Keep your data, workloads, and apps connected and secure for exceptional efficiency across your global on-premises and cloud data center infrastructure with data center networking.
Unify experiences across all data center networks
Choose the best operational experience for the job, every time, with secure on-premises and multicloud networking. Configure with ease, operate with confidence, and analyze for predictability from one simple location.
Review, react, relax
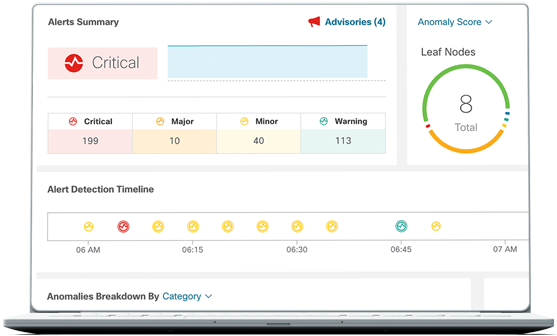
Make it easier than ever to assess the situation, deliver a solution, and get to what's next because of increased visibility, clever automation, and rapid troubleshooting.
Work sustainably
Embrace smart-energy data center networking with visibility into actual usage of power and carbon footprint and enjoy the benefits of being at the forefront of the net-zero journey.
AI/ML blueprint for networking
Boost cost efficiencies and performance with design best-practices and automation templates for AI data center networking.