Procédure de récupération pour la panne de batterie d'Ultra-M AutoVNF - vEPC
Options de téléchargement
-
ePub (356.8 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (277.9 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document décrit l'étape nécessaire pour récupérer ultra les services d'automatisation (UAS) ou la panne de batterie d'AutoVNF dans un Ultra-M installé qui héberge des fonctions réseau virtuelles de StarOS (VNFs).
Informations générales
Ultra-M est une solution mobile virtualisée préemballée et validée de noyau de paquet qui est conçue afin de simplifier le déploiement de VNFs.
La solution d'Ultra-M comprend les types mentoned du virtual machine (VM) :
- AUTOMATIQUE-service informatique
- Automatique-le déployez
- UAS ou AutoVNF
- Gestionnaire d'éléments (EM)
- L'élastique entretient le contrôleur (l'ESC)
- Fonction de contrôle (CF)
- Fonction de session (SF)
L'architecture de haut niveau d'Ultra-M et les composants impliqués sont dépeints dans cette image :
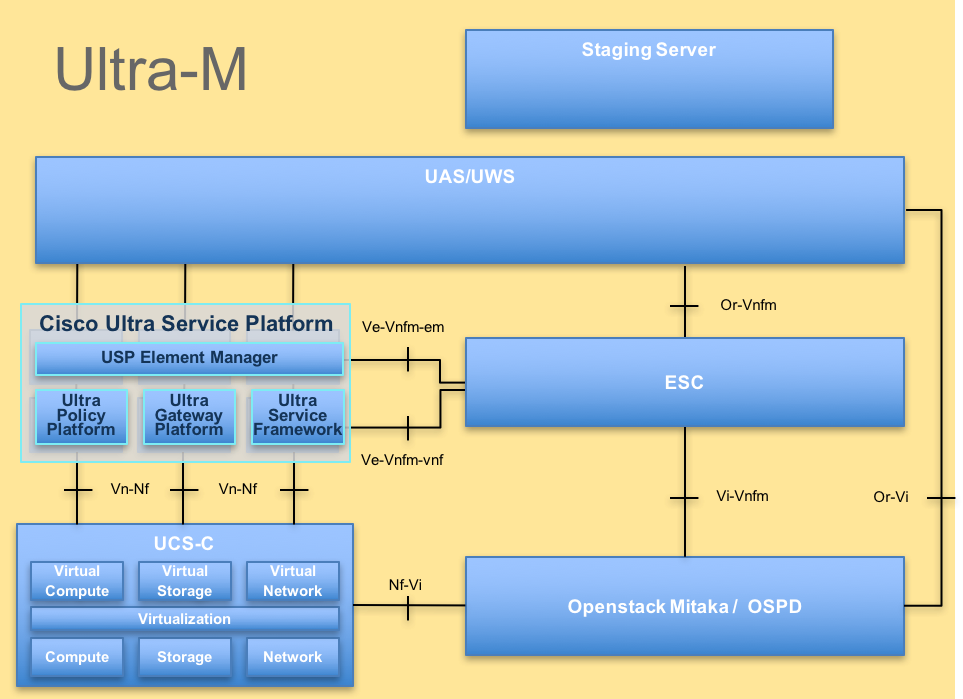 Architecture d'UltraM
Architecture d'UltraM
Ce document est destiné pour le personnel de Cisco qui sont au courant de la plate-forme de Cisco Ultra-M.
Remarque: Ultra la release M 5.1.x est considérée comme afin de définire les procédures dans ce document.
Abréviations
| VNF | Fonction réseau virtuelle |
| CF | Fonction de contrôle |
| SF | Fonction de service |
| ESC | Contrôleur élastique de service |
| BALAI | Méthode de procédure |
| OSD | Disques de mémoire d'objet |
| HDD | Lecteur de disque dur |
| Disque transistorisé | Lecteur semi-conducteur |
| SCORE | Gestionnaire virtuel d'infrastructure |
| VM | Virtual machine |
| EM | Gestionnaire d'éléments |
| UAS | Services d’automatisation ultra |
| UUID | Universellement identifiant unique |
Processus du balai
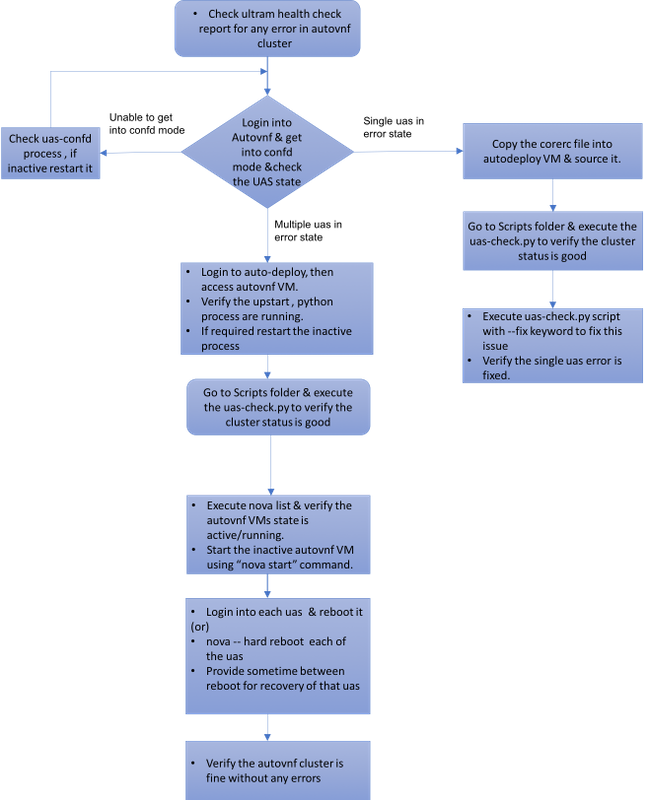
Reprise de l'affaire 1. de panne simple de batterie UAS
Contrôle d'état
1. Le gestionnaire d'Ultra-M exécute la vérification de l'intégrité du noeud d'Ultra-M. Naviguez vers le répertoire et le grep de /var/log/cisco/ultram-health/ d'états pour l'état UAS.
-
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. L'état prévu de la batterie UAS sera comme représenté, où tous les trois UAS sont actifs.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive NA
Manque de se connecter au serveur de Confd quand vous essayez de se connecter à UAS
1. Dans certains cas, vous ne pourrez pas se connecter au serveur de confd.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Failed to connect to server
2. Vérifiez le statut du processus d'uas-confd.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl status uas-confd
uas-confd stop/waiting
3. Si le serveur de confd ne fonctionne pas, redémarrez le service.
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl start uas-confd
uas-confd start/running, process 7970
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 172.16.180.9 using ssh on autovnf1-uas-0
Récupérez UAS d'état d'erreur
1. En cas de panne d'un AutoVNF parmi la batterie, la batterie UAS affiche un de l'UAS dans l'état d'erreur.
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive error
2. Copiez le fichier de corerc (fichier de rc de votre VNF) de /home/stack dans le serveur OSPD sur AutoDeploy et source il.
3. Vérifiez l'état de votre UAS/AutoVNF avec l'utilisation du script uas-check.py. autovnf1is le nom d'AutoVNF.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1
2017-11-17 14:52:20,186 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:22,172 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:22,172 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:22,172 - INFO: Check completed, AutoVNF cluster has recoverable errors
4. Récupérez l'UAS avec l'utilisation du script uas-check.py et ajoutez --mot clé de difficulté.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1 --fix
2017-11-17 14:52:27,493 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:29,215 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:29,215 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:29,215 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-17 14:52:29,386 - INFO: Creating instance 'autovnf1-uas-2' and attaching volume 'autovnf1-uas-vol-2'
2017-11-17 14:52:47,600 - INFO: Created instance 'autovnf1-uas-2'
5. Vous verrez que l'UAS de création récente est actif et une partie de la batterie.
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.13 alive NA
Affaire 2. Chacun des trois UAS (AutoVNF) est dans l'état d'erreur
1. Le gestionnaire d'Ultra-M exécute la vérification de l'intégrité du noeud d'Ultra-M.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA,Node: 172.16.180.9, Status: error, Role: NA,Node: 172.16.180.10, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. Comme observé dans la sortie, les signaler de gestionnaire d'Ultra-M qu'il y a une panne pour AutoVNF et lui prouve que tous les trois UAS de la batterie sont dans l'état d'erreur.
Vérifiez les santés UAS avec le script uas-check.py
1. Ouvrez une session au l'Automatique-déployer et vérifiez si vous pouvez accéder à l'AutoVNF UAS et obtenir l'état.
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts$ ./uas-check.py auto-vnf autovnf1 --os-tenant-name core
2017-12-05 11:41:09,834 - INFO: Check of AutoVNF cluster started
2017-12-05 11:41:11,342 - INFO: Found 3 ACTIVE AutoVNF instances
2017-12-05 11:41:11,343 - INFO: Check completed, AutoVNF cluster is fine
2. De Automatique-le déployez, Protocole Secure Shell (SSH) vers le noeud d'AutoVNF et entrez dans le mode de confd. Vérifiez l'état avec des uas d'exposition.
ubuntu@auto-deploy-iso-590-uas-0:~$ ssh ubuntu@172.16.180.9
password:
autovnf1-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
----------------------------
172.16.180.9 error NA
172.16.180.10 error NA
172.16.180.12 error NA
3. Il est recommandé pour vérifier l'état dans chacun des trois Noeuds UAS.
Vérifiez l'état des VMs au niveau d'OpenStack
Vérifiez l'état des VMs d'AutoVNF dans la liste de nova. S'il y a lieu, exécutez le début de nova afin de commencer la VM d'interruption.
[stack@pod1-ospd ultram-health]$ nova list | grep autovnf
| 83870eed-b4e9-47b3-976d-cc3eddecf866 | autovnf1-uas-0 | ACTIVE | - | Running | orchestr=172.16.180.12; mgmt=172.16.181.6
| 201d9ce5-538c-42f7-a46c-fc8cdef1eabf | autovnf1-uas-1 | ACTIVE | - | Running | orchestr=172.16.180.10; mgmt=172.16.181.5
| 6c6d25cd-21b6-42b9-87ff-286220faa2ff | autovnf1-uas-2 | ACTIVE | - | Running | orchestr=172.16.180.9; mgmt=172.16.181.13
Vérifiez la vue de Zookeeper
1. Vérifiez l'état de zookeeper afin de vérifier le mode comme leader.
ubuntu@autovnf1-uas-0:/var/log/upstart$ /opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
2. Zookeeper normalement devrait être.
Dépannez l'AutoVNF - Processus et tâches
1. Identifiez la raison pour l'état d'erreur des Noeuds. Pour qu'AutoVNF s'exécute, il y a un ensemble de processus qui doivent être en service comme affichés :
AutoVNF
uws-ae
uas-confd
cluster_manager
uas_manager
ubuntu@autovnf1-uas-0:~$ sudo initctl list | grep uas
uas-confd stop/waiting ====> this is not good, the uas-confd process is not running
uas_manager start/running, process 2143
root@autovnf1-uas-1:/home/ubuntu# sudo initctl list
....
uas-confd start/running, process 1780
....
autovnf start/running, process 1908
....
....
uws-ae start/running, process 1909
....
....
cluster_manager start/running, process 1827
....
.....
uas_manager start/running, process 1697
......
......
2. Vérifiez que ces processus de python s'exécutent :
uas_manager.py
cluster_manager.py
usp_autovnf.py
root@autovnf1-uas-1:/home/ubuntu# ps -aef | grep pyth
root 1819 1697 0 Jun13 ? 00:00:50 python /opt/cisco/usp/uas/manager/uas_manager.py
root 1858 1827 0 Jun13 ? 00:09:21 python /opt/cisco/usp/uas/manager/cluster_manager.py
root 1908 1 0 Jun13 ? 00:01:00 python /opt/cisco/usp/uas/autovnf/usp_autovnf.py
root 25662 24750 0 13:16 pts/7 00:00:00 grep --color=auto pyth
3. Si les processus prévus l'uns des ne sont pas dedans début/état courant, redémarrez le processus et vérifiez l'état. S'il affiche dans l'état d'erreur alors suit toujours la procédure mentionnée dans la section suivante afin de réparer cette question.
Difficulté pour le multiple UAS dans l'état d'erreur
1. nova --le <name dur de réinitialisation du VM> d'OSPD, donnent un certain temps pour la reprise de cette VM avant que vous poursuiviez au prochain UAS. Faites-le sur toutes les VMs UAS.
ou
2.Log dedans à chacune de la réinitialisation de sudo UAS et d'utilisation. Attendez la reprise et puis poursuivez à d'autres VMs UAS.
Pour des logs de transaction, contrôle :
/var/log/upstart/autovnf.log
show logs xxx | display xml
Ceci réparera la question et récupèrera l'UAS de l'état d'erreur.
1. Vérifiez la même chose avec l'utilisation de l'état d'ultram_health_check.
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | :-) |
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
Contribution d’experts de Cisco
- Partheeban RajagopalServices avancés de Cisco
- Padmaraj RamanoudjamServices avancés de Cisco
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)