はじめに
このドキュメントでは、企業のIM&P環境でインスタントメッセージとプレゼンス(IM&P)のハイアベイラビリティがどのように機能するか、およびそのトラブルシューティング方法について説明します。
前提条件
要件
次の項目に関する知識があることが推奨されます。
- シスコユニファイドIM&P
- Cisco Jabber クライアント
使用するコンポーネント
- Cisco Unified IM&P 10.0以降
- Cisco Jabberクライアント9.6以降
このドキュメントの情報は、特定のラボ環境にあるコンポーネントに基づいて作成されました。このドキュメントで使用するすべてのコンポーネントは、クリア(デフォルト)な設定で作業を開始しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
IM and Presenceハイアベイラビリティ(HA)
IM and Presenceサービスサーバは、CUCM設定で論理サーバグループの形式で高可用性または冗長性を提供します。この設定はIM and Presenceに渡され、IM and Presenceサービスまたはサーバの障害時に冗長性を確保するために使用されます。 HAイベントが発生すると、エンドユーザのセッションが障害が発生したサーバからバックアップに移動されます。 サーバが正常な状態に復元されると、管理者はユーザセッションを自動または手動で元に戻します。
冗長グループの設定
冗長性グループは、IM and Presenceサブクラスタへのサーバの割り当て、およびHAの設定を可能にする論理サーバペアです。設定のこの部分にアクセスするには、CUCMサーバのWebページで検索します。
[システム] > [プレゼンス冗長グループ]
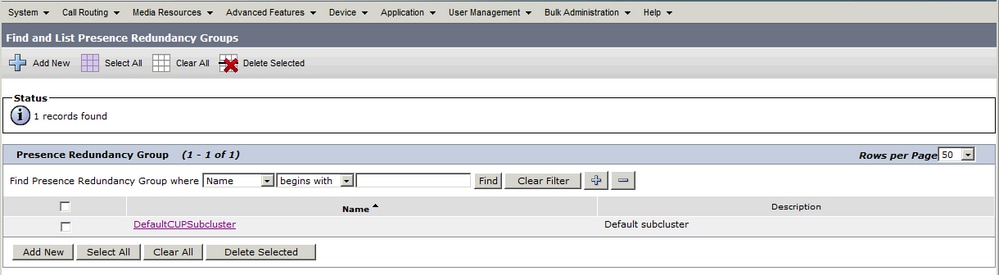
管理者がCUCMのSystem > Server設定にIM&Pパブリッシャを追加し、IM&Pサーバが保存されると、パブリッシャが割り当てられたDefaultCUPSubCluster冗長グループが作成されます。
冗長グループを作成すると、次のようになります。
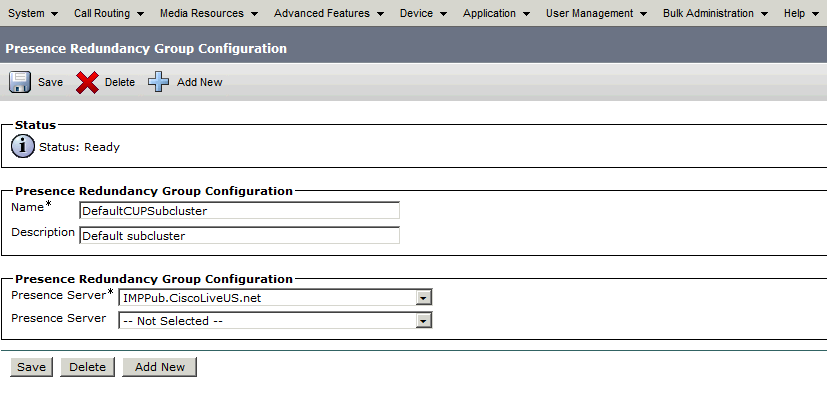
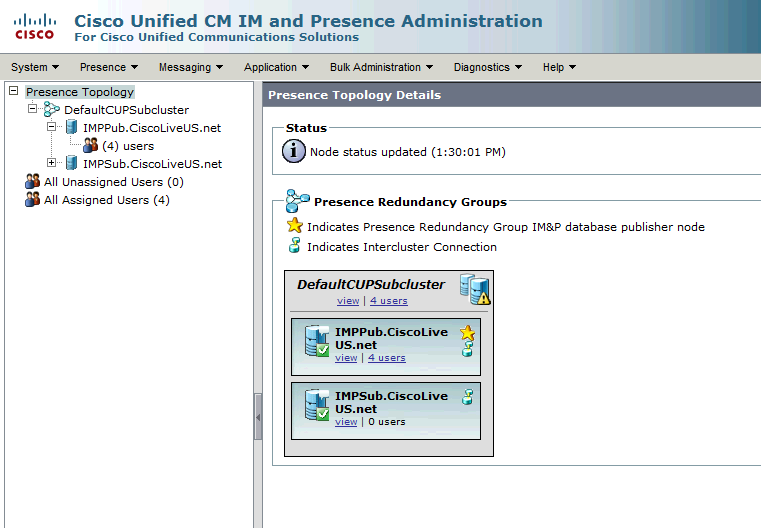
この冗長グループはIM and Presenceサブクラスタに変換されます。CUCMの冗長グループ設定の現在の状態では、IM and PresenceクラスタトポロジWebページで次のように表示されます。
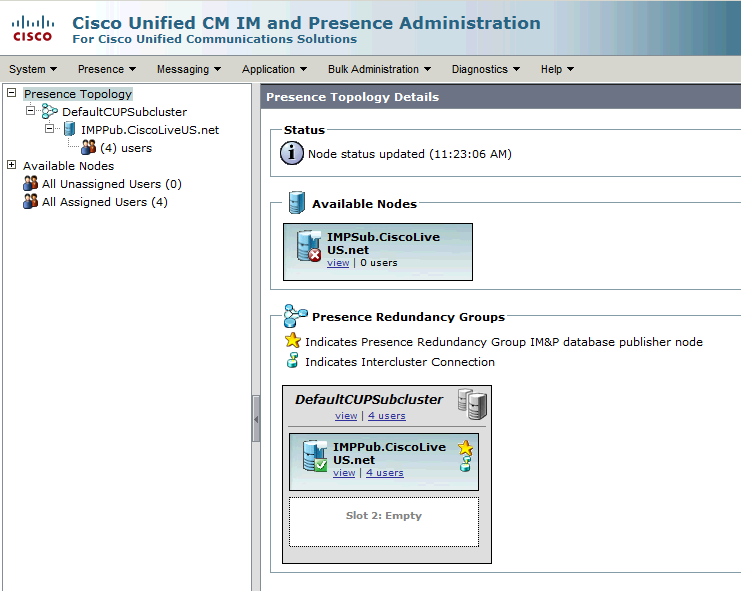
IM&PパブリッシャがDefaultCUPSubclusterに割り当てられ、サブスクライバサーバが割り当てられていないことがわかります。 これは、IM&PサブスクライバサーバがCUCM設定の冗長グループに割り当てられていないためです。
サブスクライバを冗長グループに割り当てます。
サブスクライバサーバを冗長グループに割り当てるには、ドロップダウンメニューからサブスクライバサーバを選択し、設定変更をSaveします。
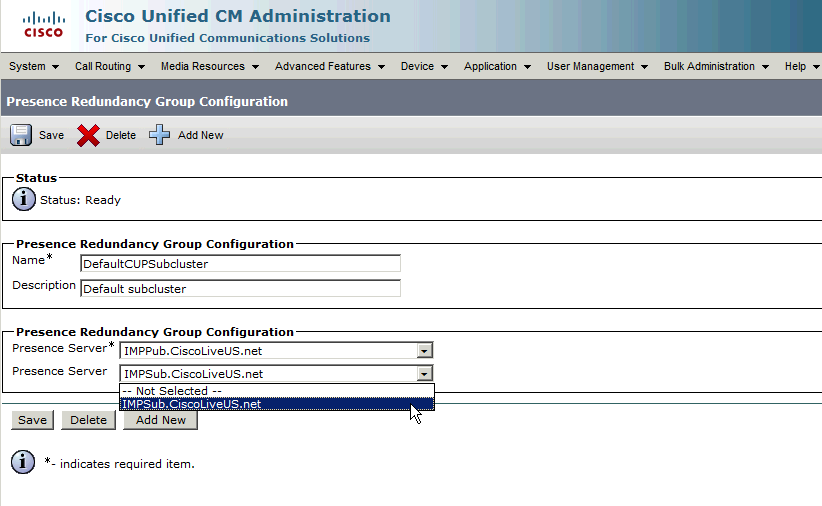
IM&Pサブスクライバが冗長グループに追加された後:
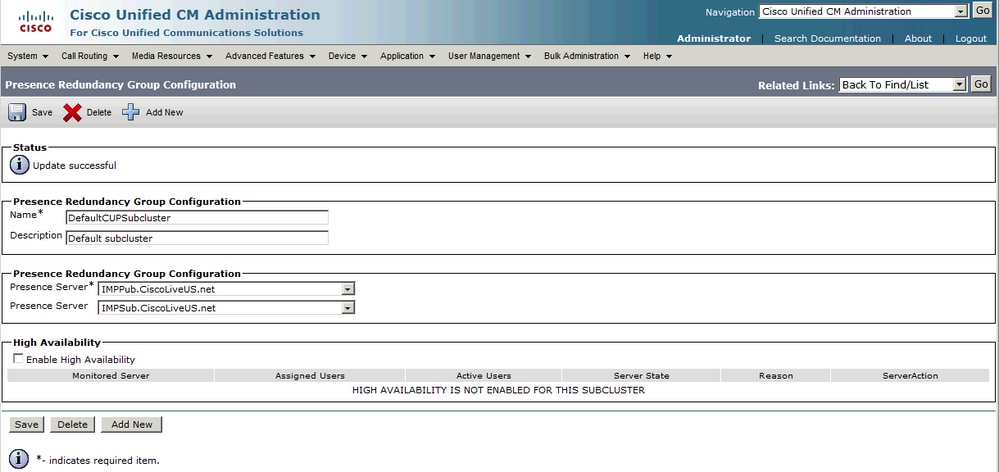
セカンダリノード(サブスクライバ)を追加すると、ハイアベイラビリティオプションを選択できることがわかります。ハイアベイラビリティを有効にするには、ハイアベイラビリティを有効にするチェックボックスを選択し、設定変更を保存するだけです。
ハイアベイラビリティを有効にした後:
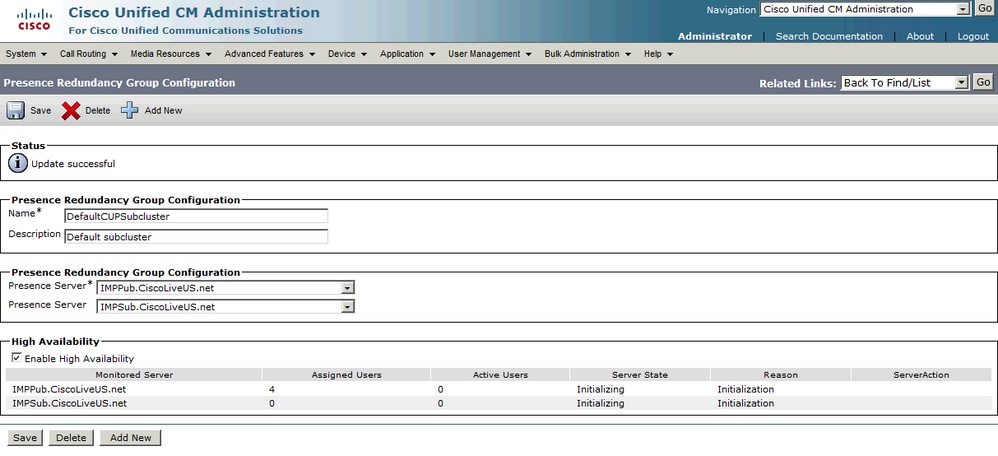
その後、ページでサーバの状態と理由が自動的に更新されます。 サーバが初期化状態にある場合、これは2台のサーバが通信できることを意味します。 その後、サーバは状態がNormal状態に移行する前にサービス状態を確認します。 2台のサーバが相互に接続でき、すべての監視対象サービスが両方で起動している場合は、Normal-Normal状態になります。つまり、モニタ対象のすべてのサービスがIM&Pサーバ上でアクティブになります。
通常 – 通常の冗長性グループの状態:
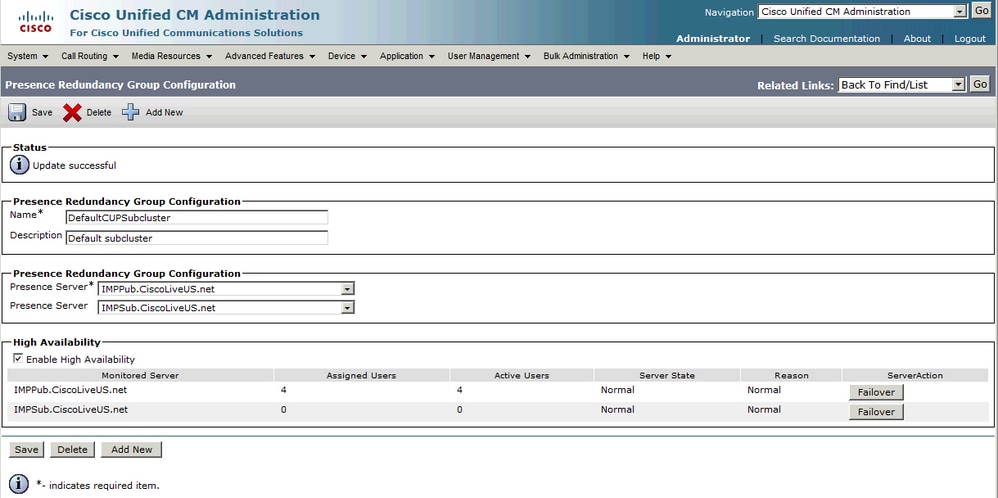
IM&PトポロジページのNormal-Normalハイアベイラビリティ状態:
監視対象IM and Presenceサービス
IMのみ、SIP/XMPPフェデレーションを使用したIM、コンプライアンスを使用したIM、常設チャットを使用したIM、リモートコール制御のみ、などのさまざまな展開モデルを使用できるため、監視するこれらのプロセスの実際のリストは動的です。デフォルトでは、HAが有効な場合、次の項目が常に監視されます。
- IDSデータベース
- プレゼンスエンジン(有効化されている場合)
- XCPルータ
Server Recovery Managerは、コンプライアンス(メッセージアーカイバ)、常設チャット(テキスト会議マネージャ)、SIPフェデレーション(SIPフェデレーション接続マネージャ)、XMPPフェデレーション(XMPPフェデレーション接続マネージャ)が構成されていてアクティブになっているかどうかを確認します。
これらのサービスが構成され、アクティブ化されている場合は、Server Recovery Manager(SRM)によってそれらのサービスも監視されます。
注意:1つ以上の監視対象サービスの再起動を開始する前に、CUCMサーバのプレゼンス冗長グループからハイアベイラビリティを無効にする必要があります。1つ以上のIM&Pノードのリブートが実行される場合も、同様です。
ユーザフェールオーバープロセス
フェールオーバーが発生した場合(自動または手動)、覚えておくべき重要な点は、ユーザアカウントが1つのサーバから他のサーバに移動するのではなく、Presence Engineのユーザセッションのみが移動されることです。10より前のバージョンのIM and Presenceでは、ユーザの割り当ては1台のサーバから別のサーバに移動されていました。 このユーザの移動は、サーバリソースにとって非常にコストがかかり、サーバの負荷が増大しました。 10.X以降では、ユーザは割り当てられたサーバでホームを維持し、プレゼンスエンジンのバックエンドユーザセッションは障害が発生したノードから機能ノードに移動します。 Server Recovery Manager(SRM)で変更が発生した場合、ユーザはJabberを終了して再度ログインする必要はありません。
Jabberクライアント再ログインタイマー
フェールオーバーイベント後にセカンダリIM&Pノードのユーザセッションが完全にアクティブになるには、ユーザはSOAP(Client Profile Agent)を使用してそのサーバへのログインを試行する必要があります。これは、IMDBデータベースから渡されるワンタイムパスワードで自動的に発生します。ログインはIM and Presenceサーバのリソースにとって非常に高価であるため、フェールオーバーイベントが発生したときにログインを抑制する方法が必要です。 このスロットルまたはバッファにより、すべてのユーザはセカンダリノードのユーザのサービスを中断することなく、セカンダリノードにログインできます。 ユーザログインを抑制するために使用されるメカニズムは、Client Re-Login Lower Limit(CRS)およびClient Re-Login Upper Limit Server Recovery Manager(SRM)サービスパラメータです。
Client Re-Login Lower Limit:HAイベントが発生した場合、クライアントがセカンダリサーバにログインを試みるまでにJabberクライアントが待機する最短時間(秒単位)を定義するパラメータ。
Client Re-Login Upper Limit:HAイベントが発生した場合、クライアントがセカンダリサーバにログインを試みるまでにJabberクライアントが待機する最大時間(秒単位)を定義するパラメータ。
Jabberクライアントは、サーバへのログイン時にこれらのパラメータを受信し、将来の使用に備えて値をキャッシュします。 IM&PサーバからHAイベントを受信すると、クライアントは上限と下限の間で秒数をランダムに選択し、その時間が経過するとJabberクライアントがセカンダリへのログインを試行します。 タイマーの期限が切れると、クライアントはセカンダリノードへのSOAPログインを試行します。
IM and Presenceフォールバックタイプ
ユーザのフェールオーバーが発生した場合、問題のあるサーバでサービスが復元されると、ユーザのフォールバックが発生します。 サーバフォールバックには2つのタイプがあります。
手動フォールバック
手動フォールバック(Server Recovery Managerの既定の構成)は、サービスが復元され、冗長グループで[フォールバック]ボタンが許可されたときに実行されます。このボタンを選択すると、セカンダリノードに移動されたユーザセッションがホームノードに戻ります。 その後、Jabberクライアントはフォールバックのログイン上限と下限を適用します。
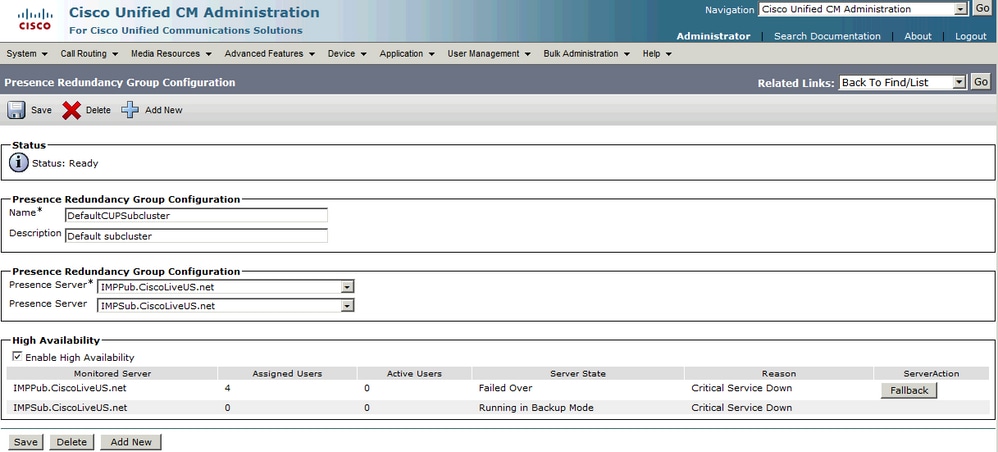
自動フォールバック
自動フォールバックは、サーバーがサービスを監視し、Server Recovery Manager (SRM)サービスがユーザーをホーム・ノードに自動的にフォールバックするときに実行されます。この構成で重要なのは、Server Recovery Manager(SRM)サービスが、障害が発生したサービス/サーバがアクティブ状態のまま30分間待機してから自動フォールバックを開始することです。 この30分の稼働時間が確立されると、ユーザセッションはホームノードに戻されます。その後、Jabberクライアントはフォールバックのログイン上限と下限を適用します。

注:自動フォールバックはデフォルト設定ではありませんが、有効にできます。 自動フォールバックを有効にするには、Server Recovery Managerサービスパラメーターの自動フォールバックを有効にするパラメーターの値をTrueに変更します。
トラブルシュート
ここでは、設定のトラブルシューティングに使用できる情報を示します。
IM&Pサービスサーバのハイアベイラビリティのトラブルシューティングを行う際には、考慮すべき重要なタイマーが2つあります。
- サーバは60秒ごとに4つのキープアライブを交換します。60秒経過しても応答がない場合、Cisco Service Recovery Manager(SRM)は応答していないノードがオフラインになったと見なし、フェールオーバーコマンドをトリガーします。次のスニペットが示すように、最後のハートビートは62秒前に発生しています。
2021-05-13 02:48:48,244 INFO[HS]rsrm.RsrmHeartBeatHandler - RsrmHeartBeatHandler: peer down, time since last heartbeat[s]= 62
2021-05-13 02:48:48,244 INFO [HS] rsrm.RsrmAutomaticFallback - RsrmAutomaticFallback: peer states vector changed to [Normal,Running in Backup Mode]
ヒント:このシナリオでは、ネットワークで多少の遅延が見つかった場合は、ハートビートタイムアウトタイマーを60秒から90秒に増やすことを推奨します。
CUCM Administration Webページ> System > Service parameters configuration > Select the IM&P Server> Select Cisco Recovery ManagerSettingsに移動します。キープアライブ(ハートビート)のタイムアウト時に、この値を90秒に増やします。
- IM&Pサブスクライバサーバは90秒間待機します。1つ以上の監視対象サービスがダウンしていることを検出すると、サブスクライバサーバが引き継ぎます。
トラブルシューティングのために収集するログ
- フェイルオーバーイベントの前後のServer Recover Manager(SRM)ログ(可能な場合はデバッグレベル)。
- IM&Pコマンドラインインターフェイス(CLI)を介したコマンドの出力で、sql select * from enterprisesubclusterを実行します。
- IM&Pのenterprisesubclusterテーブルには、冗長グループの設定が格納されています。
- IM&Pコマンドラインインターフェイス(CLI)を介したコマンドの出力で、sql select * from enterprisenodeを実行します。
- enterprisenode表には、ノードのノード情報とサブクラスタの割り当てが表示されます。
- 停止しているサービスによってフェールオーバーが発生している場合は、次の情報を収集します。
- イベントビューアのシステムログ
- イベントビューアアプリケーションログ
- 停止したサービスからのログ。
 フィードバック
フィードバック