简介
本文档介绍即时消息和在线状态(IM&P)高可用性如何在企业IM&P环境中工作以及如何对其进行故障排除。
先决条件
要求
Cisco 建议您了解以下主题:
使用的组件
- Cisco Unified IM&P 10.0及更高版本
- Cisco Jabber客户端9.6及更高版本
本文档中的信息是根据特定实验环境中的组件创建的。本文档中使用的所有组件都以清除(默认)配置开头。如果您的网络处于活动状态,请确保您了解所有命令的潜在影响。
IM and Presence高可用性(HA)
IM and Presence Service Server在CUCM配置中以逻辑服务器组的形式提供高可用性或冗余。此配置将传递到IM and Presence,然后用于在IM and Presence Service或服务器出现故障时提供冗余。 发生HA事件时,最终用户的会话将从故障服务器移至备份。 当服务器恢复正常状态时,管理员会自动或手动将用户会话移回原位。
冗余组配置
冗余组是允许将服务器分配到IM and Presence子集群以及配置HA的逻辑服务器对。要访问配置的此部分,请在CUCM服务器网页上找到它。
System > Presence冗余组
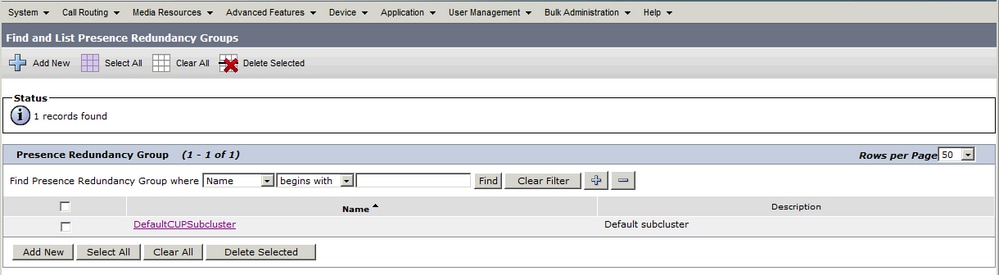
当管理员将IM&P发布服务器添加到CUCM上的System > Server配置并保存IM&P服务器时,会创建DefaultCUPSubCluster冗余组,且为其分配了发布服务器。
创建冗余组时,该冗余组如下所示:
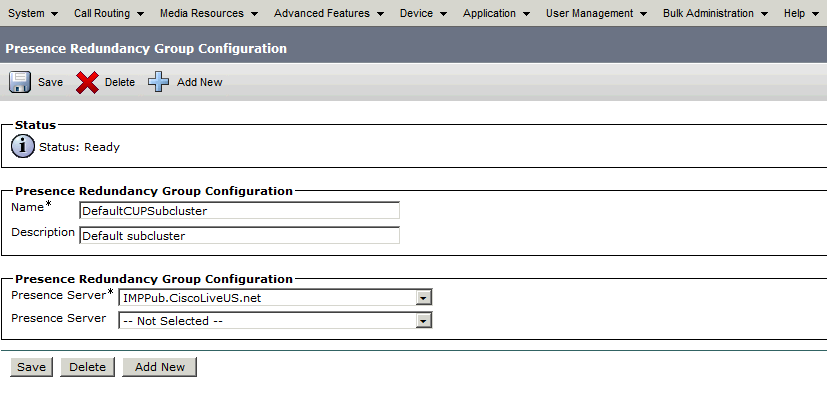
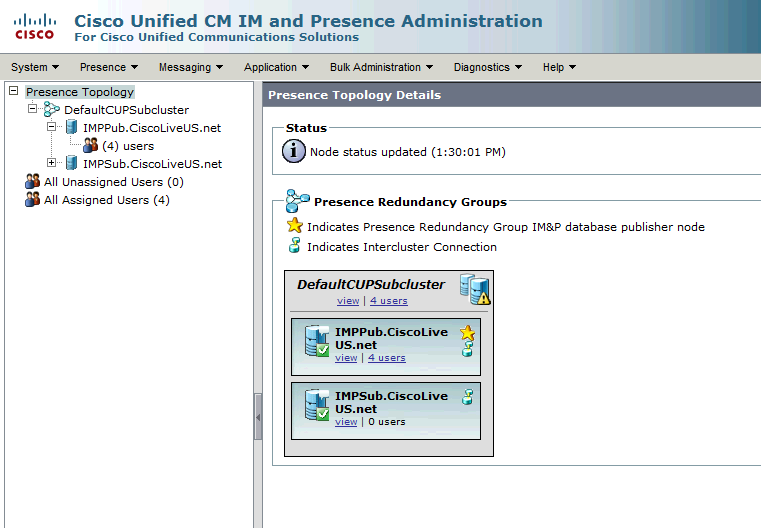
此冗余组转换为IM and Presence子集群。在CUCM中冗余组配置的当前状态下,这将是IM and Presence Cluster Topology网页中的状态:
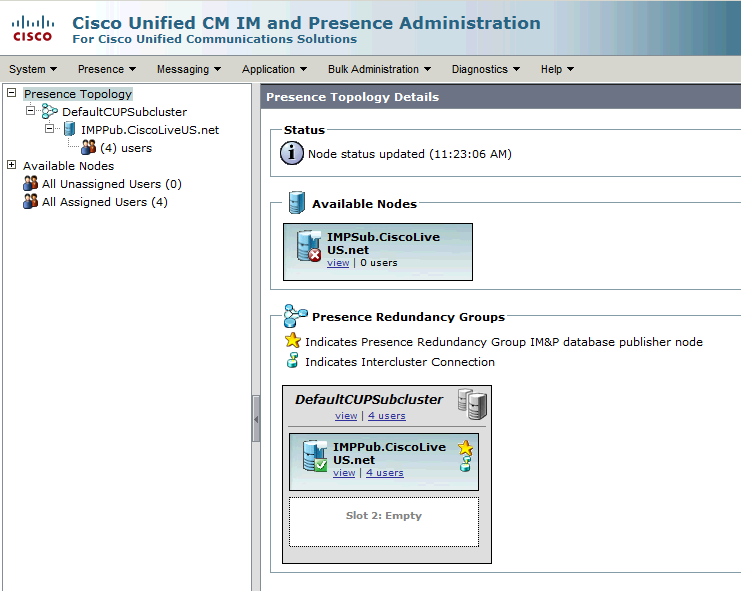
您会看到IM&P发布服务器已分配到DefaultCUPSubcluster,而订阅服务器未分配。 这是因为IM&P用户服务器未分配到CUCM配置中的冗余组。
将用户分配到冗余组。
要将订用服务器分配给冗余组,只需从下拉菜单中选择订用服务器,然后保存配置更改即可。
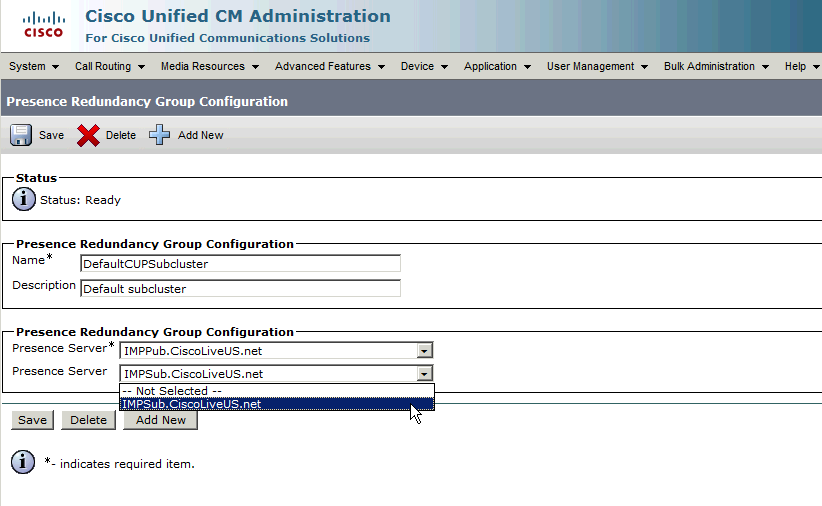
将IM&P用户添加到冗余组之后:
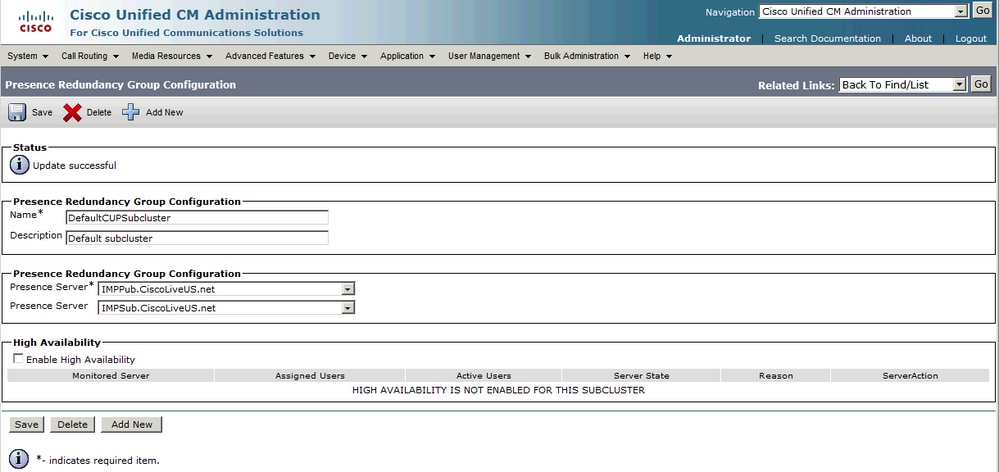
添加辅助节点(订用服务器)后,您会看到可以选择高可用性选项。要启用高可用性,您只需选中启用高可用性复选框并保存配置更改。
启用高可用性后:
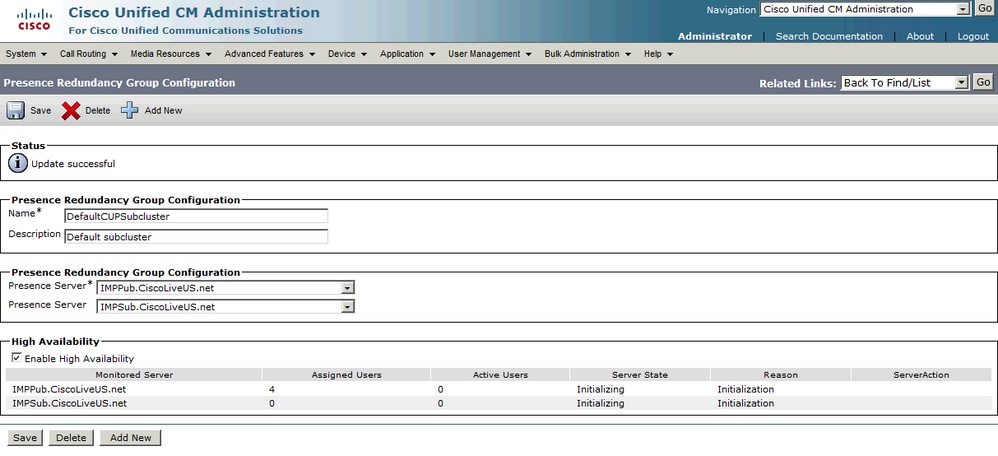
然后,页面自动刷新服务器状态和原因。 当服务器处于初始化状态时,这意味着两台服务器能够通信。 然后,服务器将在该状态转换为Normal状态之前验证服务状态。 如果两台服务器可以相互连接,并且两台服务器上所有受监控的服务都处于启用状态,则您将获得正常 — 正常状态。这意味着所有受监控的服务在IM&P服务器上都处于活动状态。
正常 — 正常冗余组状态:
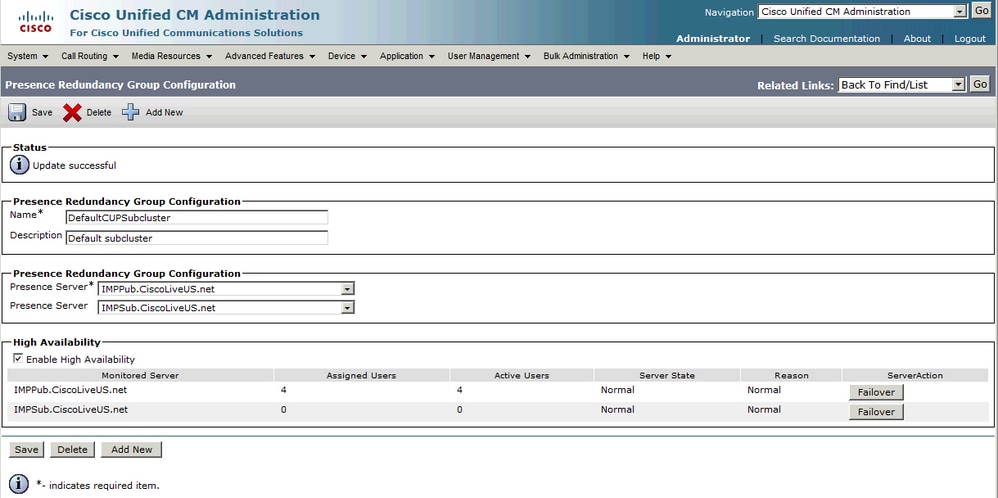
IM&P拓扑页面中的正常 — 正常高可用性状态:
受监控的即时消息和在线状态服务
因为您可能有多种部署模式:仅IM、具有SIP/XMPP联合的IM、具有合规性的IM、具有持续聊天的IM、仅远程呼叫控制等,所以要监控的这些进程的实际列表是动态的。默认情况下,在启用HA时,始终监控这些项目:
- IDS数据库
- Presence引擎(如果激活)
- XCP路由器
服务器恢复管理器检查以确定是否配置和激活了合规性(消息存档程序)、持续聊天(文本会议管理器)、SIP联合(SIP联合连接管理器)、XMPP联合(XMPP联合连接管理器)。
如果它们都已配置并激活,则服务器恢复管理器(SRM)也会监控这些服务。
注意:在继续重新启动一个或多个受监控服务之前,您需要从CUCM服务器上的在线状态冗余组禁用高可用性。当执行一个或多个IM&P节点的重新启动时,同样适用。
用户故障切换过程
发生故障转移时(自动或手动),需要记住的主要问题是用户帐户不会从一台服务器移动到另一台服务器,而只会移动在线状态引擎中的用户会话。在IM and Presence的10个之前版本中,用户分配从一个服务器移动到另一个服务器。 此用户移动对于服务器资源而言非常昂贵,而且会增加服务器上的负载。 在10.X及更高版本中,用户驻留在分配给他们的服务器上,并且在线状态引擎中的后端用户会话从故障节点移至功能节点。 当服务器恢复管理器(SRM)发生更改时,用户不必退出Jabber并重新登录。
Jabber客户端重新登录计时器
为了在故障切换事件后辅助IM&P节点上的用户会话完全激活,用户必须尝试通过SOAP(客户端配置文件代理)登录到该服务器。从IMDB数据库传递的一次性密码会自动发生这种情况。由于登录对IM and Presence服务器上的资源而言极其昂贵,因此必须有一种方法在发生故障转移事件时限制登录。 此限制或缓冲区允许所有用户登录到辅助节点,而不会中断辅助节点上用户的服务。 用于限制用户登录的机制包括客户端重新登录下限和客户端重新登录上限服务器恢复管理器(SRM)服务参数。
Client Re-Login Lower Limit — 用于定义Jabber客户端在发生HA事件时尝试登录到辅助服务器之前等待的最小时间量(以秒为单位)的参数。
Client Re-Login Upper Limit — 用于定义Jabber客户端在发生HA事件时尝试登录到辅助服务器之前等待的最长时间(以秒为单位)的参数。
Jabber客户端在登录到服务器时接收这些参数,并缓存这些值以供将来使用。 当您从IM&P服务器收到HA事件时,客户端选择上限与下限之间的随机秒数,并等待Jabber客户端尝试登录辅助设备之前的时间量。 计时器到期后,客户端会尝试通过SOAP登录到辅助节点。
IM and Presence回退类型
如果存在用户故障切换,则在有问题的服务器上恢复服务时,必须存在用户回退。 有两种类型的服务器回退:
手动回退
当服务已恢复且冗余组允许回退按钮时,发生手动回退(服务器恢复管理器的默认配置)。选中此按钮后,移至辅助节点的用户会话将移回其宿主节点。 然后,Jabber客户端将重新登录回退的上限和下限。
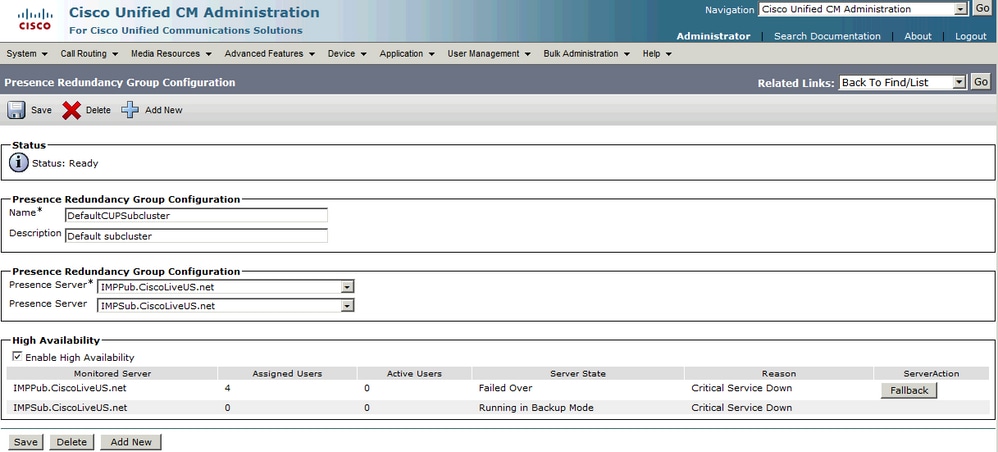
自动回退
自动回退发生在服务器监控服务和服务器恢复管理器(SRM)服务自动将用户回退到其宿主节点时。此配置中的关键是,服务器恢复管理器(SRM)服务等待30分钟,以便失败的服务/服务器在启动自动回退之前保持活动状态。 一旦建立了这30分钟的正常运行时间,用户会话将移回其托管节点。然后,Jabber客户端将重新登录回退的上限和下限。

注意:自动回退不是默认配置,但可以启用。 要启用自动回退,请将Server Recovery Manager Service Parameters中的Enable Automatic Fallback参数更改为值True。
故障排除
本节提供可用于对配置进行故障排除的信息。
对IM&P服务服务器上的高可用性进行故障排除时,您必须考虑两个重要的计时器。
- 服务器每60秒交换4个keepalive。如果60秒后没有响应,Cisco Service Recovery Manager(SRM)会认为无响应的节点已离线并触发“故障转移”命令。如下一段代码片断所示,最后一次心跳发生在62秒前。
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
提示:对于此场景,如果您发现网络中存在一些延迟,建议将心跳超时计时器从60秒增加到90秒。
导航到CUCM Administration web page > System > Service parameters configuration > Select the IM&P Server > Select Cisco Recovery ManagerSettings。在Keep Alive(Heartbeat)超时时,将数字增加到90秒。
- IM&P用户服务器等待90秒。如果检测到一个或多个监控服务发生故障,则用户服务器将接管。
收集用于故障排除的日志
- Server Recover Manager(SRM)在故障切换事件之前和之后记录日志(如果可能,为调试级别)。
- 通过IM&P命令行界面从企业子集群运行sql select *命令的输出结果。
- IM&P中的enterprisesubcluster表包含冗余组配置。
- 通过IM&P命令行界面从enterprisenode运行sql select *命令输出。
- enterprisenode表显示节点的节点信息和子群集分配。
- 如果故障切换是由被停止的服务生成的,请收集:
- 事件查看器系统日志
- 事件查看器应用程序日志
- 来自已停止服务的日志。
 反馈
反馈