소개
이 문서에서는 IM&P(Instant Message and Presence) 고가용성이 엔터프라이즈 IM&P 환경에서 작동하는 방식과 이 문제를 해결하는 방법에 대해 설명합니다.
사전 요구 사항
요구 사항
다음 주제에 대한 지식을 보유하고 있으면 유용합니다.
- Cisco Unified IM&P
- Cisco Jabber 클라이언트
사용되는 구성 요소
- Cisco Unified IM&P 10.0 이상
- Cisco Jabber 클라이언트 9.6 이상
이 문서의 정보는 특정 랩 환경의 구성 요소를 통해 작성되었습니다. 이 문서에 사용된 모든 구성 요소는 지워진(기본) 구성으로 시작되었습니다. 현재 네트워크가 작동 중인 경우 모든 명령의 잠재적인 영향을 미리 숙지하시기 바랍니다.
IM and Presence 고가용성(HA)
IM and Presence Service Server는 CUCM 컨피그레이션의 논리적 서버 그룹 형태로 고가용성 또는 이중화를 제공합니다. 이 컨피그레이션은 IM and Presence에 전달된 다음 IM and Presence 서비스 또는 서버 장애 시 이중화를 허용하는 데 사용됩니다. HA 이벤트가 발생하면 최종 사용자의 세션이 실패한 서버에서 백업으로 이동합니다. 서버가 정상 상태로 복원되면 사용자 세션은 관리자가 자동으로 또는 수동으로 다시 이동합니다.
이중화 그룹 컨피그레이션
이중화 그룹은 IM and Presence 하위 클러스터에 서버를 할당하고 HA에 대한 구성을 허용하는 논리 서버 쌍입니다. 이 구성 부분에 액세스하려면 CUCM 서버 웹 페이지에서 해당 구성을 찾으십시오.
System(시스템) > Presence Redundancy Groups(프레즌스 리던던시 그룹)
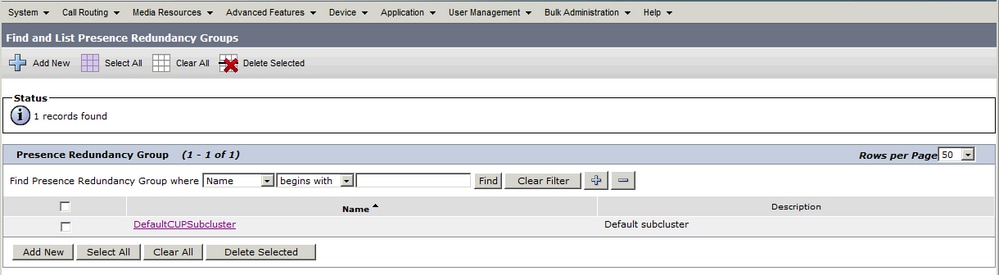
관리자가 CUCM의 System > Server 컨피그레이션에 IM&P 게시자를 추가하고 IM&P 서버가 저장되면 DefaultCUPSubCluster 이중화 그룹이 할당된 게시자로 생성됩니다.
이중화 그룹이 생성되면 다음과 같이 표시됩니다.
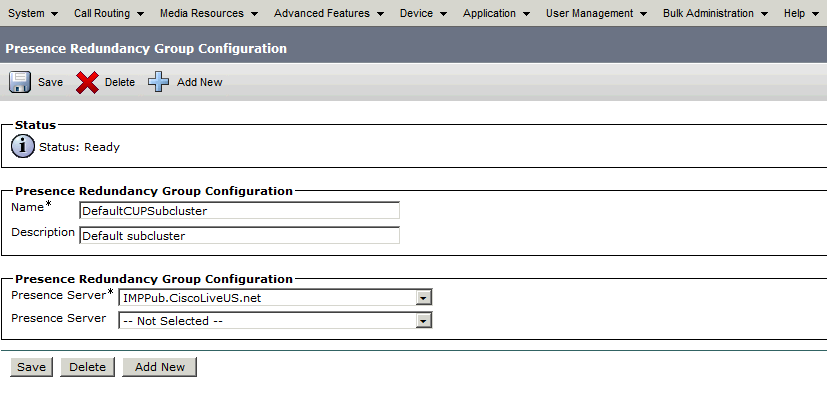
이 이중화 그룹은 IM and Presence 하위 클러스터로 변환됩니다. CUCM의 이중화 그룹 컨피그레이션의 현재 상태에서는 IM and Presence Cluster Topology(IM and Presence 클러스터 토폴로지) 웹 페이지에 표시되는 것과 같습니다.
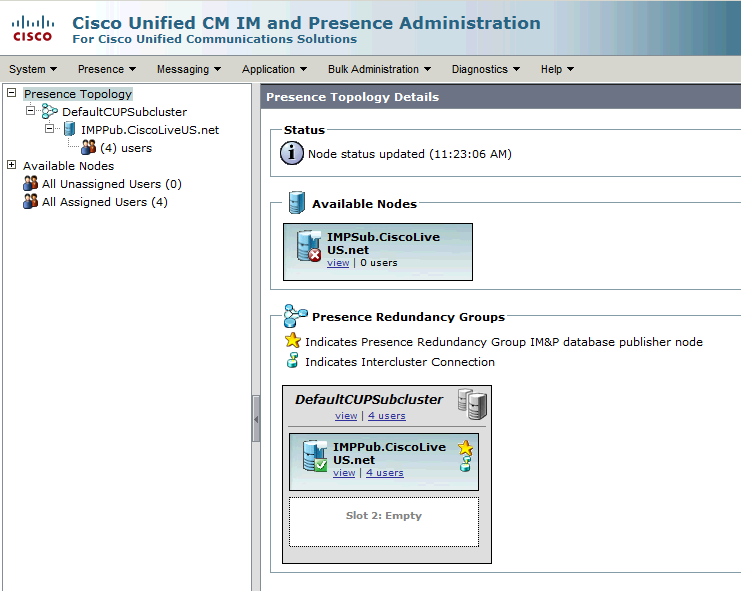
IM&P 게시자가 DefaultCUPSubcluster에 할당되어 있고 가입자 서버가 이(가) 아닌 것을 확인할 수 있습니다. 이는 IM&P 가입자 서버가 CUCM 컨피그레이션의 이중화 그룹에 할당되지 않기 때문입니다.
이중화 그룹에 가입자를 할당합니다.
이중화 그룹에 가입자 서버를 할당하려면 드롭다운 메뉴에서 가입자 서버를 선택한 다음 컨피그레이션 변경 사항을 저장하면 됩니다.
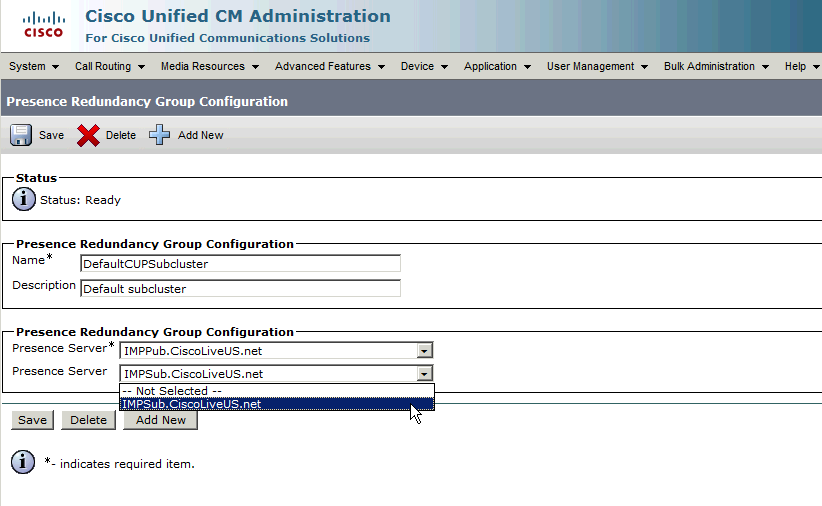
IM&P 가입자를 이중화 그룹에 추가한 후 다음을 수행합니다.
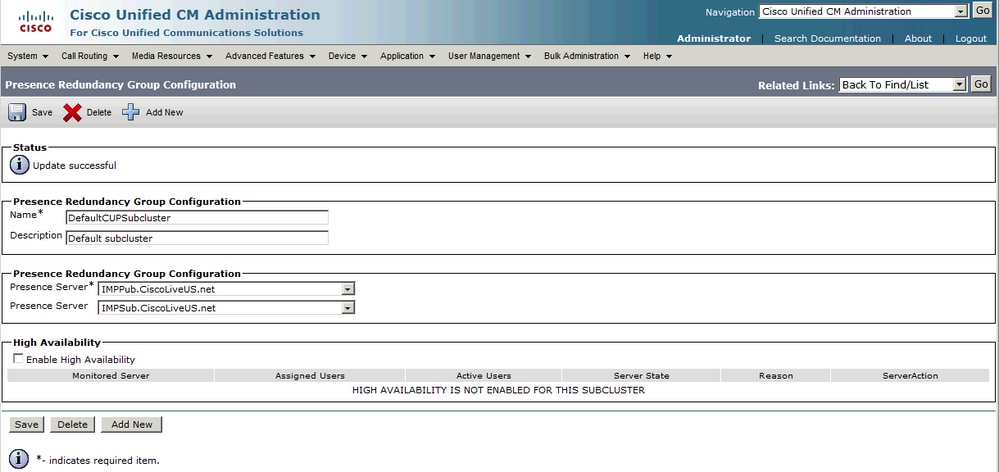
보조 노드(가입자)를 추가한 후에는 High Availability(고가용성) 옵션을 선택할 수 있음을 확인할 수 있습니다. 고가용성을 활성화하려면 Enable High Availability(고가용성 활성화) 확인란을 선택하고 컨피그레이션 변경 사항을 저장하기만 하면 됩니다.
고가용성이 활성화된 후:
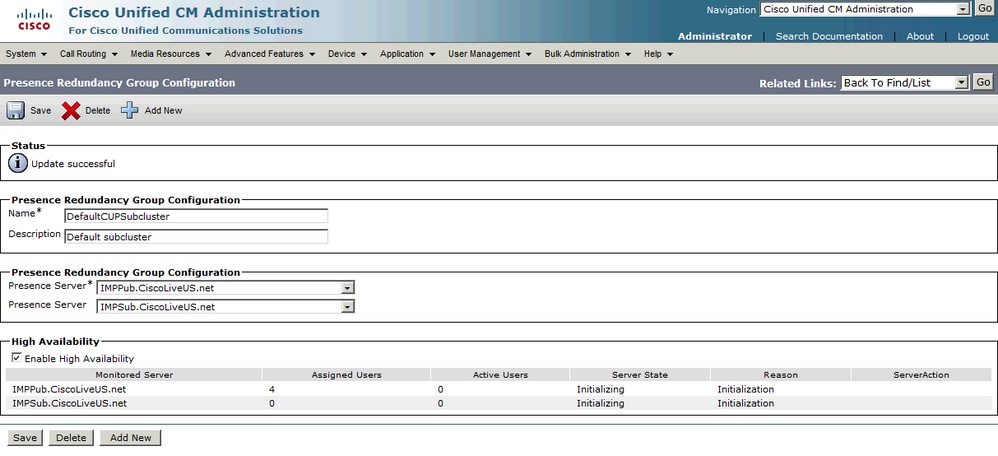
그러면 페이지가 서버 상태 및 이유를 자동으로 새로 고칩니다. 서버가 초기화 상태일 때 두 서버가 통신할 수 있음을 의미합니다. 그런 다음 서버는 상태가 Normal(정상) 상태로 전환되기 전에 서비스 상태를 확인합니다. 두 서버가 서로 연결할 수 있고 모든 모니터링되는 서비스가 둘 다에서 가동 중이면 정상-정상 상태가 됩니다. 즉, 모니터링되는 모든 서비스가 IM&P 서버에서 활성 상태입니다.
일반-일반 이중화 그룹 상태:
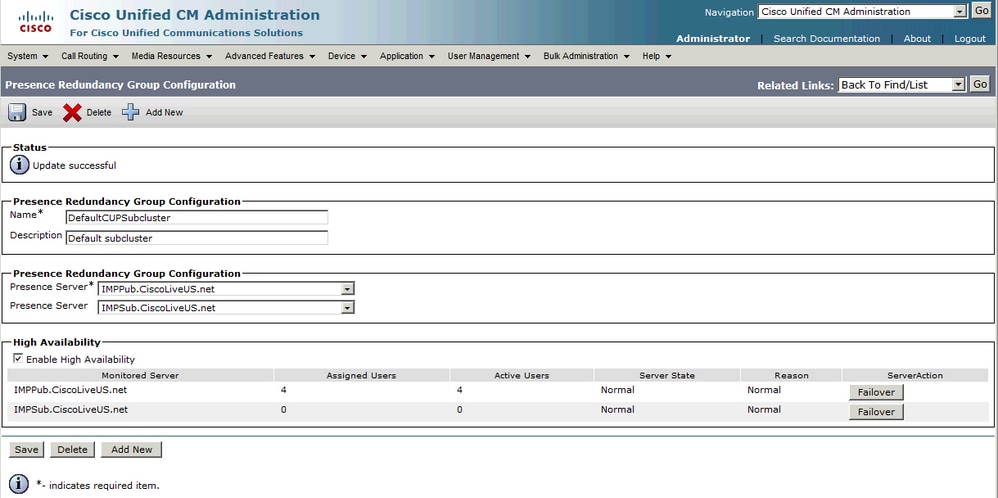
IM&P 토폴로지 페이지의 일반-일반 고가용성 상태:
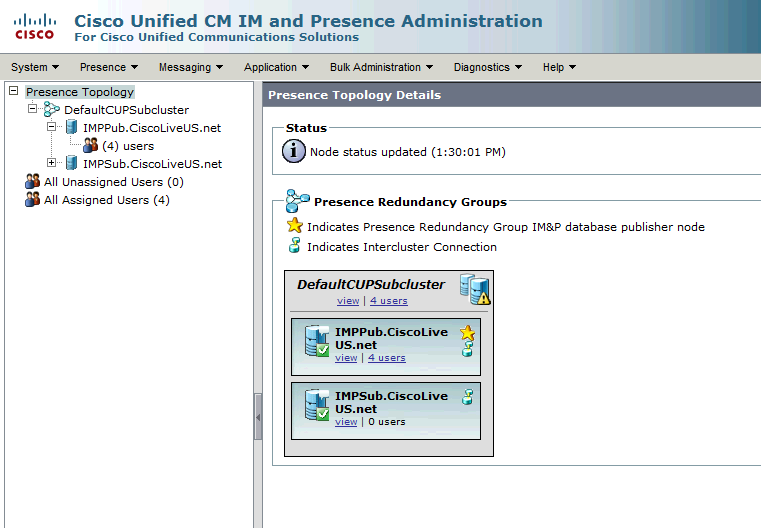
모니터링되는 IM and Presence 서비스
IM Only, IM with SIP/XMPP Federation, IM with Compliance, IM with persistent chat, IM with Remote Call Control Only 등 다양한 구축 모델이 있을 수 있으므로 모니터링할 프로세스의 실제 목록은 동적입니다. 기본적으로 이러한 항목은 HA가 활성화된 경우 항상 모니터링됩니다.
- IDS 데이터베이스
- 프레즌스 엔진(활성화된 경우)
- XCP 라우터
서버 복구 관리자는 규정 준수(메시지 아카이버), 영구 채팅(Text Conference Manager), SIP 페더레이션(SIP Federation Connection Manager), XMPP 페더레이션(XMPP Federation Connection Manager)이 구성 및 활성화되었는지 확인합니다.
구성 및 활성화된 서비스는 SRM(Server Recovery Manager)에서도 모니터링합니다.
주의: 하나 이상의 모니터링되는 서비스를 재시작하기 전에 CUCM 서버의 프레즌스 이중화 그룹에서 고가용성을 비활성화해야 합니다. 하나 이상의 IM&P 노드를 재부팅하는 경우에도 마찬가지입니다.
사용자 페일오버 프로세스
장애 조치가 발생하면(자동 또는 수동) 사용자 계정이 한 서버에서 다른 서버로 이동되지 않고 프레즌스 엔진의 사용자 세션만 이동된다는 점을 기억해야 합니다. 10개 이전 버전의 IM and Presence에서는 사용자 할당이 한 서버에서 다른 서버로 이동되었습니다. 이러한 사용자 이동은 서버 리소스에 매우 많은 비용이 소요되었으며 서버에 있는 로드에 추가되었습니다. 10.X 이상에서는 사용자가 할당된 서버에 계속 머무르며, Presence Engine의 백엔드 사용자 세션이 실패한 노드에서 기능 노드로 이동됩니다. 변경 사항이 SRM(Server Recovery Manager)에서 발생할 때 사용자가 Jabber를 종료하고 다시 로그인하지 않아도 됩니다.
Jabber 클라이언트 재로그인 타이머
장애 조치 이벤트 후 사용자 세션이 보조 IM&P 노드에서 완전히 활성화되도록 하려면 사용자는 SOAP(Client Profile Agent)를 통해 해당 서버에 로그인을 시도해야 합니다. 이는 IMDB 데이터베이스에서 전달되는 일회용 비밀번호와 함께 자동으로 발생합니다. 로그인은 IM and Presence 서버의 리소스에 비해 비용이 많이 들기 때문에 장애 조치 이벤트가 발생할 때 로그인을 제한하는 방법이 있어야 합니다. 이 스로틀 또는 버퍼는 모든 사용자가 보조 노드의 사용자에 대한 서비스 중단 없이 보조 노드에 로그인할 수 있게 합니다. 사용자 로그인을 제한하는 데 사용되는 메커니즘은 Client Re-Login Lower Limit(클라이언트 재로그인 하한) 및 Client Re-Login Upper Limit Server Recovery Manager(SRM) 서비스 매개변수입니다.
Client Re-Login Lower Limit(클라이언트 재로그인 하한) - HA 이벤트 발생 시 클라이언트가 보조 서버에 로그인을 시도하기 전에 Jabber 클라이언트가 대기하는 최소 시간(초)을 정의하는 매개변수.
Client Re-Login Upper Limit(클라이언트 재로그인 상한) - HA 이벤트 발생 시 클라이언트가 보조 서버에 로그인을 시도하기 전에 Jabber 클라이언트가 대기하는 최대 시간(초)을 정의하는 매개변수.
Jabber 클라이언트는 서버에 로그인할 때 이러한 매개변수를 수신하고 나중에 사용할 수 있도록 값을 캐시합니다. IM&P 서버에서 HA 이벤트를 수신하면 클라이언트는 상한값과 하한값 사이의 임의의 시간(초)을 선택하고 Jabber 클라이언트가 보조 서버에 로그인을 시도하기 전에 해당 시간을 대기합니다. 타이머가 만료되면 클라이언트는 보조 노드에 SOAP 로그인을 시도합니다.
IM 및 프레즌스 폴백 유형
사용자 페일오버가 있는 경우 문제가 있는 서버에서 서비스를 복원할 때 사용자 폴백이 있어야 합니다. 서버 폴백에는 두 가지 유형이 있습니다.
수동 폴백
서비스가 복원되고 이중화 그룹에서 [대체] 단추를 허용하는 경우 수동 대체(서버 복구 관리자의 기본 컨피그레이션)가 수행됩니다. 이 버튼을 선택하면 보조 노드로 이동된 사용자 세션이 홈 노드로 다시 이동됩니다. 그런 다음 Jabber 클라이언트가 대안에 대한 상한값과 하한값에 재로그인을 적용합니다.
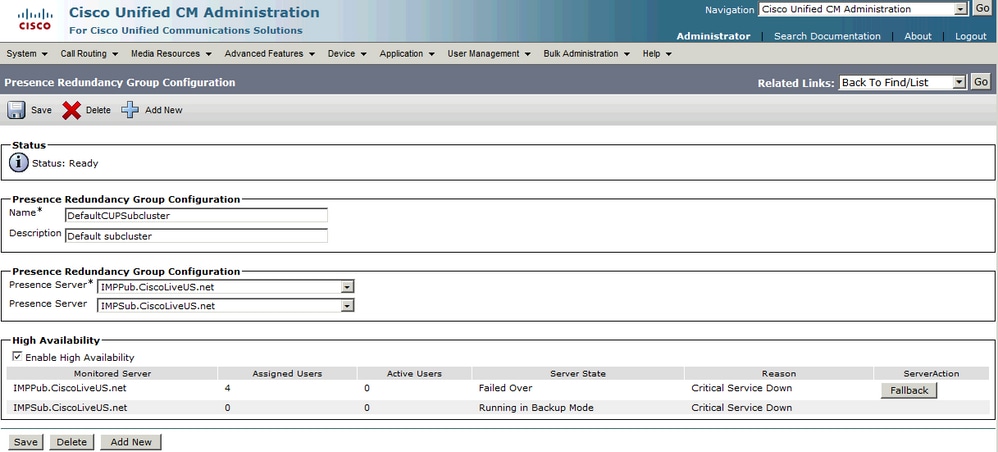
자동 폴백
서버가 서비스를 모니터링하고 SRM(Server Recovery Manager) 서비스가 자동으로 사용자를 홈 노드로 대체하면 자동 대체(fallback)가 수행됩니다. 이 컨피그레이션의 핵심은 자동 폴백이 시작되기 전에 SRM(Server Recovery Manager) 서비스가 실패한 서비스/서버가 활성 상태를 유지할 때까지 30분 동안 대기한다는 것입니다. 이 30분 업타임이 설정되면 사용자 세션이 홈 노드로 다시 이동됩니다. 그런 다음 Jabber 클라이언트가 대안에 대한 상한값과 하한값에 재로그인을 적용합니다.

참고: 자동 대체는 기본 컨피그레이션이 아니지만 활성화할 수 있습니다. 자동 대체를 활성화하려면 서버 복구 관리자 서비스 매개변수의 자동 대체 활성화 매개변수를 True 값으로 변경합니다.
문제 해결
이 섹션에서는 컨피그레이션 문제를 해결하는 데 사용할 수 있는 정보를 제공합니다.
IM&P Service Server에서 고가용성을 트러블슈팅할 때 고려해야 할 두 가지 중요한 타이머가 있습니다.
- 서버는 60초마다 4개의 keepalive를 교환합니다. 60초 후에 응답이 없으면 Cisco SRM(Service Recovery Manager)은 응답하지 않는 노드가 오프라인으로 전환된 것으로 간주하고 장애 조치 명령을 트리거합니다. 다음 스니펫에서 볼 수 있듯이, 마지막 하트비트는 62초 전에 발생했습니다.
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
팁: 이 시나리오에서는 네트워크에서 약간의 레이턴시를 발견한 경우 하트비트 시간 초과 타이머를 60초에서 90초로 늘리는 것이 좋습니다.
CUCM Administration(CUCM 관리) 웹 페이지 > System(시스템) > Service parameters configuration(서비스 매개변수 컨피그레이션) > Select the IM&P Server(IM&P 서버 선택) > Select Cisco Recovery Manager(Cisco 복구 관리자)Settings(설정 선택)로 이동합니다. Keep Alive (Heartbeat) 시간 초과에서 이 수를 90초로 늘립니다.
- IM&P 가입자 서버는 90초 동안 기다립니다. 모니터링되는 서비스 중 하나 이상이 다운된 것을 탐지하면 가입자 서버가 이를 인계합니다.
문제 해결을 위해 수집할 로그
- SRM(서버 복구 관리자)은 장애 조치 이벤트 전후의 로그를 기록합니다(가능한 경우 디버그 레벨).
- IM&P 명령줄 인터페이스를 통한 명령 출력은 enterprisesubcluster에서 sql select*를 실행합니다.
- IM&P의 enterprisesubcluster 테이블에는 이중화 그룹 컨피그레이션이 포함되어 있습니다.
- IM&P 명령줄 인터페이스를 통한 명령 출력은 enterprisenode에서 sql select *를 실행합니다.
- enterprisennode 테이블에는 노드의 노드 정보 및 하위 클러스터 할당이 표시됩니다.
- 장애 조치(failover)가 중지되는 서비스에 의해 생성된 경우 다음을 수집합니다.
- 이벤트 뷰어 시스템 로그
- 이벤트 뷰어 애플리케이션 로그
- 중지된 서비스의 로그
 피드백
피드백