Cisco UCS B22 M3 Blade Server
The UCS B22 M3 blade server is a half-width blade with 12 DIMM slots; it supports one dedicated slot for Cisco's Virtual Interface Card (VIC) 1240, and one open adapter slot. You may install up to eight UCS B22 Blade Servers to a UCS chassis, or mix with other UCS blade servers. The Cisco UCS B22 M3 harnesses the power of the latest Intel Xeon processor E5-2400 product family with expandability to 192 GB of RAM (using 12 x 16 GB DIMMs), 2 hot-plug drives, and 2 PCIe adapter slots for up to 80 Gigabit Ethernet throughput.
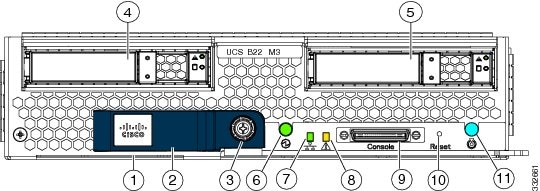
|
1 |
Asset tag Each server has a blank plastic asset tag that pulls out of the front panel, provided so you can add your own asset tracking label without interfering with the intended air flow. |
7 |
Network link status LED |
|
2 |
Blade ejector handle |
8 |
Blade health LED |
|
3 |
Ejector captive screw |
9 |
Console connector |
|
4 |
Hard drive bay 1 |
10 |
Reset button access |
|
5 |
Hard drive bay 2 |
11 |
Beaconing LED and button |
|
6 |
Power button and LED |
LEDs
Server LEDs indicate whether the blade server is in active or standby mode, the status of the network link, the overall health of the blade server, and whether the server is set to give a blinking blue locator light from the locator button.
The removable drives also have LEDs indicating hard disk access activity and disk health.
|
LED |
Color |
Description |
|
|---|---|---|---|
|
Power 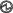 |
Off |
Power off. |
|
|
Green |
Main power state. Power is supplied to all server components and the server is operating normally. |
||
|
Amber |
Standby power state. Power is supplied only to the service processor of the server so that the server can still be managed.
|
||
|
Link  |
Off |
None of the network links are up. |
|
|
Green |
At least one network link is up. |
||
|
Health  |
Off |
Power off. |
|
|
Green |
Normal operation. |
||
|
Amber |
Minor error. |
||
|
Blinking Amber |
Critical error. |
||
|
Blue locator button and LED  |
Off |
Blinking is not enabled. |
|
|
Blinking blue 1 Hz |
Blinking to locate a selected blade—If the LED is not blinking, the blade is not selected. You can control the blinking in UCS Manager or by using the blue locator button/LED. |
||
|
Activity (Disk Drive)  |
Off |
Inactive. |
|
|
Green |
Outstanding I/O to disk drive. |
||
|
Health (Disk Drive) |
Off |
Can mean either no fault detected or the drive is not installed. |
|
|
Flashing Amber 4 hz |
Rebuild drive active. If the Activity LED is also flashing amber, a drive rebuild is in progress. |
||
|
Amber |
Fault detected. |
Buttons
The Reset button is recessed in the front panel of the server. You can press the button with the tip of a paper clip or a similar item. Hold the button down for five seconds, and then release it to restart the server if other methods of restarting do not work.
The locator function for an individual server may get turned on or off by pressing the locator button/LED.
The front-panel power button is disabled by default. It can re-enabled through Cisco UCS Manager. After it's enabled, The power button allows you to manually take a server temporarily out of service but leave it in a state where it can be restarted quickly. If the desired power state for a service profile associated with a blade server is set to "off," using the power button or Cisco UCS Manager to reset the server will cause the desired power state of the server to become out of sync with the actual power state and the server may unexpectedly shut down at a later time. To safely reboot a server from a power-down state, use the Boot Server action in Cisco UCS Manager.
Local Console Connection
The local console connector allows a direct connection to a blade server to allow operating system installation and other management tasks to be done directly rather than remotely. The port uses the KVM dongle cable that provides a connection into a Cisco UCS blade server; it has a DB9 serial connector, a VGA connector for a monitor, and dual USB ports for a keyboard and mouse. With this cable, you can create a direct connection to the operating system and the BIOS running on a blade server. A KVM cable ships standard with each blade chassis accessory kit.
|
1 |
Connector to blade server local console connection |
2 |
DB9 serial connector |
|
3 |
VGA connector for a monitor |
4 |
2-port USB connector for a mouse and keyboard |
Drive Replacement
Each blade has up to two front-accessible, hot-swappable, 2.5-inch drives. Unused hard drive bays should always be covered with cover plates to ensure proper cooling and ventilation.
You can remove and install hard drives without removing the blade server from the chassis.
The drives supported in this blade server come with the drive sled attached. Spare drive sleds are not available. A list of currently supported drives is in the specification sheets at this URL:http://www.cisco.com/c/en/us/products/servers-unified-computing/ucs-b-series-blade-servers/datasheet-listing.html
Before upgrading or adding a drive to a running blade server, check the service profile in Cisco UCS Manager and make sure the new hardware configuration will be within the parameters allowed by the service profile.
 Caution |
To prevent ESD damage, wear grounding wrist straps during these procedures. |
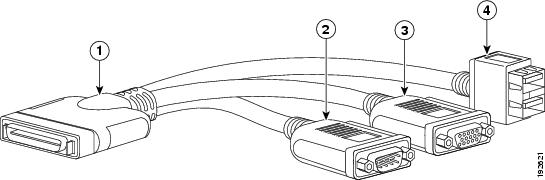
Removing a Blade Server Hard Drive
To remove a hard drive from a blade server, follow these steps:
SUMMARY STEPS
- Push the button to release the ejector, and then pull the hard drive from its slot.
- Place the hard drive on an antistatic mat or antistatic foam if you are not immediately reinstalling it in another server.
- Install a hard disk drive blank faceplate to keep dust out of the blade server if the slot will remain empty.
DETAILED STEPS
|
Step 1 |
Push the button to release the ejector, and then pull the hard drive from its slot.  |
|
Step 2 |
Place the hard drive on an antistatic mat or antistatic foam if you are not immediately reinstalling it in another server. |
|
Step 3 |
Install a hard disk drive blank faceplate to keep dust out of the blade server if the slot will remain empty. |
Basic Troubleshooting: Reseating a SAS/SATA Drive
Sometimes it is possible for a false positive UBAD error to occur on SAS/SATA HDDs installed in the server.
-
Only drives that are managed by the UCS MegaRAID controller are affected.
-
Drives can be affected regardless where they are installed in the server (front-loaded, rear-loaded, and so on).
-
Both SFF and LFF form factor drives can be affected.
-
Drives installed in all Cisco UCS C-Series servers with M3 processors and later can be affected.
-
Drives can be affected regardless of whether they are configured for hotplug or not.
-
The UBAD error is not always terminal, so the drive is not always defective or in need of repair or replacement. However, it is also possible that the error is terminal, and the drive will need replacement.
Before submitting the drive to the RMA process, it is a best practice to reseat the drive. If the false UBAD error exists, reseating the drive can clear it. If successful, reseating the drive reduces inconvenience, cost, and service interruption, and optimizes your server uptime.
 Note |
Reseat the drive only if a UBAD error occurs. Other errors are transient, and you should not attempt diagnostics and troubleshooting without the assistance of Cisco personnel. Contact Cisco TAC for assistance with other drive errors. |
To reseat the drive, see Reseating a SAS/SATA Drive.
Reseating a SAS/SATA Drive
Sometimes, SAS/SATA drives can throw a false UBAD error, and reseating the drive can clear the error.
Use the following procedure to reseat the drive.
Caution |
This procedure might require powering down the server. Powering down the server will cause a service interruption. |
Before you begin
Before attempting this procedure, be aware of the following:
-
Before reseating the drive, it is a best practice to back up any data on it.
-
When reseating the drive, make sure to reuse the same drive bay.
-
Do not move the drive to a different slot.
-
Do not move the drive to a different server.
-
If you do not reuse the same slot, the Cisco management software (for example, Cisco IMM) might require a rescan/rediscovery of the server.
-
-
When reseating the drive, allow 20 seconds between removal and reinsertion.
Procedure
|
Step 1 |
Attempt a hot reseat of the affected drive(s). Choose the appropriate option.
|
||
|
Step 2 |
During boot up, watch the drive's LEDs to verify correct operation. |
||
|
Step 3 |
If the error persists, cold reseat the drive, which requires a server power down. Choose the appropriate option: |
||
|
Step 4 |
If hot and cold reseating the drive (if necessary) does not clear the UBAD error, choose the appropriate option:
|
Installing a Blade Server Drive
To install a drive in a blade server, follow these steps:
SUMMARY STEPS
- Place the drive ejector into the open position by pushing the release button.
- Gently slide the drive into the opening in the blade server until it seats into place.
- Push the drive ejector into the closed position.
DETAILED STEPS
|
Step 1 |
Place the drive ejector into the open position by pushing the release button. 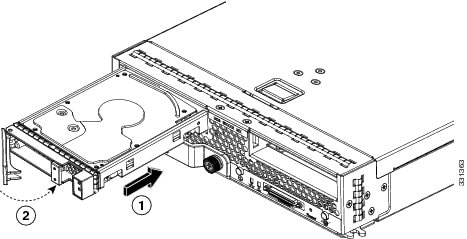 |
|
Step 2 |
Gently slide the drive into the opening in the blade server until it seats into place. |
|
Step 3 |
Push the drive ejector into the closed position. You can use Cisco UCS Manager to format and configure RAID services. For details, see the Configuration Guide for the version of Cisco UCS Manager that you are using. The configuration guides are available at the following URL: http://www.cisco.com/en/US/products/ps10281/products_installation_and_configuration_guides_list.html If you need to move a RAID cluster, see the Cisco UCS Manager Troubleshooting Reference Guide. |
Blade Server Removal and Installation
Before performing any internal operations on this blade server, you must remove it from the chassis.
Caution |
To prevent ESD damage, wear grounding wrist straps during these procedures and handle modules by the carrier edges only. |
Powering Off a Blade Server Using the Power Button
Note |
The front panel power button is disabled by default to ensure that servers are decommissioned through the UCS management software interface before shutdown. If you prefer to shut down the server locally with the button, you can enable front power-button control in the UCS management software interface. |
 Tip |
You can also shut down servers remotely using the UCS management software interface. For details, see the configuration guide for the version the UCS management software interface that you are using. The configuration guides are available at the URLs documented in Server Configuration. |
Procedure
|
Step 1 |
If you are local to the server, check the color of the Power Status LED for each server in the chassis that you want to power off.
|
||
|
Step 2 |
If you previously enabled front power-button control through the UCS management software interface, press and release the Power button, then wait until the Power Status LED changes to amber. The operating system performs a graceful shutdown, and the server goes to standby mode.
|
||
|
Step 3 |
(Optional) Although not recommended, if you are shutting down all blade servers in a chassis, you can disconnect the power cords from the chassis to completely power off the servers.
|
Removing a Blade Server
Using the UCS management software interface, decommission the server before physically removing the server. To remove a blade server from the chassis, follow these steps:
SUMMARY STEPS
- Loosen the captive screw on the front of the blade.
- Remove the blade from the chassis by pulling the ejector lever on the blade until it unseats the blade server.
- Slide the blade partially out of the chassis and place your other hand under the blade to support its weight.
- Once completely removed, place the blade on an antistatic mat or antistatic foam if you are not immediately reinstalling it into another slot.
- If the slot is to remain empty, install a blank faceplate (N20-CBLKB1) to maintain proper thermal temperature and keep dust out of the chassis.
DETAILED STEPS
|
Step 1 |
Loosen the captive screw on the front of the blade. |
|
Step 2 |
Remove the blade from the chassis by pulling the ejector lever on the blade until it unseats the blade server. |
|
Step 3 |
Slide the blade partially out of the chassis and place your other hand under the blade to support its weight. |
|
Step 4 |
Once completely removed, place the blade on an antistatic mat or antistatic foam if you are not immediately reinstalling it into another slot. |
|
Step 5 |
If the slot is to remain empty, install a blank faceplate (N20-CBLKB1) to maintain proper thermal temperature and keep dust out of the chassis. |
Installing a Half-width Blade Server
Before you begin
The blade server must have its cover installed before installing the server into the chassis to ensure adequate airflow.
SUMMARY STEPS
- Grasp the front of the blade server and place your other hand under the blade to support it.
- Open the ejector lever in the front of the blade server.
- Gently slide the blade into the opening until you cannot push it any farther.
- Press the ejector so that it catches the edge of the chassis and presses the blade server all the way in.
- Tighten the captive screw on the front of the blade to no more than 3 in-lbs. Tightening only with bare fingers is unlikely to lead to stripped or damaged captive screws.
DETAILED STEPS
|
Step 1 |
Grasp the front of the blade server and place your other hand under the blade to support it. 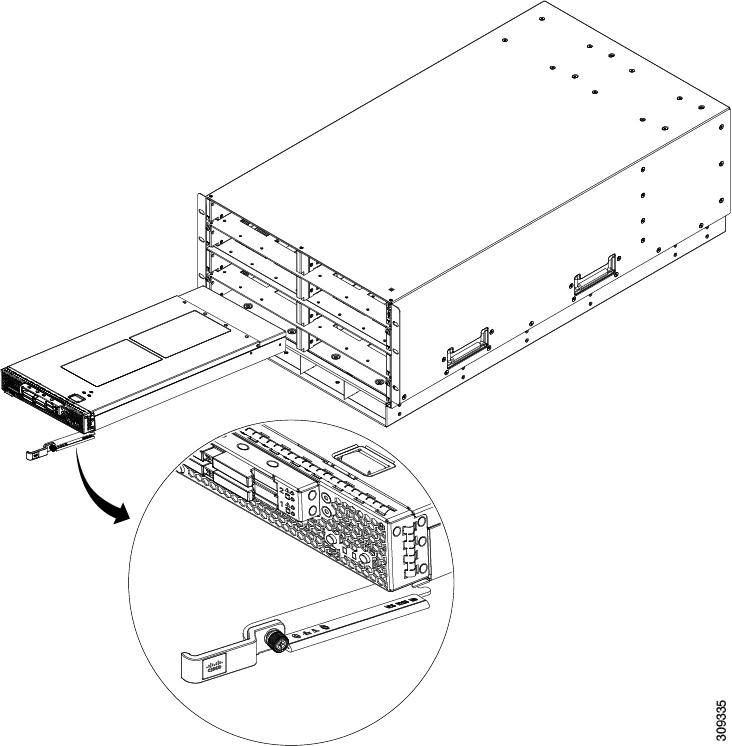
|
|
Step 2 |
Open the ejector lever in the front of the blade server. |
|
Step 3 |
Gently slide the blade into the opening until you cannot push it any farther. |
|
Step 4 |
Press the ejector so that it catches the edge of the chassis and presses the blade server all the way in. |
|
Step 5 |
Tighten the captive screw on the front of the blade to no more than 3 in-lbs. Tightening only with bare fingers is unlikely to lead to stripped or damaged captive screws. Assuming the server chassis is already discovered by UCS Manager, the blade will be auto discovered whenever it is inserted. |
Secure Digital Cards
Secure Digital (SD) card slots are provided and one or two SD cards can be populated. If two SD cards are populated, they can be used in a mirrored mode.
Note |
Do not mix different capacity cards in the same server. |
Note |
Due to technical limitations, if the server is running a Cisco UCS Manager version earlier than release 2.2(3a) with the 32-GB SD card, only 16-GB usable capacity is available (regardless of mirroring) in the server. |

Removing a Blade Server Cover
SUMMARY STEPS
- Press and hold the button down as shown in the figure below.
- While holding the back end of the cover, pull the cover back and then up.
DETAILED STEPS
|
Step 1 |
Press and hold the button down as shown in the figure below. |
|
Step 2 |
While holding the back end of the cover, pull the cover back and then up. 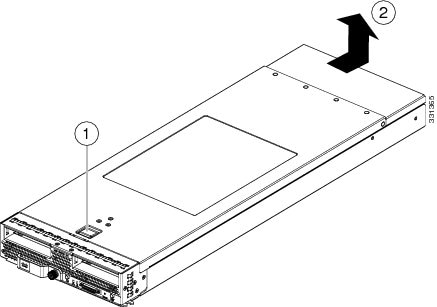 |
Air Baffles
The air baffles (UCSB-BAFF-B22-M3=) shown ship with this server, as they direct and improve air flow for the server components. No tools are necessary to install them, just place them over the DIMMs as shown, aligned to the standoffs.
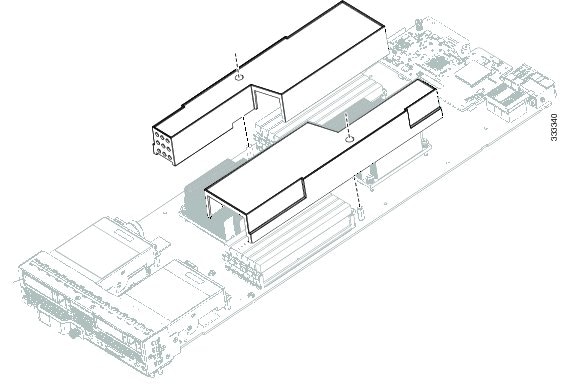
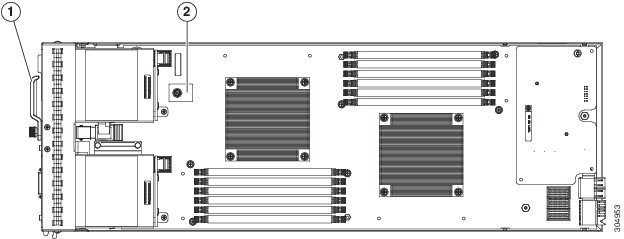
Internal Components
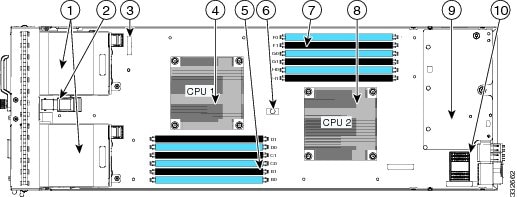
|
1 |
Hard drive bays |
2 |
Internal USB connector Cisco UCS-USBFLSH-S-4GB= is recommended, but if another USB drive will be used it must be no wider than .8 inches, and no more than 1.345 inches long in order to provide needed clearances to install or remove the USB drive. |
|
3 |
Battery |
4 |
CPU 1 and heat sink |
|
5 |
DIMM slots |
6 |
Diagnostic button |
|
7 |
DIMM slots |
8 |
CPU 2 and heat sink |
|
9 |
Modular LOM (shown installed) |
10 |
Adapter card connector (Adapter not shown installed) |
Note |
Use of this server may require an upgrade to the IOM in the chassis. This server only supports third generation adapter cards, which have features requiring a Cisco 2204 or 2208 IOM, and are not backward compatible with the Cisco 2104 IOM. |
Diagnostics Button and LEDs
At blade start-up, POST diagnostics test the CPUs, DIMMs, HDDs, and rear mezzanine modules, and any failure notifications are sent to Cisco UCS Manager. You can view these notifications in the Cisco UCS Manager System Error Log or in the output of the show tech-support command. If errors are found, an amber diagnostic LED also lights up next to the failed component. During run time, the blade BIOS and component drivers monitor for hardware faults and will light up the amber diagnostic LED as needed.
LED states are saved, and if you remove the blade from the chassis the LED values will persist for up to 10 minutes. Pressing the LED diagnostics button on the motherboard causes the LEDs that currently show a component fault to light for up to 30 seconds for easier component identification. LED fault values are reset when the blade is reinserted into the chassis and booted, and the process begins from its start.
If DIMM insertion errors are detected, they may cause the blade discovery process to fail and errors will be reported in the server POST information, which is viewable using the UCS Manager GUI or CLI. DIMMs must be populated according to specific rules. The rules depend on the blade server model. Refer to the documentation for a specific blade server for those rules.
Faults on the DIMMs or rear mezzanine modules also cause the server health LED to light solid amber for minor error conditions or blinking amber for critical error conditions.
Working Inside the Blade Server
Installing a CMOS Battery
All Cisco UCS blade servers use a CR2032 battery to preserve BIOS settings while the server is not installed in a powered-on chassis. Cisco supports the industry standard CR2032 battery that is available at most electronics stores.
 Warning |
There is danger of explosion if the battery is replaced incorrectly. Replace the battery only with the same or equivalent type recommended by the manufacturer. Dispose of used batteries according to the manufacturer’s instructions. |
To install or replace the battery, follow these steps:
SUMMARY STEPS
- Remove the existing battery:
- Install the replacement battery:
DETAILED STEPS
|
Step 1 |
Remove the existing battery:
|
|
Step 2 |
Install the replacement battery: |
CPU Replacement
You can order your blade server with two CPUs, or upgrade later to a second CPU. Both CPUs must be of the same type, and memory in slots intended for the second CPU will not be recognized if the second CPU is not present. You may need to use these procedures to move a CPU from one server to another, or to replace a faulty CPU.
The CPUs supported in this blade server are constantly being updated. A list of currently supported and available CPUs is in the specification sheets at this URL:
http://www.cisco.com/c/en/us/support/servers-unified-computing/ucs-b200-m3-blade-server/model.html#DataSheetsRemoving a CPU and Heat Sink
Caution |
The CPU pick and place tool is required to prevent damage to the connection pins between the motherboard and the CPU. Do not attempt this procedure without the required tool, which is included with each CPU option kit. |
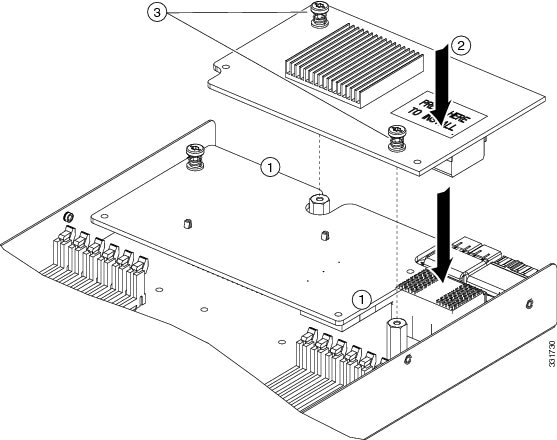
SUMMARY STEPS
- Unscrew the four captive screws securing the heat sink to the motherboard. See callout 1.
- Remove the heat sink (UCSB-HS-01-EP). See callout 2 in the following figure.
- Unhook the socket hook. See callout 3 in the following figure.
- Open the socket latch. See callout 4 in the following figure.
- Place the CPU and tool on the CPU socket with the registration marks aligned as shown.
- Remove an old CPU as follows:
DETAILED STEPS
|
Step 1 |
Unscrew the four captive screws securing the heat sink to the motherboard. See callout 1. Loosen one screw by a quarter turn, then move to the next in an X pattern. Continue loosening until the heat sink can be lifted off. |
||||
|
Step 2 |
Remove the heat sink (UCSB-HS-01-EP). See callout 2 in the following figure. Remove the existing thermal compound from the bottom of the heat sink using the cleaning kit (UCSX-HSCK= ) included with each CPU option kit. Follow the instructions on the two bottles of cleaning solvent. |
||||
|
Step 3 |
Unhook the socket hook. See callout 3 in the following figure. |
||||
|
Step 4 |
Open the socket latch. See callout 4 in the following figure. 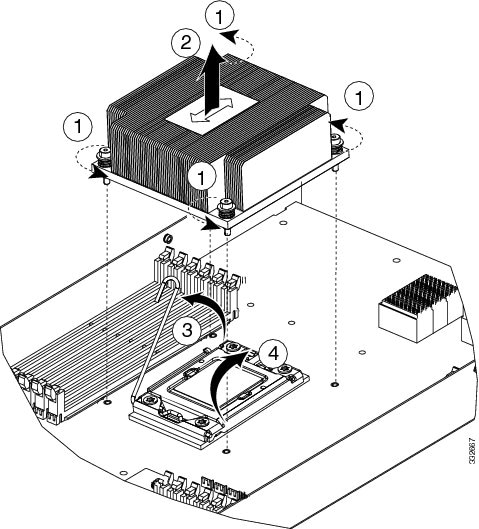 |
||||
|
Step 5 |
Place the CPU and tool on the CPU socket with the registration marks aligned as shown. The CPU pick and place tool is included with each CPU option kit, or the tool may be purchased separately. Be sure to use the tool for the Intel Xeon E5-2400 Series processors. |
||||
|
Step 6 |
Remove an old CPU as follows:
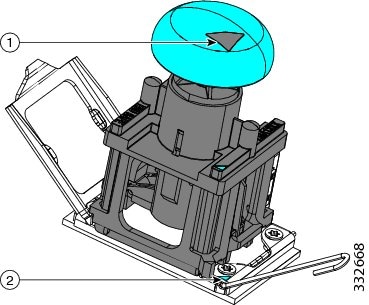
|
Installing a New CPU and Heat Sink
Before installing a new CPU in a server, verify the following:
-
The CPU is supported for that given server model. This may be verified via the server's Technical Specifications ordering guides or by the relevant release of the Cisco UCS Capability Catalog.
-
A BIOS update is available and installed that supports the CPU and the given server configuration.
-
If the server will be managed by Cisco UCS Manager, the service profile for this server in UCS Manager will recognize and allow the new CPU.
SUMMARY STEPS
- (Optional) If you are installing a CPU in a socket that had been shipped empty, there will be a protective cap intended to prevent bent or touched contact pins. The pick and pull cap tool provided can be used in a manner similar to a pair of tweezers. Grasp the protective cap and pivot as shown.
- Release the catch on the pick and place tool by pressing the button/handle.
- Remove the new CPU from the packaging, and load it into the pick and place tool as follows:
- Place the CPU and tool on the CPU socket with the registration marks aligned as shown.
- Press the button on the pick and place tool to release the CPU into the socket.
- Close the socket latch. See callout 1.
- Secure the hook. See callout 2.
- Using the syringe of thermal grease provided with replacement CPUs and servers (and available separately as UCS-CPU-GREASE=), add 2 cubic centimeters of thermal grease to the top of the CPU where it will contact the heat sink. Use the pattern shown below. This should require half the contents of the syringe.
- Replace the heat sink. See callout 3.
- Secure the heat sink to the motherboard by tightening the four captive screws a quarter turn at a time in an X pattern as shown in the upper right of the figure.
DETAILED STEPS
|
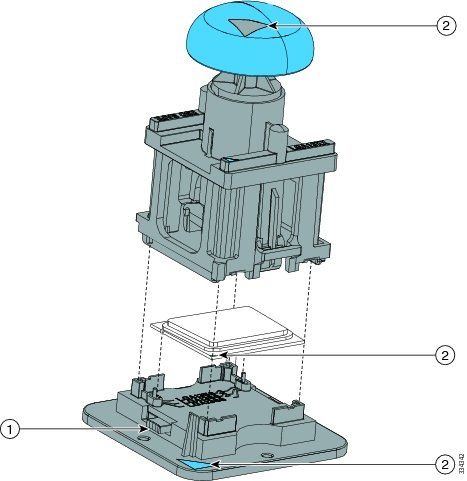
Step 1 |
(Optional) If you are installing a CPU in a socket that had been shipped empty, there will be a protective cap intended to prevent bent or touched contact pins. The pick and pull cap tool provided can be used in a manner similar to a pair of tweezers. Grasp the protective cap and pivot as shown. 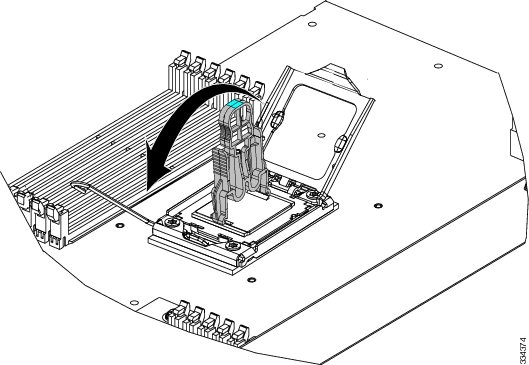 |
||||
|
Step 2 |
Release the catch on the pick and place tool by pressing the button/handle. |
||||
|
Step 3 |
Remove the new CPU from the packaging, and load it into the pick and place tool as follows:
|
||||
|
Step 4 |
Place the CPU and tool on the CPU socket with the registration marks aligned as shown. |
||||
|
Step 5 |
Press the button on the pick and place tool to release the CPU into the socket. 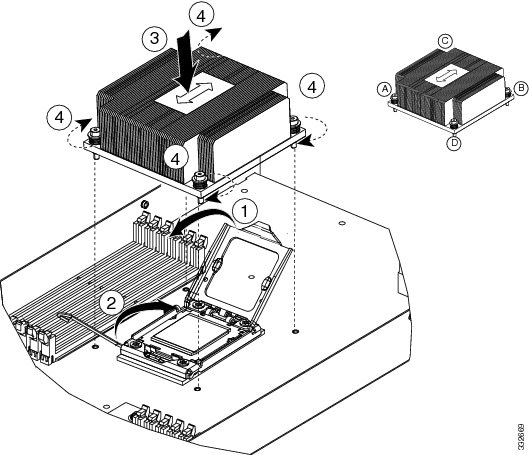 |
||||
|
Step 6 |
Close the socket latch. See callout 1. |
||||
|
Step 7 |
Secure the hook. See callout 2. |
||||
|
Step 8 |
Using the syringe of thermal grease provided with replacement CPUs and servers (and available separately as UCS-CPU-GREASE=), add 2 cubic centimeters of thermal grease to the top of the CPU where it will contact the heat sink. Use the pattern shown below. This should require half the contents of the syringe. 
|
||||
|
Step 9 |
Replace the heat sink. See callout 3.
|
||||
|
Step 10 |
Secure the heat sink to the motherboard by tightening the four captive screws a quarter turn at a time in an X pattern as shown in the upper right of the figure. |
Installing Memory
To install a DIMM into the blade server, follow these steps:
SUMMARY STEPS
- Press the DIMM into its slot evenly on both ends until it clicks into place.
- Press the DIMM connector latches inward slightly to seat them fully.
DETAILED STEPS
|
Step 1 |
Press the DIMM into its slot evenly on both ends until it clicks into place. DIMMs are keyed. If a gentle force is not sufficient, make sure the notch on the DIMM is correctly aligned.
|
||
|
Step 2 |
Press the DIMM connector latches inward slightly to seat them fully. |
Supported DIMMs
The DIMMs supported in this blade server are constantly being updated. A list of currently supported and available DIMMs is in the specification sheets at:
http://www.cisco.com/en/US/products/ps10280/products_data_sheets_list.htmlDo not use any memory DIMMs other than those listed in the specification sheet. Doing so may irreparably damage the server and require down time.
Low-Voltage DIMM Considerations
The server can be ordered with low-voltage (1.35 V) DIMMs or mixed-voltage (1.35V/1.5 V) DIMMs.
There is a setting in the BIOS Setup utility that you can use to change the DDR memory mode when the server has all low-voltage DIMMs installed. To access this setting, follow these steps:
SUMMARY STEPS
- Enter the BIOS setup utility by pressing the F2 key when prompted during bootup.
- Select the Advanced tab.
- Select Low Voltage DDR Mode.
- In the pop-up window, select either Power Saving Mode or Performance Mode.
- Press F10 to save your changes and exit the setup utility, or you can exit without saving changes by pressing Esc.
DETAILED STEPS
|
Step 1 |
Enter the BIOS setup utility by pressing the F2 key when prompted during bootup. |
|
Step 2 |
Select the Advanced tab. |
|
Step 3 |
Select Low Voltage DDR Mode. |
|
Step 4 |
In the pop-up window, select either Power Saving Mode or Performance Mode.
|
|
Step 5 |
Press F10 to save your changes and exit the setup utility, or you can exit without saving changes by pressing Esc. |
Memory Arrangement
Keep in mind the following rules when adding DIMMs to this server:
-
Only use Cisco-provided DIMMs.
-
Mixing different speed DIMMs causes the server to set the memory speed to that of the slowest installed DIMMs.
-
If memory mirroring is used, the total memory capacity is reduced by 50%.
-
CPU1 and CPU2 (if used) must always be configured identically.
The blade server contains 12 DIMM slots—six for each CPU. Each set of six DIMM slots is arranged into three channels, where each channel has 2 DIMMs.
Each channel is identified by a letter—B, C, D for CPU1, and F, G, H for CPU 2. Each DIMM slot is identified by a number, either 0 or 1. Note that each DIMM slot 0 is blue, while each slot 1 is black.
The following figure shows how DIMMs and channels are physically laid out on the blade server. The DIMM slots in the upper right are associated with CPU 2, while the DIMM slots in the lower left are associated with CPU 1.
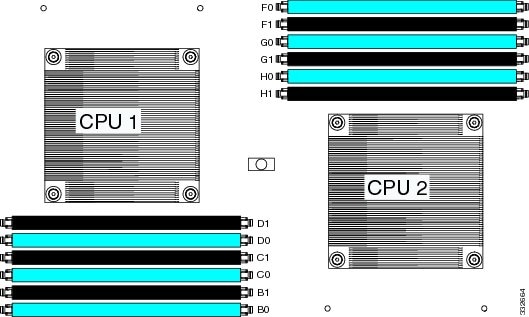
Note |
The memory in the upper right cannot communicate with the memory in lower left, unless both CPUs are present. |
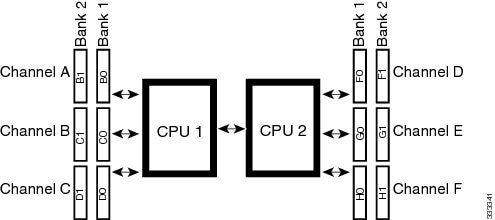
DIMMs can be used in the blade server in either a one DIMM per Channel (1DPC) configuration or in a two DIMMs per Channel (2DPC) configuration.
Each CPU in a Cisco UCS B22 blade server supports 3 channels of 2 memory slots each. In a 1 DPC configuration, DIMMs are in slot 0 only. In a 2 DPC configuration, DIMMs are in both slot 0 and slot 1. The table below shows the preferred order for installing upgrade DIMMs, and while other configurations may work if problems arise moving them to the preferred arrangement should help.
|
DIMMs per CPU |
CPU 1 installed slots |
CPU 2 installed slots |
|---|---|---|
|
1 |
B0 |
F0 |
|
2 |
B0, C0 |
F0, G0 |
|
3 |
B0, C0, D0 |
F0, G0, H0 |
|
4 |
B0, C0, D0, B1 |
F0, G0, H0, F1 |
|
5 |
B0, C0, D0, B1, C1 |
F0, G0, H0, F1, G1 |
|
6 |
B0, C0, D0, B1, C1, D1 |
F0, G0, H0, F1, G1, H1 |
Memory Performance
When considering the memory configuration of your blade server, there are several things you need to consider. For example:
-
DIMMs within the blade server should be configured in complete banks for optimal performance.
-
Your selected CPU(s) can have some affect on performance.
Bandwidth and Performance
Recommendations for achieving performance of 1600 MHz on B22 M3 servers:
-
Ensure that both the installed CPU and the selected DIMMs support operation at 1600 MHz. If either cannot support this, the pair will run at the highest speeed of the slower of the two.
-
Ensure the server is running the 2.0(2) or later BIOS version. If a BIOS upgrade is needed, do it before installing processors or memory.
-
Use only Cisco certified DIMMs that support 1600 MHz speeds. DIMMs do not have to be identical in type or capacity, but beware of the caveats listed in the section below regarding performance degradation.
-
Always set the system BIOS to operate the DIMMs in "Performance" mode in order to run at 1600 MHz.
-
Fully populating 1 logical bank or 2 logical banks with DIMMs will ensure optimal memory bandwidth running at the 1600 MHz speed. If DIMMs are partially populated in 1 bank (less than 6 DIMMs) or 2 bank patterns (less than 12 but greater than 6 DIMMs) the 1600 MHz speed can be used, but the overall memory bandwidth will not be optimal.
Performance Degradation
Performance degradation can occur if the following memory configurations are used:
-
Mixing DIMM sizes and densities within a channel
-
Partially populating a channel
-
Unevenly populating DIMMs between CPUs
Memory Mirroring and RAS
The Intel CPUs within the blade server support memory mirroring only when no more than two Channels are populated with DIMMs. If three Channels are populated with DIMMs, memory mirroring is automatically disabled. Furthermore, if memory mirroring is used, DRAM size is reduced by 50% for reasons of reliability.
If the RAS (Reliability, Availability, and Serviceability) option is required, it is available only when Channel–3 is not populated.
Installing a Virtual Interface Card Adapter
Note |
You must remove the adapter card to service it. |
To install a Cisco VIC 1340 or VIC 1240 in the blade server, follow these steps:
SUMMARY STEPS
- Position the VIC board connector above the motherboard connector and align the captive screw to the standoff post on the motherboard.
- Firmly press the VIC board connector into the motherboard connector.
- Tighten the captive screw.
DETAILED STEPS
|
Step 1 |
Position the VIC board connector above the motherboard connector and align the captive screw to the standoff post on the motherboard. |
||
|
Step 2 |
Firmly press the VIC board connector into the motherboard connector. |
||
|
Step 3 |
Tighten the captive screw.
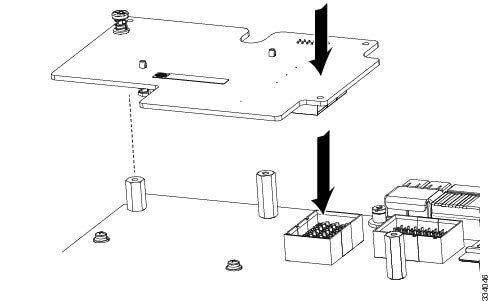 |
Installing an Adapter Card
All the supported mezzanine cards have a common installation process. These cards are updated frequently. Currently supported cards and the available models for this server are listed in the specification sheets at this URL: http://www.cisco.com/c/en/us/products/servers-unified-computing/ucs-b-series-blade-servers/datasheet-listing.html
If you are switching from one type of adapter card to another, before you physically perform the switch make sure that you download the latest device drivers and load them into the server’s operating system. For more information, see the firmware management chapter of one of the Cisco UCS Manager software configuration guides.
SUMMARY STEPS
- Position the adapter board connector above the motherboard connector and align the two adapter captive screws to the standoff posts (see callout 1) on the motherboard.
- Firmly press the adapter connector into the motherboard connector (see callout 2).
- Tighten the two captive screws (see callout 3).
DETAILED STEPS
|
Step 1 |
Position the adapter board connector above the motherboard connector and align the two adapter captive screws to the standoff posts (see callout 1) on the motherboard. |
||
|
Step 2 |
Firmly press the adapter connector into the motherboard connector (see callout 2). |
||
|
Step 3 |
Tighten the two captive screws (see callout 3).
 |
Installing and Enabling a Trusted Platform Module
The Trusted Platform Module (TPM) is a component that can securely store artifacts used to authenticate the server. These artifacts can include passwords, certificates, or encryption keys. A TPM can also be used to store platform measurements that help ensure that the platform remains trustworthy. Authentication (ensuring that the platform can prove that it is what it claims to be) and attestation (a process helping to prove that a platform is trustworthy and has not been breached) are necessary steps to ensure safer computing in all environments. It is a requirement for the Intel Trusted Execution Technology (TXT) security feature, which must be enabled in the BIOS settings for a server equipped with a TPM.
Note |
TPM installation is supported after-factory. However, a TPM installs with a one-way screw and cannot be replaced or moved to another server. If a server with a TPM is returned, the replacement server must be ordered with a new TPM. |
SUMMARY STEPS
- Install the TPM hardware.
- Enable TPM Support in the BIOS.
- Enable TPM State in the BIOS.
- Verify that TPM Support and TPM State are enabled.
- Enable the Intel TXT feature in the BIOS.
DETAILED STEPS
|
Step 1 |
Install the TPM hardware.
|
||||
|
Step 2 |
Enable TPM Support in the BIOS. |
||||
|
Step 3 |
Enable TPM State in the BIOS.
|
||||
|
Step 4 |
Verify that TPM Support and TPM State are enabled.
|
||||
|
Step 5 |
Enable the Intel TXT feature in the BIOS. |
Server Troubleshooting
For general troubleshooting information, see the Cisco UCS Manager Troubleshooting Reference Guide.
Server Configuration
Cisco Intersight Managed Mode
Cisco UCS blade servers can be configured and managed using the Cisco Intersight management platform in Intersight Managed Mode (Cisco Intersight Managed Mode). For details, see the Cisco Intersight Managed Mode Configuration Guide, which is available at the following URL: https://www.cisco.com/c/en/us/td/docs/unified_computing/Intersight/b_Intersight_Managed_Mode_Configuration_Guide.html
Cisco UCS Manager
Cisco UCS blade servers can be configured and managed using Cisco UCS Manager. For details, see the Configuration Guide for the version of Cisco UCS Manager that you are using. The configuration guides are available at the following URL: http://www.cisco.com/en/US/products/ps10281/products_installation_and_configuration_guides_list.html
Physical Specifications for the Cisco UCS B22 M3
|
Specification |
Value |
|---|---|
|
Height |
1.95 inches (50 mm) |
|
Width |
8.00 inches (203 mm) |
|
Depth |
24.4 inches (620 mm) |
|
Weight |
13.5 lbs (6.1 kg) The system weight listed here is an estimate for a fully configured system and will vary depending on peripheral devices installed. |
Obtaining Documentation and Submitting a Service Request
For information on obtaining documentation, submitting a service request, and gathering additional information, see the monthly What's New in Cisco Product Documentation, which also lists all new and revised Cisco technical documentation.
Subscribe to the What's New in Cisco Product Documentation as a Really Simple Syndication (RSS) feed and set content to be delivered directly to your desktop using a reader application. The RSS feeds are a free service and Cisco currently supports RSS version 2.0.
Follow Cisco UCS Docs on Twitter to receive document update notifications.
 Feedback
Feedback