تحليل تأثير انقطاع التيار ل StarOS VNF
خيارات التنزيل
-
ePub (277.2 KB)
العرض في تطبيقات مختلفة على iPhone أو iPad أو نظام تشغيل Android أو قارئ Sony أو نظام التشغيل Windows Phone
لغة خالية من التحيز
تسعى مجموعة الوثائق لهذا المنتج جاهدة لاستخدام لغة خالية من التحيز. لأغراض مجموعة الوثائق هذه، يتم تعريف "خالية من التحيز" على أنها لغة لا تعني التمييز على أساس العمر، والإعاقة، والجنس، والهوية العرقية، والهوية الإثنية، والتوجه الجنسي، والحالة الاجتماعية والاقتصادية، والتمييز متعدد الجوانب. قد تكون الاستثناءات موجودة في الوثائق بسبب اللغة التي يتم تشفيرها بشكل ثابت في واجهات المستخدم الخاصة ببرنامج المنتج، أو اللغة المستخدمة بناءً على وثائق RFP، أو اللغة التي يستخدمها منتج الجهة الخارجية المُشار إليه. تعرّف على المزيد حول كيفية استخدام Cisco للغة الشاملة.
حول هذه الترجمة
ترجمت Cisco هذا المستند باستخدام مجموعة من التقنيات الآلية والبشرية لتقديم محتوى دعم للمستخدمين في جميع أنحاء العالم بلغتهم الخاصة. يُرجى ملاحظة أن أفضل ترجمة آلية لن تكون دقيقة كما هو الحال مع الترجمة الاحترافية التي يقدمها مترجم محترف. تخلي Cisco Systems مسئوليتها عن دقة هذه الترجمات وتُوصي بالرجوع دائمًا إلى المستند الإنجليزي الأصلي (الرابط متوفر).
المحتويات
المقدمة
يوضح هذا المستند كيفية تأثر StarOS VNF، الذي يتم تشغيله على مدير البنية الأساسية الظاهرية (VIM) من Cisco عند تعطيل خدمة التخزين في CEPH، وما يمكن فعله لتخفيف التأثير. يتم شرحه بافتراض إستخدام Cisco VIM كبنية أساسية ولكن يمكن تطبيق النظرية نفسها على أي بيئة OpenStack.
المتطلبات الأساسية
المتطلبات
توصي Cisco بأن تكون لديك معرفة بالمواضيع التالية:
- Cisco StarOS
- برنامج Vim من Cisco
- OpenStack
- سيفه
المكونات المستخدمة
تستند المعلومات الواردة في هذا المستند إلى إصدارات البرامج والمكونات المادية التالية:
- نظام التشغيل StarOS: 21.16.c9
- Cisco VIM: 3.2.2 (OpenStack Queens)
تم إنشاء المعلومات الواردة في هذا المستند من الأجهزة الموجودة في بيئة معملية خاصة. بدأت جميع الأجهزة المُستخدمة في هذا المستند بتكوين ممسوح (افتراضي). إذا كانت شبكتك قيد التشغيل، فتأكد من فهمك للتأثير المحتمل لأي أمر.
المختصرات
| برنامج Vim من Cisco | مدير البنية الأساسية الظاهرية من Cisco |
| VNF | وظيفة الشبكة الظاهرية |
| سيفه أود | برنامج CEPH Object Storage Daemon |
| StarOS | نظام التشغيل لحل Cisco Mobile Packet Core |
CEPH في Cisco VIM
هذه الصورة هنا مأخوذة من دليل مسؤول VIM من Cisco. يستخدم VIM من Cisco خيار CEPH كنقطة خلفية للتخزين.
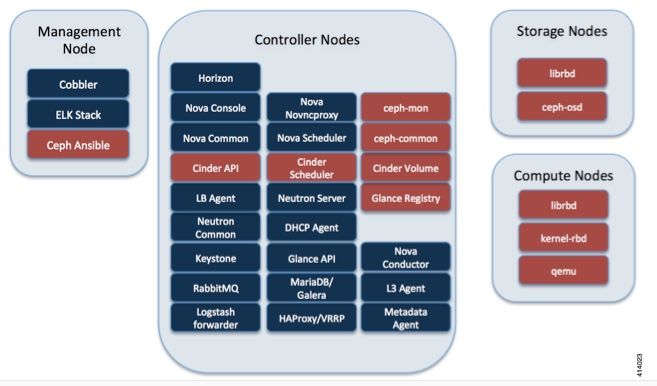
يدعم CEPH كلا من تخزين المجموعات والكائنات وبالتالي يتم إستخدامه لتخزين صور VM ووحدات التخزين التي يمكن إرفاقها بأجهزة VM. تتضمن خدمات OpenStack المتعددة التي تعتمد على خلفية وحدة التخزين ما يلي:
- نظرة سريعة (خدمة صورة OpenStack) — تستخدم تنسيق CEPH لتخزين الصور.
- Cinder (خدمة تخزين OpenStack) — يستخدم CEPH لإنشاء وحدات التخزين التي يمكن إرفاقها بالأجهزة الافتراضية.
- Nova (خدمة حوسبة OpenStack) — يستخدم CEPH للاتصال بالمجلدات التي تم إنشاؤها بواسطة Cinder.
في العديد من الحالات، يتم إنشاء وحدة تخزين في CEPH ل /flash و /hd-raid ل StarOS VNF مثل المثال التالي.
openstack volume create --image `glance image-list | grep up-image | awk '{print $2}'` --size 16 --type LUKS up1-flash-boot
openstack volume create --size 20 --type LUKS up1-hd-raid
المبادئ الأساسية لآلية الرصد في إتفاق الشراكة الاقتصادية في أوروبا
اليكم الشرح الوارد في وثيقة ترتيب بشأن المراقبة:
يقوم كل جهاز من الأجهزة الخادمة من نوع CEPH OSD بفحص دقات القلب الخاصة بالأجهزة الخادمة من نوع CEPH OSD الأخرى في فترات زمنية عشوائية تقل كل 6 ثوان. إذا لم يظهر جهاز "Ceph OSD Daemon" المجاور نبضات قلب خلال فترة سماح مدتها 20 ثانية، قد يأخذ الجهاز المساعد ل CEPH OSD في الاعتبار الجهاز المساعد المجاور CEPH OSD Daemon ويقوم بإبلاغه مرة أخرى إلى جهاز "CEPH" الذي يقوم بتحديث خريطة نظام المجموعة CEPH. بشكل افتراضي، يجب أن يبلغ إثنان من أعضاء برنامج OSD ل CEPH من مضيفين مختلفين مراقبي CEPH بأن أحد أعضاء برنامج OSD DAEMON آخر في CEPH موجود قبل أن يقر مراقبو CEPH بأن برنامج OSD DAEMON الذي تم الإبلاغ عنه قد تعطل.
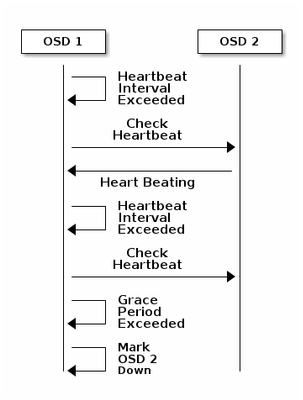
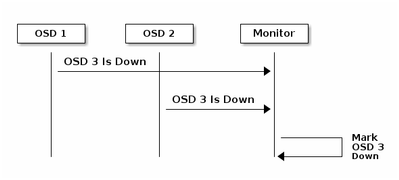
بشكل عام، يستغرق الأمر حوالي 20 ثانية للكشف عن العناصر التي تظهر على الشاشة (OSD) إلى الأسفل ويتم تحديث خريطة نظام المجموعة ل CEPH، فقط بعد أن يتمكن VNF من إستخدام جهاز OSD جديد. أثناء هذا القرص الزمني، يتم حظر الإدخال/الإخراج.
تأثير حظر الإدخال/الإخراج على StarOS VNF
إذا تم حظر إدخال/إخراج القرص لأكثر من 120 ثانية، تتم إعادة تمهيد StarOS VNF. هناك فحص محدد لعمليات xfssyncd/md0 و xfs_db المرتبطة بالإدخال/الإخراج بالقرص و StarOS التي يتم إعادة تشغيلها عن قصد عندما يكتشف وجود مشكلة في هذه العمليات تزيد عن 120 ثانية.
سجل وحدة تحكم تصحيح أخطاء StarOS:
[ 1080.859817] INFO: task xfssyncd/md0:25787 blocked for more than 120 seconds.
[ 1080.862844] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 1080.866184] xfssyncd/md0 D ffff880c036a8290 0 25787 2 0x00000000
[ 1080.869321] ffff880aacf87d30 0000000000000046 0000000100000a9a ffff880a00000000
[ 1080.872665] ffff880aacf87fd8 ffff880c036a8000 ffff880aacf87fd8 ffff880aacf87fd8
[ 1080.876100] ffff880c036a8298 ffff880aacf87fd8 ffff880c0f2f3980 ffff880c036a8000
[ 1080.879443] Call Trace:
[ 1080.880526] [<ffffffff8123d62e>] ? xfs_trans_commit_iclog+0x28e/0x380
[ 1080.883288] [<ffffffff810297c9>] ? default_spin_lock_flags+0x9/0x10
[ 1080.886050] [<ffffffff8157fd7d>] ? _raw_spin_lock_irqsave+0x4d/0x60
[ 1080.888748] [<ffffffff812301b3>] _xfs_log_force_lsn+0x173/0x2f0
[ 1080.891375] [<ffffffff8104bae0>] ? default_wake_function+0x0/0x20
[ 1080.894010] [<ffffffff8123dc15>] _xfs_trans_commit+0x2a5/0x2b0
[ 1080.896588] [<ffffffff8121ff64>] xfs_fs_log_dummy+0x64/0x90
[ 1080.899079] [<ffffffff81253cf1>] xfs_sync_worker+0x81/0x90
[ 1080.901446] [<ffffffff81252871>] xfssyncd+0x141/0x1e0
[ 1080.903670] [<ffffffff81252730>] ? xfssyncd+0x0/0x1e0
[ 1080.905871] [<ffffffff81071d5c>] kthread+0x8c/0xa0
[ 1080.908815] [<ffffffff81003364>] kernel_thread_helper+0x4/0x10
[ 1080.911343] [<ffffffff81580805>] ? restore_args+0x0/0x30
[ 1080.913668] [<ffffffff81071cd0>] ? kthread+0x0/0xa0
[ 1080.915808] [<ffffffff81003360>] ? kernel_thread_helper+0x0/0x10
[ 1080.918411] **** xfssyncd/md0 stuck, resetting card
ولكن لا يقتصر على المؤقت الذي تبلغ مدته 120 ثانية، ففي حالة حظر إدخال/إخراج القرص لفترة ما، حتى أقل من 120 ثوان، قد تتم إعادة تمهيد VNF لمجموعة متنوعة من الأسباب. الإخراج هنا هو مثال واحد يوضح عملية إعادة التشغيل بسبب حدوث مشكلة في إدخال/إخراج القرص، وفي بعض الأحيان عند تعطل مهمة StarOS بشكل مستمر، وما إلى ذلك. يعتمد ذلك على توقيت وحدات الإدخال/الإخراج بالأقراص النشطة مقارنة بمشكلة التخزين.
[ 2153.370758] Hangcheck: hangcheck value past margin!
[ 2153.396850] ata1.01: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen
[ 2153.396853] ata1.01: failed command: WRITE DMA EXT
--- skip ---
SYSLINUX 3.53 0x5d037742 EBIOS Copyright (C) 1994-2007 H. Peter Anvin
يمكن إعتبار عملية الإدخال/الإخراج التي يتم حظرها لفترة طويلة بشكل أساسي كمسألة حساسة للتردد اللاسلكي من خلال نظام التشغيل StarOS ويجب تقليل هذه المشكلة قدر الإمكان.
سيناريوهات حظر الإدخال/الإخراج لفترة طويلة
استنادا إلى البحث الذي تم إجراؤه من خلال عمليات النشر المتعددة للعملاء والاختبارات المعملية، يوجد سيناريوهان رئيسيان يمكن أن يتسببا في حدوث عملية إدخال/إخراج طويلة المدى لعملية الحظر في CEPH.
آلية توقيت لاغجي
توجد آلية نبضات قلب بين الأقراص المضغوطة للكشف عن وجود الأقراص المضغوطة لأسفل. استنادا إلى قيمة osd_heartbeat_grace(20 ثوان بشكل افتراضي)، يتم اكتشاف OSD على أنه فشل.
وهناك آلية مؤقت متأخرة، عندما يكون هناك تذبذب أو رفرفة في حالة OSD يتم ضبط ضبط مؤقت النعمة تلقائيا (يصبح أطول). قد يؤدي ذلك إلى زيادة قيمة OSD_HEARTBEAT_GRACE.
في الحالة العادية، النبضات تكون 20 ثانية
2019-01-09 16:58:01.715155 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 20.000047 >= grace 20.000000)
ولكن بعد تكرار نقاط الشبكة المتعددة لعقدة تخزين، تصبح القيمة أكبر.
2019-01-10 16:44:15.140433 mon.ceph-XXXXX [INF] osd.2 failed (root=default,host=XXXXX) (2 reporters from different host after 256.588099 >= grace 255.682576)
لذلك في المثال أعلاه، يستغرق الأمر 256 ثانية لاكتشاف الوسواس القهري كأسفل.
فشل أجهزة بطاقة RAID
قد لا يتمكن CEPH من اكتشاف فشل أجهزة بطاقة RAID في الوقت المناسب. ينتهي الأمر بفشل بطاقة RAID إلى حالة توقف محرك الأقراص الثابتة (OSD). في هذه الحالة، يتم اكتشاف وجود نظام التشغيل OSD لأسفل بعد دقائق قليلة وهو ما يكفي لإجراء عمليات إعادة تمهيد VNF من StarOS.
عند إيقاف تشغيل بطاقة RAID، تأخذ بعض مراكز وحدة المعالجة المركزية (CPU) نسبة 100٪ على الحالة WA.
%Cpu20 : 2.6 us, 7.9 sy, 0.0 ni, 0.0 id, 89.4 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu21 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu22 : 31.3 us, 5.1 sy, 0.0 ni, 63.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu23 : 0.0 us, 0.0 sy, 0.0 ni, 28.1 id, 71.9 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu24 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu25 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id,100.0 wa, 0.0 hi, 0.0 si, 0.0 st
كما أنها تتغذى على جميع مراكز وحدات المعالجة المركزية (CPU) بشكل تدريجي، كما أن الأجهزة المحمولة (OSD) تتناقص بشكل تدريجي مع وجود بعض الفواصل الزمنية.
2019-01-01 17:08:05.267629 mon.ceph-XXXXX [INF] Marking osd.2 out (has been down for 602 seconds)
2019-01-01 17:09:25.296955 mon.ceph-XXXXX [INF] Marking osd.4 out (has been down for 603 seconds)
2019-01-01 17:11:10.351131 mon.ceph-XXXXX [INF] Marking osd.7 out (has been down for 604 seconds)
2019-01-01 17:16:40.426927 mon.ceph-XXXXX [INF] Marking osd.10 out (has been down for 603 seconds)
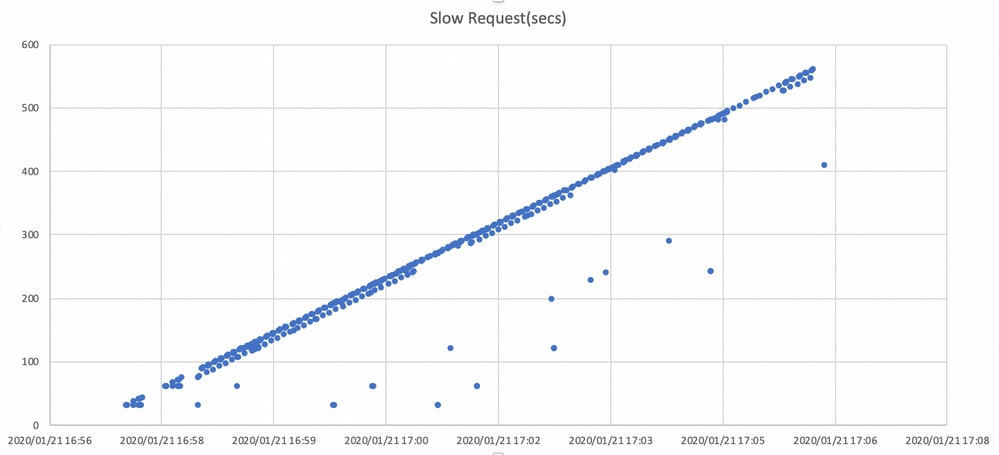
وفي موازاة ذلك، يتم الكشف عن طلبات بطيئة في ceph.log.
2019-01-01 16:57:26.743372 mon.XXXXX [WRN] Health check failed: 1 slow requests are blocked > 32 sec. Implicated osds 2 (REQUEST_SLOW)
2019-01-01 16:57:35.129229 mon.XXXXX [WRN] Health check update: 3 slow requests are blocked > 32 sec. Implicated osds 2,7,10 (REQUEST_SLOW)
2019-01-01 16:57:38.055976 osd.7 osd.7 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.216236 secs
2019-01-01 16:57:39.048591 osd.2 osd.2 [WRN] 1 slow requests, 1 included below; oldest blocked for > 30.635122 secs
-----skip-----
2019-01-01 17:06:22.124978 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 554.285311 secs
2019-01-01 17:06:25.114453 osd.4 osd.4 [WRN] 19 slow requests, 1 included below; oldest blocked for > 546.221508 secs
2019-01-01 17:06:26.125459 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 558.285789 secs
2019-01-01 17:06:27.125582 osd.7 osd.7 [WRN] 78 slow requests, 1 included below; oldest blocked for > 559.285915 secs
يوضح الرسم البياني هنا الفترة الزمنية التي يتم فيها حظر طلبات الإدخال/الإخراج مع وجود جدول زمني. يتم إنشاء الرسم البياني عن طريق تخطيط سجلات الطلبات البطيئة في ceph.log. فهو يظهر أن وقت الحظر يزداد مع مرور الوقت.
كيف يمكن تخفيف التأثير؟
نقل إلى القرص المحلي من تخزين CEPH
وأبسط طريقة لتخفيف التأثير هي الانتقال إلى قرص محلي من تخزين CEPH. يستخدم StarOS قرصين، /flash و /hd-raid، ومن الممكن نقل /flash فقط إلى القرص المحلي مما يجعل VNF من StarOS أكثر قوة لمعالجة مشكلات التهيئة. الجانب السلبي لاستخدام التخزين المشترك مثل CEPH، تتأثر كل VNF المستخدم له في نفس الوقت عند حدوث مشكلة. باستخدام قرص محلي، يمكن تقليل تأثير مشكلة التخزين إلى VNF التي تعمل على العقدة المتأثرة فقط. السيناريوهات المذكورة في القسم السابق تنطبق فقط على CEPH بحيث لا تنطبق على القرص المحلي. ولكن الجانب الآخر من القرص المحلي هو، لا يمكن الاحتفاظ بمحتوى القرص، مثل صورة StarOS والتكوين والملف الرئيسي وسجل الفوترة، عند إعادة نشر VM. وقد يؤثر ذلك على آلية الشفاء التلقائي الخاصة بعامل التطفل النوعي أيضا.
ضبط تكوين CEPH
من وجهة نظر StarOS VNF، يوصى بمعلمات CEPH الجديدة التالية لتقليل وقت الإدخال/الإخراج الذي تم حظره والمشار إليه أعلاه.
<الإعدادات الافتراضية>
"mon_osd_adjust_heartbeat_grace": "true",
"osd_client_watch_timeout": "30",
"osd_max_markdown_count": "5",
"osd_heartbeat_grace": "20",
<إعدادات جديدة>
"mon_osd_adjust_heartbeat_grace": "false",
"osd_client_watch_timeout": "10",
"osd_max_markdown_count": "1",
"osd_heartbeat_grace": "10",
ويتألف من:
- آلية المؤقت المتباطئ معطلة، لا يوجد تعديل تلقائي
- وقت النعمة ذو نبضات القلب قصير
- يتم وضع علامة "تنازلي" على OSD فورا (بشكل افتراضي 5 مرات في آخر 600 ثانية)
يتم إختبار المعلمات الجديدة في أحد المختبرات، ويتم تقليل وقت اكتشاف العناصر التي تظهر على الشاشة (OSD) لأسفل إلى أقل من 10 ثوان تقريبا، وكانت في الأصل حوالي 30 ثانية مع التكوين الافتراضي ل CEPH.
مشكلات أجهزة بطاقة RAID للمراقبة
بالنسبة لسيناريو الأجهزة عبر بطاقة RAID، قد يكون من الصعب اكتشاف ذلك في الوقت المناسب نظرا لطبيعة المشكلة، لأنه يخلق وضعا يعمل فيه محرك الأقراص الضوئية بشكل متقطع بينما يتم حظر الإدخال/الإخراج. لا يوجد حل واحد لهذه المشكلة، ولكن يوصى بمراقبة سجل أجهزة الخادم لفشل بطاقة RAID، أو لسجل الطلبات البطيء في CEPH.سجل ببعض البرامج النصية واتخاذ بعض الإجراءات مثل إجراء تخفيض OSD المتأثر بشكل استباقي.
confih_osd_reset_pcores tuning
ولا يتعلق هذا الأمر بالسيناريوهات المذكورة، ولكن إذا كانت هناك مشكلة في أداء برنامج CEPH بسبب التشغيل المكثف للإدخال/الإخراج، فإن زيادة قيمة CEPH_OSD_RESET_PCORES يمكن أن تجعل أداء برنامج CEPH للإدخال/الإخراج أفضل. بشكل افتراضي، يتم تكوين CEPH_OSD_RESET_PCORES على Cisco VIM ك 2 ويمكن زيادته.
تمت المساهمة بواسطة مهندسو Cisco
- Tomonobu Okadaمهندس TAC من Cisco
- Satoshi Kinoshitaمهندس TAC من Cisco
 التعليقات
التعليقاتاتصل بنا
- فتح حالة دعم

- (تتطلب عقد خدمة Cisco)