or in holddown
then ignore this entry and continue loop with next destination D
B Compute metrics for path P to D via S (see Fig 8)
If destination D is not already in the routing table
then Begin
Add path P to the routing table, setting last
update times for P and D to current time.
H Trigger an update
Set composite metric for D and P to new composite
metric computed in step B.
End
Else begin (dest. D is already in routing table)
K Compare the new composite metric for P with best
existing metric for D.
New > old:
L If D is shown as unreachable in the update,
or holddowns are enabled and
the new composite metric >
(the existing metric for D) * V
[use 1.1 instead of V if V = 1,
as it is as of Cisco release 8.2]
O or holddowns are disabled and
P has a new hop count > old hop count
then Begin
Remove P from routing table if present
If P was the last route to D
then Unless holddowns are disabled
Set holddown time for D to
current time + holddown time
T and Trigger an update
End
else Begin
Compute new best composite metric for D
Put the new metric information into the
entry for P in the routing table
Add path P to the routing table if it
was not present.
Set last update times for P and D to
current time.
End
New <= OLD:
V Set composite metric for D and P to new
composite metric computed in step B.
If any other paths to D are now outside the
variance, remove them.
Put the new metric information into the
entry for P in the routing table
Set last update times for P and D to
current time.
End
End of for
End of for
Abbildung 6: Periodische Verarbeitung
Process is activated by regular clock, e.g. once per second
For each path P in the routing table (except directly
connected interfaces)
If current time < P'S LAST UPDATE TIME + INVALID TIME
THEN CONTINUE WITH THE NEXT PATH P
Remove P from routing table
If P was the last route to D
then Set metric for D to inaccessible
Unless holddowns are disabled,
Start holddown timer for D and
Trigger an update
else Recompute the best metric for D
End of for
For each destination D in the routing table
If D's metric is inaccessible
then Begin
Clear all paths to D
If current time >= D's last update time + flush time
then Remove entry for D
End
End of for
For each network interface I attached to the gateway
R Recompute channel occupancy and error rate
S If channel occupancy or error rate has changed,
then recompute metrics
End of for
At intervals of broadcast time
U Trigger update
Abbildung 7: Update generieren
Process is caused by "trigger update"
For each network interface I attached to the gateway
Create empty update message
For each type of service S supported
Use path/destination data for S
For each destination D
E If any paths to D have a next hop reached through I
then continue with the next destination
If any paths to D with minimal composite metric are
already in the update message
then continue with the next destination
G Create an entry for D in the update message, using
metric information from a path with minimal
composite metric (see Fig. 8)
End of for
End of for
J If there are any entries in the update message
then send it out interface I
End of for
Abbildung 8: Details der metrischen Berechnungen
In diesem Abschnitt wird das Verfahren zum Berechnen von Metriken und Hop-Zählern aus einer eingehenden Routing-Aktualisierung beschrieben. Die Eingabe in diese Funktion ist der Eintrag für ein bestimmtes Ziel in einem Routing-Update-Paket. Die Ausgabe ist ein Vektor von Metriken, mit denen die zusammengesetzte Metrik berechnet werden kann, sowie eine Hop-Anzahl. Wenn dieser Pfad zur Routing-Tabelle hinzugefügt wird, wird der gesamte Metrikvektor in die Tabelle eingegeben. Die in den folgenden Definitionen verwendeten Schnittstellenparameter entsprechen den Parametern, die bei der Initialisierung des Gateways für die Schnittstelle festgelegt wurden, an der die Routing-Aktualisierung ankam. Die Kanalbelegung und -zuverlässigkeit basieren jedoch auf einem gleitenden Durchschnitt des gemessenen Datenverkehrs durch die Schnittstelle.
-
Verzögerung = Verzögerung vom Paket + topologische Verzögerung der Schnittstelle
-
Bandbreite = max. (Bandbreite vom Paket, Schnittstellenbandbreite)
-
Zuverlässigkeit = min (Zuverlässigkeit des Pakets, Zuverlässigkeit der Schnittstelle)
-
Kanalbelegung = max. (Kanalbelegung vom Paket, Kanalbelegung der Schnittstelle)
(Max. wird für Bandbreite verwendet, da die Bandbreitenmetrik in inverser Form gespeichert wird. Vom Konzept her benötigen wir die Mindestbandbreite.) Beachten Sie, dass die ursprüngliche Kanalbelegung aus dem Paket gespeichert werden muss, da sie erforderlich ist, um die effektive Kanalbelegung neu zu berechnen, wenn sich die Kanalbelegung der Schnittstelle ändert.
Die folgenden Elemente sind nicht Teil des metrischen Vektors, sondern werden auch in der Routing-Tabelle als Eigenschaften des Pfades gespeichert:
-
Hop count = Hop count from packet .
-
MTU = min (MTU vom Paket, Schnittstellen-MTU).
-
Entfernte zusammengesetzte Metrik = wird aus Gleichung 1 unter Verwendung der metrischen Werte aus dem Paket berechnet. Das heißt, die metrischen Komponenten stammen aus dem Paket und werden nicht wie oben dargestellt aktualisiert. Dies muss natürlich vor der Durchführung der oben dargestellten Anpassungen berechnet werden.
-
Composite metric = wird aus Gleichung 1 unter Verwendung der Metrikwerte berechnet, die wie in diesem Abschnitt beschrieben berechnet werden.
Im verbleibenden Teil dieses Abschnitts werden die Verfahren zur Berechnung der Metriken und der Hop-Anzahl für das Senden von Routing-Updates beschrieben.
Diese Funktion bestimmt die Metrikinformationen und die Anzahl der Hops, die in ein ausgehendes Aktualisierungspaket eingefügt werden sollen. Es basiert auf einem bestimmten Pfad zu einem Ziel, sofern nutzbare Pfade vorhanden sind. Wenn es keine Pfade gibt oder alle Pfade Upstream sind, wird das Ziel als "unzugreifbar" bezeichnet.
If destination is inaccessible, this is indicated by using a specific
value in the delay field. This value is chosen to be larger
than the largest valid delay. For the IP implementation this is
all ones in a 24-bit field.
If destination is directly reachable through one of the interfaces, use
the delay, bandwidth, reliability, and channel occupancy of the
interface. Set hop count to 0.
Otherwise, use the vector of metrics associated with the path in the
routing table. Add one to the hop count from the path in the
routing table.
Details zur IP-Implementierung
In diesem Abschnitt werden die vom Cisco IGRP verwendeten Paketformate beschrieben. IGRP wird mithilfe von IP-Datagrammen mit dem IP-Protokoll 9 (IGP) gesendet. Das Paket beginnt mit einem Header. Er beginnt unmittelbar nach dem IP-Header.
unsigned version: 4; /* protocol version number */
unsigned opcode: 4; /* opcode */
uchar edition; /* edition number */
ushort asystem; /* autonomous system number */
ushort ninterior; /* number of subnets in local net */
ushort nsystem; /* number of networks in AS */
ushort nexterior; /* number of networks outside AS */
ushort checksum; /* checksum of IGRP header and data */
Bei Aktualisierungsnachrichten folgen Routing-Informationen unmittelbar nach dem Header.
Die Versionsnummer lautet derzeit 1. Pakete mit anderen Versionsnummern werden ignoriert.
Der Opcode kann 1 = update oder 2 = request sein.
Zeigt den Meldungstyp an. Das Format der beiden Nachrichtentypen wird unten angegeben.
Edition ist eine Seriennummer, die bei jeder Änderung der Routing-Tabelle erhöht wird. (Dies geschieht unter den Bedingungen, unter denen der oben gezeigte Pseudocode einen Routing-Update auslöst.) Mit der Editionsnummer können Gateways die Verarbeitung von Updates vermeiden, die bereits angezeigte Informationen enthalten. (Dies ist derzeit nicht implementiert. Das heißt, die Editionsnummer wird korrekt generiert, aber bei der Eingabe ignoriert. Da Pakete verworfen werden können, ist nicht klar, ob die Editionsnummer ausreicht, um eine doppelte Verarbeitung zu vermeiden. Es muss sichergestellt werden, dass alle der Edition zugeordneten Pakete verarbeitet wurden.)
Ein System ist die autonome Systemnummer. In der Cisco-Implementierung kann ein Gateway an mehr als einem autonomen System teilnehmen. Jedes dieser Systeme führt sein eigenes IGRP-Protokoll aus. Konzeptionell gibt es für jedes autonome System komplett separate Routing-Tabellen. Routen, die über IGRP von einem autonomen System eingehen, werden nur in Updates für dieses AS gesendet. In diesem Feld kann das Kabelmodem auswählen, welche Routing-Tabellen für die Verarbeitung dieser Nachricht verwendet werden sollen. Wenn das Gateway eine IGRP-Nachricht für ein AS empfängt, für das es nicht konfiguriert ist, wird es ignoriert. Mit der Implementierung von Cisco können Informationen von einem AS zu einem anderen "durchsickern". Ich betrachte dies jedoch als administratives Instrument und nicht als Teil des Protokolls.
Ninside, nsystem und nexterior geben die Anzahl der Einträge in jedem der drei Abschnitte von Update-Nachrichten an. Diese Abschnitte wurden oben beschrieben. Zwischen den Abschnitten gibt es keine andere Abgrenzung. Die ersten Inneneinträge werden als Interieur, die nächsten Systemeinträge als System und die letzten Außeneinträge als Exterieur betrachtet.
Prüfsumme ist eine IP-Prüfsumme, die mit demselben Prüfsummenalgorithmus wie eine UDP-Prüfsumme berechnet wird. Die Prüfsumme wird für den IGRP-Header und alle nachfolgenden Routing-Informationen berechnet. Das Prüfsummenfeld wird bei der Berechnung der Prüfsumme auf Null gesetzt. Die Prüfsumme enthält weder den IP-Header noch einen virtuellen Header wie bei UDP und TCP.
Anfragen
Eine IGRP-Anfrage fordert den Empfänger auf, seine Routing-Tabelle zu senden. Die Anforderungsnachricht hat nur einen Header. Es werden nur die Felder version, opcode und asystem verwendet. Alle anderen Felder sind Null. Es wird erwartet, dass der Empfänger eine normale IGRP-Aktualisierungsnachricht an den Antragsteller sendet.
Updates
Eine IGRP-Aktualisierungsnachricht enthält einen Header, gefolgt von Routingeinträgen. Es sind so viele Routingeinträge enthalten, wie in ein 1500-Byte-Datagramm passen (einschließlich IP-Header). Bei aktuellen Strukturdeklarationen sind bis zu 104 Einträge möglich. Wenn weitere Einträge erforderlich sind, werden mehrere Aktualisierungsnachrichten gesendet. Da Aktualisierungsnachrichten nur Eintrag für Eintrag verarbeitet werden, ist es nicht von Vorteil, eine einzelne fragmentierte Nachricht zu verwenden, anstatt mehrere unabhängige zu verwenden.
Hier sehen Sie die Struktur eines Routing-Eintrags:
uchar number[3]; /* 3 significant octets of IP address */
uchar delay[3]; /* delay, in tens of microseconds */
uchar bandwidth[3]; /* bandwidth, in units of 1 Kbit/sec */
uchar mtu[2]; /* MTU, in octets */
uchar reliability; /* percent packets successfully tx/rx */
uchar load; /* percent of channel occupied */
uchar hopcount; /* hop count */
Die Felder uchar[2] und uchar[3] sind einfach 16- und 24-Bit-Binärzahlen in normaler IP-Netzwerkreihenfolge.
Nummer definiert das zu beschreibende Ziel. Dies ist eine IP-Adresse. Um Platz zu sparen, werden nur die ersten 3 Bytes der IP-Adresse angegeben, außer im inneren Abschnitt. Im Innenbereich sind die letzten 3 Bytes angegeben. Bei System- und externen Routen sind keine Subnetze möglich, sodass das Byte niedriger Ordnung immer Null ist. Interne Routen sind immer Subnetze eines bekannten Netzwerks, sodass das erste Byte dieser Netzwerknummer bereitgestellt wird.
Die Verzögerung beträgt 10 Mikrosekunden. Dies ergibt einen Bereich von 10 Mikrosekunden bis 168 Sekunden, was ausreichend erscheint. Eine Verzögerung aller Antworten zeigt an, dass das Netzwerk nicht erreichbar ist.
Die Bandbreite ist die inverse Bandbreite in Bits pro Sekunde, skaliert um den Faktor 1,0e10. Der Bereich reicht von einer Leitung mit 1200 BPS bis zu 10 Gbit/s. (Wenn die Bandbreite also N Kbit/s beträgt, wird 10000000/N verwendet.)
Die MTU wird in Byte angegeben.
Die Zuverlässigkeit ist als Anteil von 255 angegeben, d.h. 255 ist 100%.
Die Last wird als Bruchteil von 255 angegeben.
Die Anzahl der Hops ist eine einfache Anzahl.
Aufgrund der etwas seltsamen Einheiten, die für Bandbreite und Verzögerung verwendet werden, scheinen einige Beispiele der Reihe nach zu sein. Dies sind die Standardwerte, die für mehrere gängige Medien verwendet werden.
Delay Bandwidth
--------------- -------------------
Satellite 200,000 (2 sec) 20 (500 Mbit)
Ethernet 100 (1 ms) 1,000
1.544 Mbit 2000 (20 ms) 6,476
64 Kbit 2000 156,250
56 Kbit 2000 178,571
10 Kbit 2000 1,000,000
1 Kbit 2000 10,000,000
Metrische Berechnungen
Im Folgenden wird beschrieben, wie die zusammengesetzte Kennzahl in Cisco Version 8.0(3) berechnet wird.
metric = [K1*bandwidth + (K2*bandwidth)/(256 - load) + K3*delay] *
[K5/(reliability + K4)]
If K5 == 0, the reliability term is not included.
The default version of IGRP has K1 == K3 == 1, K2 == K4 == K5 == 0
Zugehörige Informationen
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
04-Sep-2002
|
Erstveröffentlichung |
 Feedback
Feedback