Introduction
Ce document décrit l'étape nécessaire afin de remplacer chacun des deux disque dur défectueux dans le serveur dans un Ultra-M installé qui héberge des fonctions réseau virtuelles de StarOS (VNFs).
Ultra-M est une solution mobile virtualisée préemballée et validée de noyau de paquet conçue pour simplifier le déploiement de VNFs. OpenStack est le gestionnaire virtualisé d'infrastructure (SCORE) pour Ultra-M et se compose de ces types de noeud :
- Calcul
- Disque de mémoire d'objet - Calcul (OSD - Calcul)
- Contrôleur
- Plate-forme d'OpenStack - Directeur (OSPD)
L'architecture de haut niveau d'Ultra-M et les composants impliqués sont dépeints dans cette image :
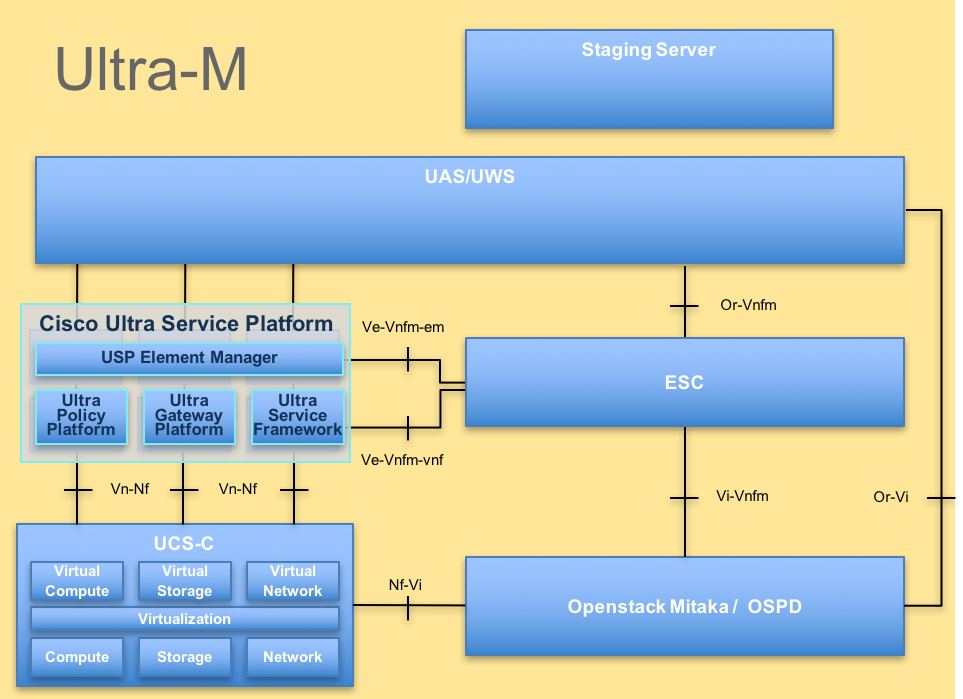 Architecture d'UltraM
Architecture d'UltraM
Ce document est destiné pour l'au courant de personnel de Cisco de la plate-forme de Cisco Ultra-M et il détaille l'étape nécessaire à effectuer au niveau d'OpenStack et de StarOS VNF au moment du remplacement de serveur de contrôleur.
Remarque: Ultra la release M 5.1.x est considérée comme afin de définire les procédures dans ce document.
Abréviations
| VNF |
Fonction réseau virtuelle |
| CF |
Fonction de contrôle |
| SF |
Fonction de service |
| ESC |
Contrôleur élastique de service |
| BALAI |
Méthode de procédure |
| OSD |
Disques de mémoire d'objet |
| HDD |
Lecteur de disque dur |
| Disque transistorisé |
Lecteur semi-conducteur |
| SCORE |
Gestionnaire virtuel d'infrastructure |
| VM |
Virtual machine |
| EM |
Gestionnaire d'éléments |
| UAS |
Services d’automatisation ultra |
| UUID |
Universellement identifiant unique |
Les deux panne de disque dur
Chaque serveur de nu-métal provisioned avec deux lecteurs HDD afin d'agir en tant que DISQUETTE DE DÉMARRAGE dans la configuration de l'incursion 1. En cas de panne simple HDD, puisqu'il y a Redondance de niveau de RAID 1, le HDD défectueux peut être troqué chaud. Cependant, quand chacun des deux l'échouer de disque dur, le serveur seront vers le bas et vous perdrez l'accès au serveur. Afin de restaurer l'accès au serveur et aux services, on l'exige pour remplacer le disque dur et pour ajouter le serveur à la pile de couvrir qui existe.
La procédure pour remplacer un composant défectueux sur le serveur UCS C240 M4 peut être référée de remplacer les composants de serveur.
En cas de chacun des deux la panne de disque dur, remplacent le disque dur seulement ces deux défectueux dans le même serveur UCS 240M4. La procédure de mise à jour du BIOS n'est pas exigée après que vous remplaciez de nouveaux disques.
Dans OpenStack a basé la solution d'Ultra-M, serveur de nu-métal UCS 240M4 peut prendre un de ces rôles : Calcul, OSD-calcul, contrôleur ou OSPD. L'étape nécessaire afin de manipuler les deux pannes HDD dans chacun de ces rôles de serveur sont mentionnées dans ces sections.
Remarque: Dans les scénarios où chacun des deux le disque dur sont sains mais un autre matériel est défectueux dans le serveur UCS 240M4, remplacent l'UCS 240M4 par le nouveau matériel, cependant, réutilisez le même disque dur. Dans ce cas, seulement le disque dur sont défectueux, ainsi réutilisez le même UCS 240M4 et remplacez le disque dur défectueux par le nouveau disque dur.
Les deux panne de disque dur sur le serveur de calcul
Si la panne de chacun des deux le disque dur est observée dans UCS 240M4 qui agit en tant que noeud de calcul, suivez la procédure de remplacement comme donné dans la procédure de remplacement de serveur de calcul.
Les deux panne de disque dur sur le serveur de contrôleur
Si la panne de chacun des deux le disque dur est observée dans UCS 240M4 qui agit en tant que noeud de contrôleur, suivez la procédure de remplacement comme donné dans.
Puisque le serveur de contrôleur qui observe chacun des deux la panne de disque dur sera non accessible par l'intermédiaire du Protocole Secure Shell (SSH), ouvrez une session dans un autre noeud de contrôleur afin d'exécuter la procédure gracieuse d'arrêt répertoriée dans le lien mentionné.
Les deux panne de disque dur sur le serveur d'OSD-calcul
Si la panne de chacun des deux le disque dur est observée dans UCS 240M4 qui agit en tant que noeud d'OSD-calcul, suivez la procédure de remplacement comme donné dans.
Dans la procédure mentionnée ici, l'arrêt gracieux de mémoire de Ceph ne peut pas être exécuté comme les deux pannes ont comme conséquence l'unreachability du serveur. , Ignorez par conséquent ces étapes.
Les deux panne de disque dur sur le serveur OSPD
Si la panne de chacun des deux le disque dur est observée dans UCS 240M4, qui agit en tant que noeud du Sn OSPD, suivez la procédure de remplacement comme donné dans.
Dans ce cas, la sauvegarde précédemment enregistrée OSPD est nécessaire pour la restauration après remplacement de disque HDD, d'autre il sera comme le redéploiement complet de pile.
 Commentaires
Commentaires