Cisco HyperFlex Powers Your Epic Environment End To End White Paper
Available Languages
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
In this document you will learn how to reduce costs and advance on your infrastructure adoption model (INFRAM) roadmap by running your entire Epic Electronic Health Record (EHR) environment on a hyperconverged infrastructure solution based on Cisco HyperFlex™ systems engineered for all-NVMe storage. With industry-leading high performance among hyperconverged solutions, HyperFlex can help your organization achieve the infrastructure component of the Epic Honor Roll Good Maintenance Program and meet future growth by scaling your compute and storage capacities with the elasticity of your own private cloud.
In 2015, Cisco began development of a next-generation hyperconverged infrastructure (HCI) solution. Built on a modern scale-out distributed file system and optimized to take advantage of the latest storage technologies including SAS, SATA, and NVMe SSDs, HyperFlex provides IT with an adaptable, scalable and future-ready platform for the data center, hybrid cloud, and distributed operations at the edge. In under three years, Cisco HyperFlex has the honor of going from launch to being named a leader in HCI by the Gartner Magic Quadrant in 2018 and again in 2019. A growing number of IT organizations around the world rely on HyperFlex to run Tier-1 mission-critical databases, including Microsoft SQL Server, Oracle, and SAP HANA. In this paper, we will discuss our work with Epic enabling an entire Epic EHR deployment to run on a HyperFlex solution.
One of the most dramatic changes in healthcare over the past 15 years has been the integration of information technology into care delivery. These innovations are significant, but they may have a less-than-desired impact without the network, compute, and storage capabilities that enable them to share and orchestrate information between systems and with the individuals who deliver care. But how do you understand where your information infrastructure gaps are and determine how to fill them?
Cisco started the work
In 2015, Cisco began to help healthcare providers answer this question with the infrastructure maturity assessment. This work was built around studies within 30 major acute-care hospitals. It gave us insight on how to benchmark them on their journey; specifically, how to apply information infrastructure more effectively, how to support clinical staff, and how to run the clinical and operational applications that staff rely on.
HIMSS Analytics continues the work
In 2018, HIMSS Analytics assumed assessment development and built the HIMSS Infrastructure Adoption Model (INFRAM). This assessment helps you develop a roadmap for adopting technology over the next three to five years. We have collaborated on the pilot program along with other organizations from around the world.
INFRAM helps healthcare leaders assess and map the infrastructure capabilities required to reach their strategic and clinical business goals—and meet international benchmarks and standards. This international model has eight stages (0 to 7) for assessing infrastructure adoption and capability maturity (Table 1; see next page). With INFRAM, healthcare provider organizations can help improve care delivery, reduce cyber and infrastructure risk, and create a pathway for infrastructure development tied to business and clinical outcomes.
Once your infrastructure is progressing up the INFRAM stack, you can start to realistically deploy and protect your healthcare applications and data, including Electronic Medical Records (EMR). HIMSS Analytics has also developed a similar maturity model for EMR, called Electronic Medical Record Adoption Model (EMRAM), that measures the adoption and utilization of EMR functions. Meeting the requirements of each stage moves you closer to achieving a near paperless environment that harnesses technology to support optimized patient care.
The Cisco HyperFlex hyperconverged infrastructure solution with all-NVMe storage is engineered on Cisco Unified Computing System™ (Cisco UCS®) technology. This solution enables you to move much closer to your realization of both INFRAM and EMRAM.
Table 1. The INFRAM eight-stage model for assessing infrastructure adoption and capability maturity
| Stage |
INFRAM cumulative capabilities |
| 7 |
● Adaptive and flexible network control with software-defined networking
● Home-based telemonitoring
● Internet/TV on demand
|
| 6 |
● Software-defined network automated validation of experience
● On-premises enterprise/hybrid cloud application and infrastructure automation
|
| 5 |
● Video on mobile devices
● Location-based messaging
● Firewall with advanced malware protection
● Real-time scanning of hyperlinks in email messages
|
| 4 |
● Multiparty video capabilities
● Wireless coverage throughout most premises
● Active/active high availability
● Remote access VPN
|
| 3 |
● Advanced intrusion prevention system
● Rack/tower/blade server-based compute architecture
● End-to-end Quality of Service (QoS)
● Defined public and private cloud strategy
|
| 2 |
● Intrusion detection/protection
● Informal security policy
● Disparate systems centrally managed by multiple network management systems
|
| 1 |
● Static network configuration
● Fixed switch platform
● Active/standby failover
● LWAP (lightweight access point)-only single wireless controller
● Ad-hoc local storage networking
● No data center automation
|
| 0 |
● No VPN, intrusion detection/prevention, security policy, data center or compute architecture
|
The foundation of your fully automated data center
Cisco HyperFlex is a next-generation platform that incorporates software-defined computing, a cluster fabric with up to 100 Gbps of connectivity, industry-leading rack and blade servers, and a distributed, scale-out file system with best-in-class performance to support entire Epic workloads. Unlike first-generation hyperconverged systems, HyperFlex is a compute, storage, and network-integrated appliance providing quick installation, one-click full-stack software and firmware upgrades, and AI-powered, connected support through the Cisco Intersight™ software-as-a-service management platform.
End-to-end Epic on Cisco HyperFlex systems
Epic is a multilevel healthcare application with, at its heart, an operational database that stores electronic medical records data. Epic has very clear guidelines for deploying, maintaining, and accessing this database, such as requiring specific read-and-write response times. Many Epic installations often separate the database, presentation tier, and reporting on separate servers and storage infrastructure. HyperFlex, too, has been used in this approach, running the presentation tier for some large installations.
Integrating and operationalizing a multivendor ecosystem of compute, network, and storage resources requires IT organizations to achieve a certain level of resources, which can be challenging for small- and medium-size installations. For those providers, HyperFlex presents an alternative with a reliable and high-performance hyperconverged solution, providing a single scalable pool of resources to deploy the entire Epic system, including the operational database.
What is Cisco HyperFlex?
Cisco HyperFlex systems are hyperconverged infrastructure, delivered as an integrated cluster appliance engineered on Cisco UCS technology. By deploying our hyperconverged solutions from end to end, your healthcare organization can help ensure fast deployments and reliable delivery of critical patient support services.
Cisco HyperFlex systems integrate computing, storage, networking, and server virtualization into a single system. Storage is combined with computing and managed by a set of virtual machines running the Cisco HyperFlex HX Data Platform software. This creates a distributed, scale-out data platform with built-in replication for data redundancy and high availability. Cisco UCS fabric interconnects provide a managed, dedicated cluster network and storage backplane with embedded Cisco UCS Manager software providing policy-based server management. With HyperFlex, you can reduce complexity, increase infrastructure scalability, and make deployment and management fast and easy. This enables:
● Performance and efficiency. The Cisco HyperFlex HX Data Platform implements a distributed, log-structured file system that provides consistent, low latency and high throughput. Our nodes with all-NVMe storage integrate Intel® Optane™ and NVMe SSDs to meet the demands of high-performance workloads such as the operational database. Our data-striping architecture distributes I/O evenly across the cluster regardless of whether a workload runs on compute-only or converged nodes, enabling flexibility and efficiency by scaling compute and storage independently.
● Enterprise data services. HyperFlex provides data deduplication and compression, fast and space-efficient snapshots and clones, thin provisioning, and an optional acceleration engine to help lower your data footprint and cost of storage.
● Built-in data protection. You can use native snapshot, replication, and disaster recovery capabilities with the same data protection solutions you use in your data center, because Cisco HyperFlex systems interoperate with leading backup tools that support Epic deployments.
● Automated installation and setup. To reduce risk and simplify deployments, HyperFlex nodes come with VMware ESXi virtualization software preinstalled and ready to go. A wizard-driven installer takes out the guesswork by automating the setup of servers, hypervisors, data controllers, and virtual networks. If you are deploying virtual desktops or application virtualization, HyperFlex supports both Citrix Virtual Apps and Desktops and VMware Horizon as the desktop or application presentation layer.
● Adaptive infrastructure. You can connect third-party storage to the same fabric interconnects as for the HyperFlex cluster, including existing block-based storage or network-attached storage arrays. These devices can be used as additional data stores to facilitate migrating workloads from existing storage onto the HyperFlex cluster.
Cisco HyperFlex systems support the latest 2nd Gen Intel Xeon® Scalable processors; its scale-out architecture brings the pay-as-you-grow economics of public clouds to IT infrastructure. An innovative server cluster design that can be stretched across local areas and distant geographies combines with an integrated network fabric, powerful data optimization capabilities, storage management, and your choice of hypervisor to bring the full potential of hyperconvergence to your Epic applications and users (Figure 1).
Performance scales out linearly as you scale the cluster, spreading workloads across the growing pool of compute and storage resources. Cisco HyperFlex HX-Series Nodes optimize storage tiers for an excellent balance between price and performance. Cisco HyperFlex All NVMe Nodes deliver the highest performance for the most demanding workloads with a caching tier on Intel Optane SSDs and a persistent tier provided by NVMe SSDs. Nodes with all-NVMe storage provide a performance edge with drives connected directly to the CPU rather than through a bandwidth-constraining controller or a latency-inducing PCIe switch. With the Epic solution, the operational database resides on Intel 3D NAND SSDs. Write operations to the database are accelerated by the Intel Optane drives, while the persistent tier of NVMe SSDs provides the storage capacity and enables high-throughput low-latency access to large volumes of patient data. With our all-NVMe solution, you can unleash CPU power and reduce bottlenecks so that you get better response times from your applications.

Cisco HyperFlex systems with both compute and storage and compute-only nodes
Why Cisco HyperFlex all-NVMe solutions for your entire Epic suite?
Cisco HyperFlex systems deliver many other business benefits.
Fast application response for clinicians
Your clinical staff interacts with the familiar Epic Hyperspace interface to deliver patient care. You have the freedom to choose from industry-leading virtualization providers, Citrix or VMware, to deliver the infrastructure behind Epic’s presentation layer. No matter which provider you choose, HyperFlex delivers low-latency access and consistent performance to the presentation layer and simplifies its management. The unique I/O striping mechanism in the data platform distributes the workload evenly across the cluster, preventing performance hotspots and facilitating predictable and consistent performance for each virtual machine or desktop. The combination of virtualized Hyperspace with virtual application and desktop solutions on Cisco HyperFlex can help you deliver the access your clinical staff needs and meet Epic’s guidance for storage performance.
Storage connection resiliency
The node’s capacity layer is supported by NVMe SSDs. Integrated directly into the CPU through the PCIe bus, they eliminate the latency of disk controllers and PCIe switches as well as the CPU cycles needed to process storage protocols. However, without a disk controller to insulate the CPU from the drives, the CPU would be trying to handle drive faults. To eliminate this risk, we have implemented RAS features by integrating the Intel Volume Management Device driver into the data platform software. This engineered solution handles surprise drive removal, hot-plug capability, locator LEDs, and status lights.
Cloud-like infrastructure management simplicity
Automated deployment and management are provided through Cisco Intersight software. Intersight can support all of your clusters from the cloud or a local management server to wherever they reside, from the data center to the edge (Figure 2). Because we designed our systems to be deployed, provisioned, and managed through an API, our products are simpler, and so are our tools. You can use Cisco Intersight to perform nondisruptive operations, rolling upgrades, scaling, and server, fabric, and storage provisioning, as well as device discovery, inventory, configuration, diagnostics, monitoring, fault detection, auditing, and statistics collection.
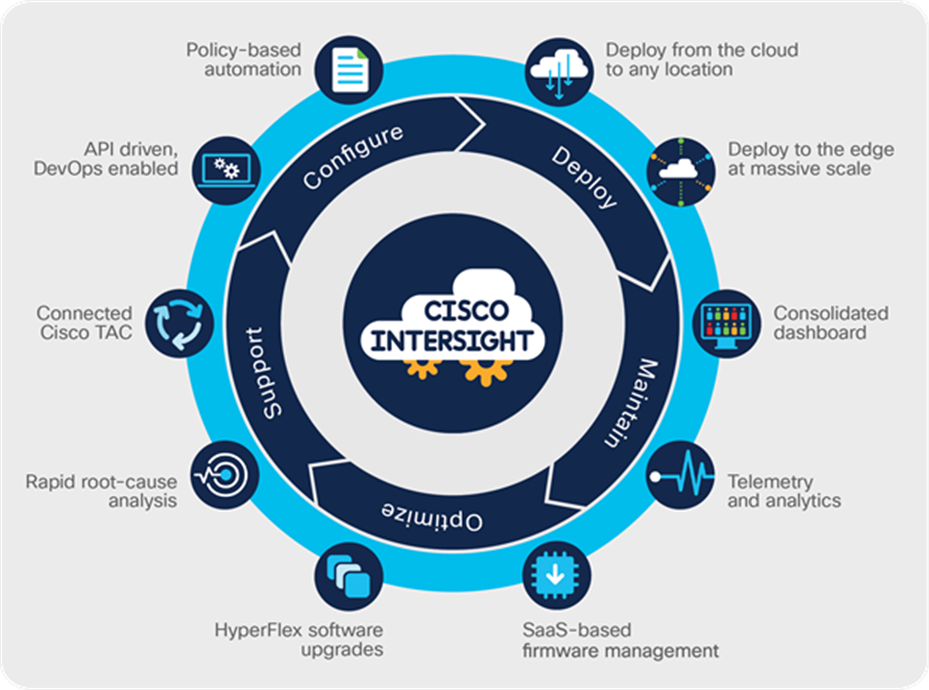
Cisco Intersight management platform supports every aspect of the infrastructure lifecycle
Tight integration with Cisco® Technical Assistance Center (TAC) enables telemetry information to be uploaded to speed problem resolution. The recommendation engine can advise you if any configuration parameters deviate from what is optimal.
If you prefer local management, you have two choices:
● The Cisco Intersight Virtual Management Appliance provides you with all of the continually updated, software-as-a-service benefits of the cloud-hosted version of Cisco Intersight.
● Cisco HyperFlex Connect is a smart dashboard that shows metrics and trends and supports your entire cluster management lifecycle. These functions also can be accessed through the Cisco Intersight platform.
● Third-party tool plug-ins provide a seamless experience by translating many of the cluster management functions into existing software tools such as VMware vCenter.
Right-sized configurations
There’s no need to overprovision your hardware. We are prepared to size your implementation for today with plans to support your environment three years into the future. These planning assessments help reduce the amount of hardware, software licenses, and support you purchase up front. You can expand as your infrastructure and enterprise applications grow.
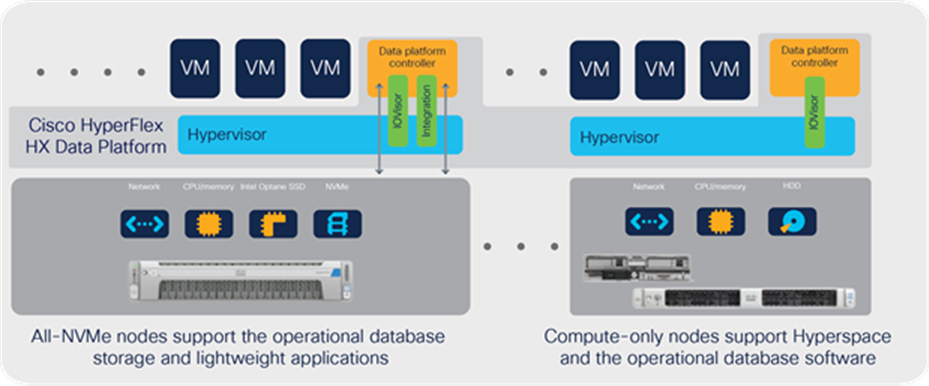
Scale only what your environment needs with compute-only and compute with storage nodes
Independent resource scaling
Our hyperconverged solution enables you to grow computing and storage independently; compute-only nodes (blade or rack servers) can be used without additional HyperFlex software license cost. You can use HyperFlex nodes to achieve a balance of computing and storage capacity, or compute-only nodes to increase the cluster’s computing power (Figure 3). This is an important feature that simplifies the implementation of Epic on HyperFlex. The NVMe-equipped capacity nodes support the operational database and support a lightweight workload. The database software and Hyperspace environment are hosted on compute-only nodes deployed as Cisco UCS B200 M5 Blade Servers. All nodes have equal access to storage through the HyperFlex data platform, and all nodes are part of an easy-to-manage cluster.
Migrating from expensive platforms
New x86-architecture processors lead the market and deliver higher levels of performance than the RISC processors in your data center. You can move from expensive systems to high-performance platforms that cost less to acquire and maintain. And you can choose workhorse processors with lower core counts and higher frequencies to help reduce software license costs.
Reduced risk
The highly automated nature of Cisco HyperFlex systems helps reduce the risk of downtime associated with common lifecycle management tasks (such as firmware upgrades and system refresh). The built-in resiliency of the data platform secures your data from the start. Additionally, Cisco has spent hundreds of engineering hours on creating sizing tools and Cisco Validated Designs to take the guess work out of sizing and deploying your end-to-end solution on Cisco HyperFlex systems.
Cisco HyperFlex systems running Epic
The Epic suite is made up of a number of software components that work together to create a cohesive healthcare solution. The following components are deployed, depending on your business needs:
● Operational database is the heart of the solution.
● Epic Hyperspace client presentation is the interface into the patient medical records that your staff interacts with.
● Cogito Clarity analytics and reporting is a part of the Epic Enterprise Intelligence suite that delivers a central repository for clinical, financial, and business data.
● Web and server services are a combination of Epic and Windows services that are extensions to and enablers for these other applications in the suite.
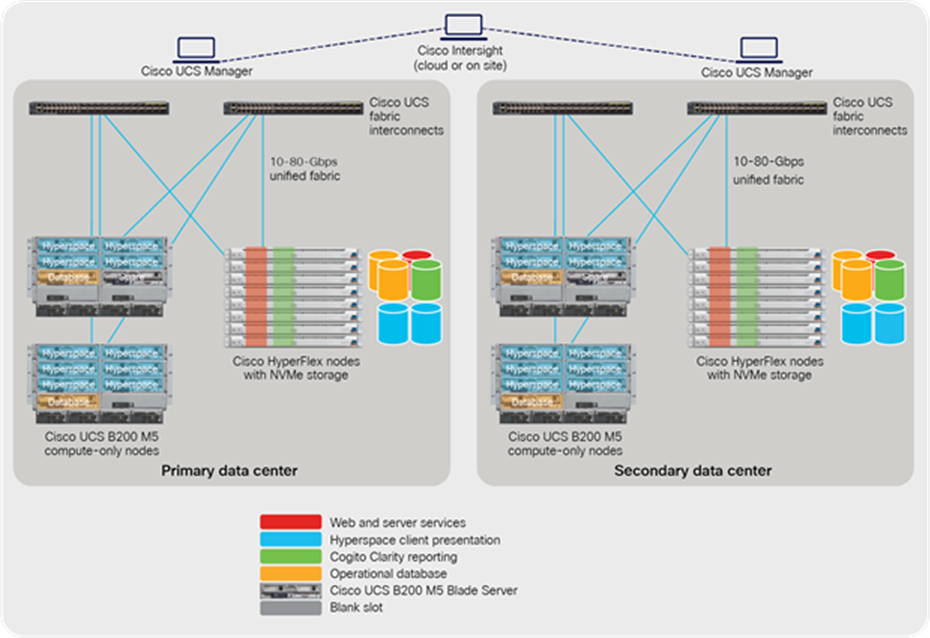
Epic deployed across a Cisco HyperFlex cluster that includes all-NVMe nodes and compute-only nodes
A single Cisco HyperFlex cluster is able to run the entire Epic suite. Figure 4 presents an example of deployment across two data centers. Depending on your environment and business needs, your configuration may not exactly match this one; however, we will help you size and configure your solution to meet your needs.
Each data center location hosts a single HyperFlex cluster with a heterogeneous set of nodes, all of which access the cluster’s storage through local interfaces to the data platform. Each cluster is integrated with Cisco UCS fabric interconnects.
Cisco HyperFlex nodes
Cisco HyperFlex HX220c M5 All NVMe Nodes are capacity nodes engineered for NVMe storage. They are configured with Intel 3D NAND NVMe SSDs for capacity, and Intel Optane DC P4800X SSDs for caching. These nodes deliver 71 percent more IOPS with 37 percent lower latency when measured using a simulated Oracle OLTP workload and compared to our previous-generation all- Flash nodes. Each node includes a data platform controller that implements the distributed scale-out file system. The controllers communicate with each other over 40 Gigabit Ethernet to present a single pool of storage that spans the nodes in the cluster. As nodes are added, the cluster scales linearly to deliver computing, storage capacity, and I/O performance. All nodes in the cluster support virtualized workloads and have equal access to storage. The nodes with all-NVMe storage host a light workload so that the cluster’s CPUs are able to deliver high storage performance to the rest of the solution components running on blade servers.
Compute-only nodes
Cisco UCS B200 M5 Blade Servers are used to support the operational database software and the Hyperspace virtual desktop environment. These applications are pinned to the blade servers, although technically they could run anywhere in the cluster. Integrated into the HyperFlex cluster, these nodes are considered compute-only in that they provide large amounts of computing power to the hosted applications but also have uniform access to the cluster’s storage.
Integrated networking
Cisco UCS fabric interconnects unite the cluster’s capacity and compute-only nodes into a single unified system. Unlike traditional hyperconverged environments, we integrated networking into the cluster from the beginning, with dual 10-, 25- or 40-Gbps connections to each node. This provides a high-bandwidth, low-latency network that scales uniformly as compute nodes are added to the system. The fabric interconnects are a single point of connectivity for the system and the blade servers connect into the fabric without the need for chassis-resident switches that can add latency to storage requests. The cluster uses Cisco SingleConnect technology to unify LAN, SAN, and systems management into a single set of cables for HyperFlex nodes, compute-only nodes, and virtual machines.
Simplified management
With hyperconverged infrastructure, simplicity is the key. In many management platforms, the underlying infrastructure is inflexible and complex, and that complexity extends to the management experience. We believe that simplicity should be an explicit choice, and that is the choice we have made. Your choices are discussed in the section “Cloud-like infrastructure management simplicity” on page 7.
Data center networking
Although out of the scope of this example configuration, Cisco Application Centric Infrastructure (Cisco ACI®) is software-defined networking that can connect the cluster to the enterprise data center and can be used to securely link deployments between multiple data centers. Cisco ACI can deliver the software-defined networking part of the INFRAM and EMRAM models discussed earlier. Cisco ACI helps automate for scale through a common policy for data center operations. Its pervasive security aids business continuity and disaster recovery. It can extend consistent policies between multiple data centers on premises and to cloud-hosted services. It can help you achieve a fundamentally more proactive deployment model and automate troubleshooting and root-cause analysis, and speed automation.
Cisco Nexus® 9200 Series Switches can be configured in multipod mode to span two HyperFlex clusters within the same location or in multisite mode to span across two clusters in different locations to ensure active/active high availability of your Epic applications. All ACI switches are deployed so that there is no single point of failure.
Performance testing Cisco HyperFlex systems running Epic
Epic tested multiple Cisco HyperFlex clusters to see how they performed. The tests evaluate how the Epic software stresses a system and its storage. Among the components of an Epic environment, the operational database is likely to have the most stringent performance requirements; therefore, it is critical to follow Epic’s guidance for storage performance requirement. As a generalized example, for random reads to database files measured at the system call level, the average read latencies must be 2 milliseconds or less. For random writes to database files measured at the system call level, the average write latencies must be 1 millisecond or less.
Cisco HyperFlex systems were tested for read performance, write performance, and burst IOPS. Three generations of systems were tested: Cisco HyperFlex M4 and M5 All Flash, and Cisco HyperFlex M5 All NVMe Nodes. The objective of the tests is to demonstrate performance that exceeds the current and peak application needs. This provides room for application and business expansion over a three- or four-year period without reaching performance limits during that period.
Read performance
The read performance test invoked random reads to operational database files and measured the average read latencies for the total IOPS exercised. As shown in Figure 5, a HyperFlex all-Flash solution running on the M4 or M5 generation of Cisco UCS servers was able to sustain the average total IOPS typical of a medium-size Epic environment while keeping the average read latency below 2 milliseconds. However, the M5 solution demonstrated 31 percent lower average read latency than the M4 solution. The HyperFlex M5 all-NVMe solution furthers this advantage. The M5 all-NVMe solution demonstrated a less than1-millisecond average read latency while sustaining the total IOPS of a medium sized environment of roughly 40,000 IOPS, and 36 percent lower average read latency than the M5 all-Flash solution. Furthermore, during performance tests, the M5 all-NVMe solution was able to maintain the average read latency under 2 milliseconds even as the total IOPS scaled to 162 percent of the typical medium-sized environment. This demonstrates how you can future-proof the solution against future capacity expansions.
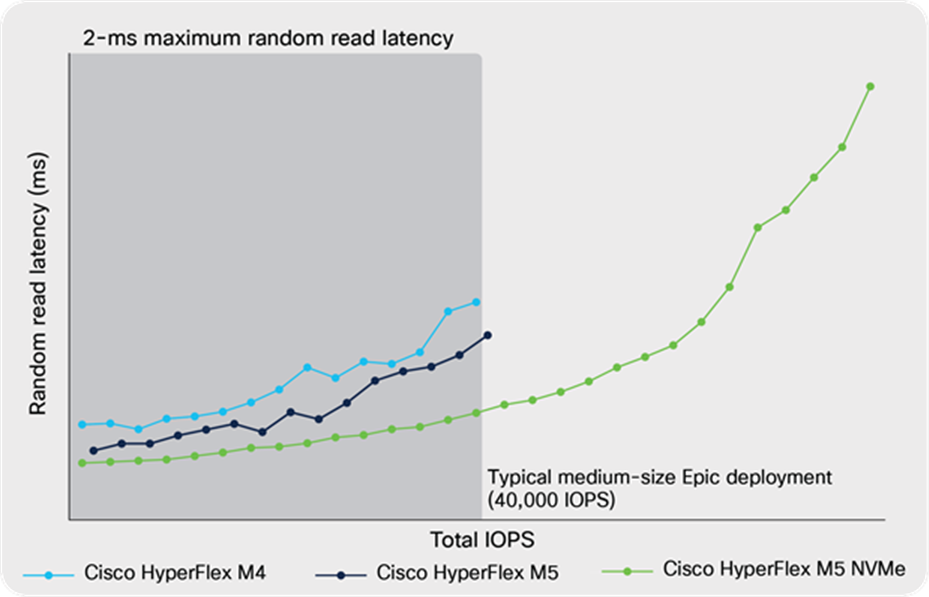
Random read average latency vs. total IOPS for Cisco HyperFlex M4 and M5 All Flash, and M5 All NVMe Nodes
Write performance
To evaluate write performance, Epic tests the ability to handle a very large bulk database insert in a short amount of time. Every 80 seconds, the operational database writes a 256 KB block. As illustrated by Figure 6 (on the next page), the M4 and M5 all-Flash nodes both are able to sustain the total IOPS of a typical medium-size environment while keeping average write latency below 1 millisecond. The M5 all-NVMe solution exceeded requirements by demonstrating a 35 percent lower average write latency compared to the M5 all-Flash solution. The write log device used in the all-NVMe nodes is provided by Intel Optane DC SSD P4800X SSDs, which can sustain high-frequency flushes while maintaining predictable response times. The capacity drives are Intel 3D NAND NVMe SSDs, which are integrated directly into the CPU through the PCIe bus, eliminating the latency of disk controllers and the CPU cycles needed to process SAS and SATA protocols. Furthermore, during testing, the write latency curve of the all-NVMe solution remained relatively flat even as the total IOPS increase to well beyond the amount for a typical medium size deployment. The all-NVMe solution provides an infrastructure that is well prepared to meet demand growth in the future.
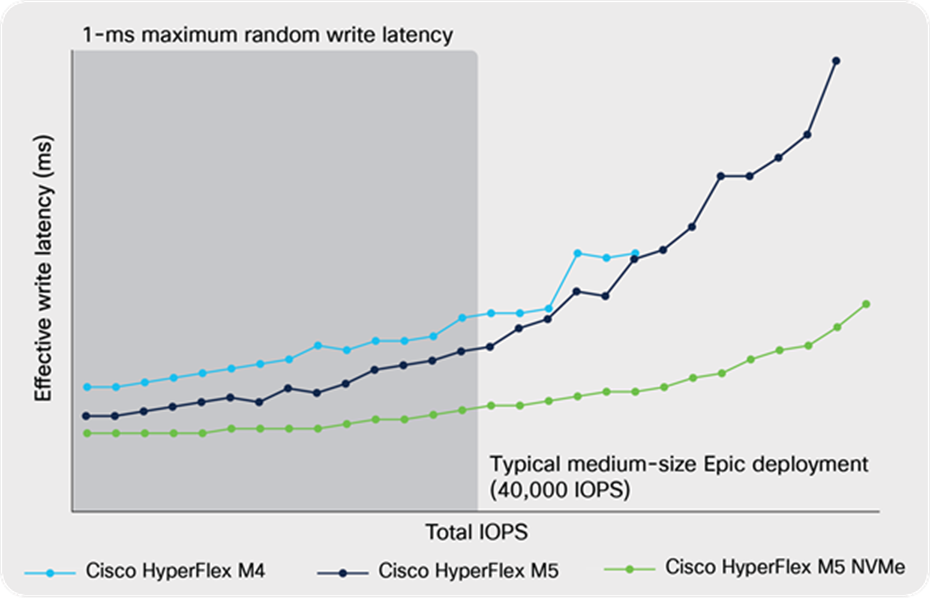
Write cycle length for Cisco HyperFlex M4 and M5 All Flash, and M5 All NVMe Nodes
Burst IOPS
The operational database demonstrates a “bursty” write pattern, in which writes are first made to memory and then sent to storage in bursts. To simulate the Epic environment, the burst IOPS test performs random writes to represent the activity of the other parts of the Epic suite. Occasionally, the operational database sends a burst of write activity to storage. The Epic team evaluates how the system responds to this mix of activity. Typically, you would want nearly linear performance as your average total IOPS increase. As shown in Figure 7 (on the next page), the all-NVMe solution showed that it can effectively handle the burst IOPS (operational database workload) and the average IOPS (combined workload from the other Epic components) simultaneously. For a medium-sized Epic environment, the tests show that the solution with all-NVMe storage is able to handle well over 150% the amount of burst IOPS of the total IOPS. This means you can reduce capital and operating expenses by using one infrastructure solution to support the entire Epic software suite.
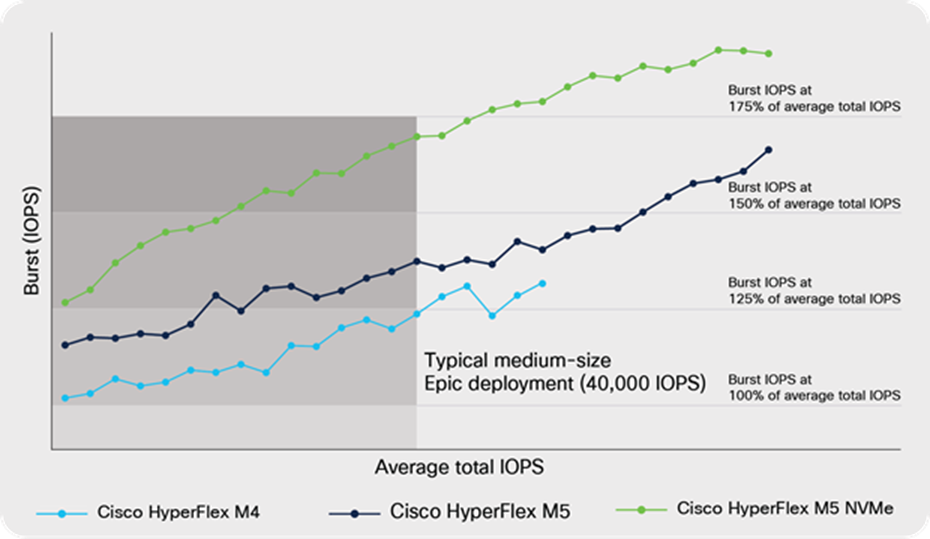
Burst IOPS performance for Cisco HyperFlex M4 and M5 All-Flash, and M5 All NVMe Nodes
Simplify and save costs with hyperconvergence
Your Cisco HyperFlex end-to-end healthcare solution is easy to size and simple to deploy, and meets your needs today and into the future. Rather than having to qualify, purchase, configure, integrate, network, and test a solution composed of individual servers and storage systems, our hyperconverged solution supports your Epic deployment with a single, easily integrated cluster that contains the server, storage, and networking capacity your healthcare organization needs.
Cisco HyperFlex is a next-generation hyperconverged solution that combines:
● Software-defined computing in the form of nodes based on Cisco UCS servers
● Software-defined storage with the powerful HyperFlex data platform
● Integrated networking with a fabric that is sized for your solution and doesn’t need to be changed as you grow
● Cloud-based or data center-resident management—your choice—to quickly configure, deploy, monitor, maintain, and scale your cluster
Together these elements comprise the infrastructure you need to support your Epic environment with the performance to carry you through the next three years of growth. We are committed to work with you and Epic to deliver a hyperconverged, end-to-end solution that meets your business needs today and into the future. Save time, cost, and time to service delivery with our end-to-end hyperconverged solution.
Let us come discuss how you can implement your Epic Hardware Configuration Guide on hyperconverged infrastructure with Cisco HyperFlex all-NVMe systems. Contact your Cisco sales representative.
We deliver more
Our all-NVMe solution delivers the performance and capacity you need to propel mission-critical workloads:
71% more IOPS
37% lower latency for a simulated Oracle OLTP workload compared to our previous-generation all-flash node1
57% more IOPS
34% lower latency for a Microsoft SQL Server workload compared to our previous-generation all-flash node2
Excellent financials
In March 2019, IDC prepared a white paper analyzing the business benefits of Cisco HyperFlex systems. For this paper, they interviewed organizations about their experiences running a variety of business workloads on Cisco HyperFlex systems. What they found was that, over a five-year period, organizations were seeing:
● 425% Return On Investment (ROI)
● 50% lower cost of operations
● 8-month payback
● 91% less unplanned downtime
● 50% faster development lifecycle
● 71% more efficient IT infrastructure teams
● 93% less staff time to deploy new servers
For more information